
AI
JetBrains Opens Mellum2 to Cut Coding Agent Call Costs
JetBrains Mellum2 is a 12B MoE model that activates 2.5B parameters per token. It adds a private coding model option for IDE and agent workflows.
AI
JetBrains Mellum2 is a 12B MoE model that activates 2.5B parameters per token. It adds a private coding model option for IDE and agent workflows.

AI
NVIDIA introduced Nemotron 3 Ultra alongside NemoClaw, OpenShell, and CUDA-X agent skills, pushing open agent competition into the runtime layer.

AI
OpenAI GPT-5.5, GPT-5.4, and Codex are generally available on Amazon Bedrock, shifting authentication, billing, and feature boundaries into AWS.

AI
NVIDIA Alpamayo 2 Super ties a 32B VLA teacher model to AlpaGym, OmniDreams, CoC auto-labeling, and agent skills for L4 robotaxi development.

AI
Tether announced QVAC SDK 0.12.0 with TurboQuant support. The useful question is how KV cache compression changes local long-context AI.

AI
AWS AgentCore Optimization preview productizes agent quality loops with trace-based recommendations, batch evals, and A/B testing.

AI
Cohere Command A+ combines Apache 2.0 open weights, a 218B MoE design, 25B active parameters, 128K context, and enterprise deployment options.

AI
AWS SageMaker now supports /openai/v1 endpoints, lowering the migration cost for OpenAI SDK, LangChain, Strands Agents, and AI gateways.
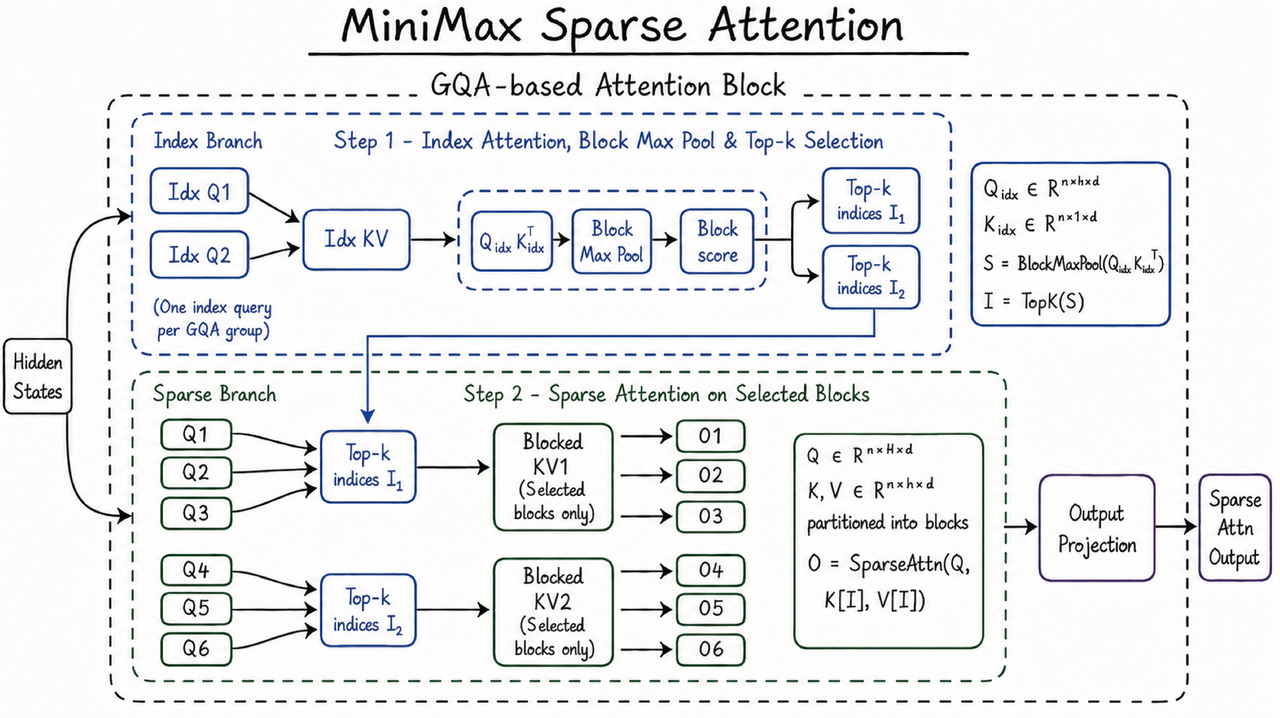
AI
MiniMax M3 combines 1M context, multimodality, and coding-agent benchmarks, but its weights and technical report are still pending verification.

AI
Mistral Search Toolkit public preview treats RAG and agent-search failures as retrieval, pipeline, and evaluation problems.

AI
NVIDIA and Microsoft introduced RTX Spark, a Windows PC category for local agents with 120B LLMs, 128GB unified memory, and OpenShell.

AI
CoreWeave introduced agentic AI integrations that connect inference, W&B Weave observability, serverless RL, and coding-agent tooling into one improvement loop.