Mistral Search Toolkit separates RAG failures from model failures
Mistral Search Toolkit public preview treats RAG and agent-search failures as retrieval, pipeline, and evaluation problems.

- What happened: Mistral AI released Search Toolkit as a public preview on May 28, 2026.
- The open source Python framework combines
ingestion,retrieval, andevaluationfor production search pipelines that can run in cloud, on-premises, or edge environments.
- The open source Python framework combines
- Why it matters: Mistral is telling RAG teams to measure whether the retriever found the right context before blaming prompts or replacing the LLM.
- Developer impact: BM25, dense vectors, hybrid search, reranking, recall, precision, MRR, and NDCG move into the default checklist for agent data paths.
- Watch: The toolkit is still a public preview, requires Python 3.12+, and each team still has to build corpus-specific relevance judgments.
Mistral AI released Search Toolkit public preview on May 28, 2026. The company describes it as a composable framework for building production search pipelines for AI applications. The announcement groups the work into three areas: ingestion for reading, splitting, and indexing data; retrieval for finding documents relevant to a question; and evaluation for measuring search quality separately. Mistral says the toolkit is open source and can run in cloud, on-premises, and edge deployments.
This is not a new model release. It is an attempt to pull a common production RAG failure mode out of the model layer. When an answer is wrong, teams often close the incident with "the LLM hallucinated." In practice, they need to check whether the retriever fetched the right document, whether chunking cut off the relevant paragraph, whether the index included the latest source, and whether the team has any relevance judgments at all. Mistral is turning that work into a productized search framework instead of leaving it as scattered glue code.
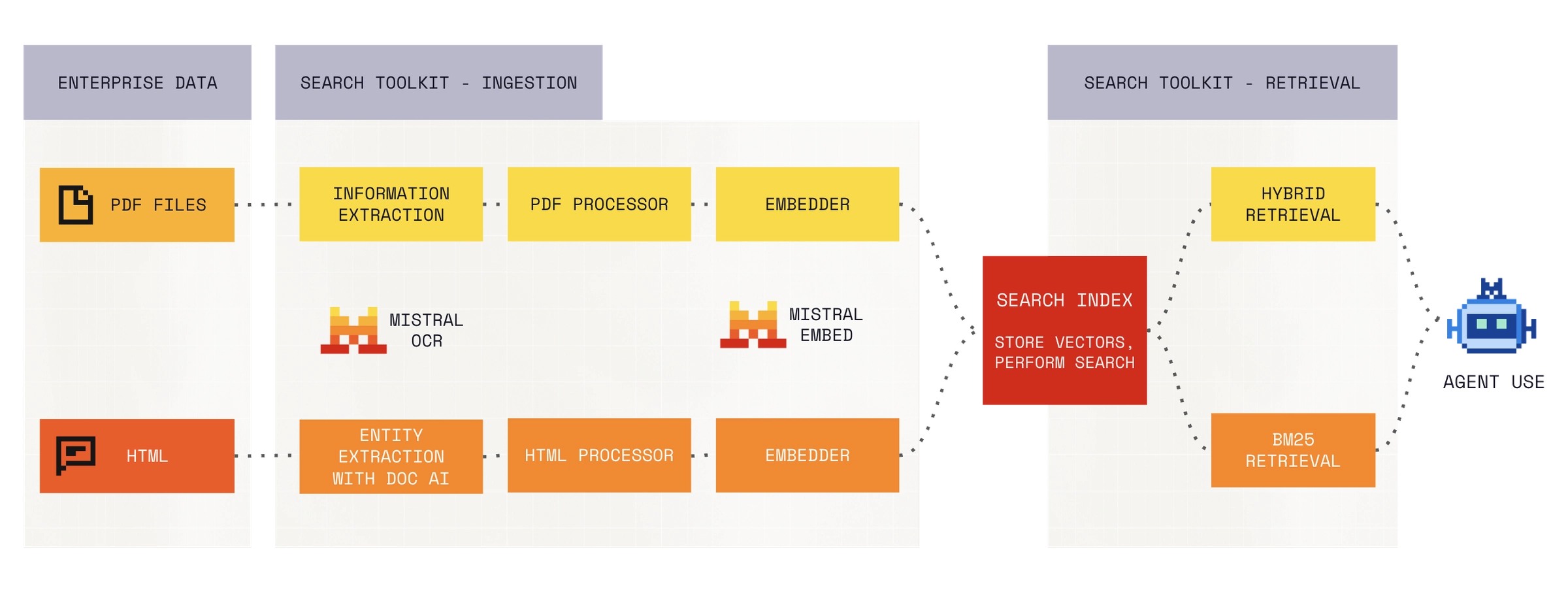
The official architecture image separates the ingestion path from the retrieval path.
What Search Toolkit bundles
The Mistral documentation defines Search Toolkit as a Python framework for production-ready Information Retrieval systems. Ingestion includes file loaders, document extractors, text splitters, optional chunk enrichers, embedders, and vector-store indexing. Retrieval passes through an optional query preprocessor, a retriever, and an optional reranker before returning relevant chunks. The two workflows are orchestrated through Pipeline and QueryEngine.
That component list maps directly to RAG failure points. A team has to know which sources the loader reads, how PDFs and spreadsheets are structured, whether chunk size breaks tables or code blocks, and whether metadata preserves tenant and permission boundaries. It also has to know whether the embedding model handles domain vocabulary and whether the reranker rescues necessary documents from the top-k set. Search Toolkit puts those pieces behind one abstraction layer. The documentation's emphasis that every component can be replaced follows from that design.
Mistral argues that many teams currently stitch ingestion, retrieval, and evaluation together with separate tools. That approach can be fast for a demo. It becomes brittle as corpus size and source diversity grow. Internal wikis, support tickets, file stores, and codebases all carry different document structures and metadata. If every source uses a different parser and chunker, search-quality comparisons become hard to trust because the experimental conditions keep changing. Search Toolkit keeps the pipeline interface stable while allowing source-specific processing to vary.
RAG failures need a retrieval side and a generation side
The most practical sentence in Mistral's announcement is about diagnosis. When a RAG system returns a bad result, the first question should be whether the problem is retrieval or generation. Mistral says many teams change prompts, adjust chunking, and swap models without making that distinction. If the team never measures whether the retriever surfaced the right context, the same error can reappear with a different model.
Search Toolkit uses built-in evaluation to isolate retrieval quality from generation quality. The announcement and documentation mention recall, precision, MRR, and NDCG. Recall asks whether the correct document appeared among candidates. Precision asks how many returned results are relevant. MRR looks at the position of the first relevant result. NDCG measures whether better-ranked results appear near the top. These metrics evaluate the search stage, not the final wording of an answer.
| Failure question | Model-only reaction | Search Toolkit lens |
|---|---|---|
| The answer document was missing. | Add "say you do not know" to the prompt. | Measure recall and index freshness first. |
| A similar but wrong document ranked higher. | Replace the model with a larger LLM. | Compare BM25, vector, hybrid search, and reranking on the same eval set. |
| Tables or policy clauses were cut off. | Force a stricter answer format. | Swap extractors and splitters by source type. |
| Domain terms did not search well. | Add a glossary to the system prompt. | Experiment separately with sparse, dense, hybrid retrieval, and query rewriting. |
This framing becomes more direct in agent products. A RAG chatbot usually waits for a human to choose the search terms. An agent creates multiple searches as part of a plan. One bad retrieval can feed the next tool call, approval request, or file edit. If the retriever returns an outdated pricing page, an agent can draft a quote with the wrong amount. If code search ranks a deprecated API above the current one, an agent can generate a patch that compiles but violates internal policy.
BM25 and vector search belong in the same comparison
Search Toolkit does not present dense embedding retrieval as the only path. Mistral's announcement says it supports BM25 sparse retrieval, dense embedding-based retrieval, and hybrid configurations that combine the two. The starter app includes preconfigured Vespa indexing and hybrid retrieval. That choice reflects a production RAG problem that appears in many enterprise corpora.
Vector search is strong when documents are semantically related. Sparse search can be more reliable for exact strings such as error codes, API parameters, invoice numbers, product SKUs, and legal clause numbers. BM25 may look old next to embeddings, but it remains a strong baseline for enterprise search. Dense embeddings help when a user asks in natural language for something like "last quarter's renewal terms." Hybrid retrieval exists because both signals matter.
The documentation lists vector search with optional reranking, query preprocessing, and semantic caching as retrieval components. Query preprocessing can use LLM reformulation or query extension to turn a user question into a better search query. Reranking can use an LLM reranker, a cross-encoder reranker, or a custom reranker. Semantic caching reuses results from similar queries to reduce repeated search cost. Each option changes quality, latency, and cost.
The practical questions are concrete. Does increasing top-k improve answer quality, or only add noise? Does BM25 rescue exact-term queries? Does a reranker move the first relevant document higher? Does query rewriting damage domain-specific abbreviations? Does semantic caching hold stale results too long? Search Toolkit is designed to compare those questions on the same evaluation set rather than through isolated anecdotes.
Document processing targets enterprise sources
Mistral's documentation lists ingestion support for PDF, DOCX, and PPTX through Mistral OCR, plus HTML, spreadsheets, emails, and plain text. File loaders can read from a local filesystem or custom loaders. Splitters include character, token, markdown-aware, and separator-based options. Enrichers can add metadata or LLM-generated summaries to chunks. Storage can use Vespa or a custom vector store.
That scope is broader than "put documents into a vector database." Enterprise search often mixes PDF contracts, spreadsheet price lists, email threads, HTML handbooks, and slide decks. A single chunking rule can split tables, detach footnotes from body text, and duplicate email reply chains. If extractors and splitters are not adjusted by source type, retrieval-quality problems can be misread as model problems.
The PyPI page lists mistralai-search-toolkit 0.0.8 as released on May 22, 2026. It requires Python 3.12 or later and below 3.15, and the license is Apache-2.0. Optional extras include vespa, extractor-pymupdf, extractor-spreadsheet, extractor-email, storage-azure, storage-gcs, and text-splitter-langchain. PyPI also shows Trusted Publishing attestations for the source distribution and wheel.
Those details matter for adoption. Python 3.12+ is reasonable for new projects, but some enterprise ML runtimes still need upgrades. The package carries a beta classifier, and Mistral's launch language is public preview. Before a team places it on the critical path for production RAG, it should review API stability, observability, error handling, version pinning, and rollback plans.
The starter app is Vespa-centered
Mistral's getting-started path begins with uvx copier copy gh:mistralai/search-starter-app my-search-project. The starter repository is a Copier template. The generated project contains a local Vespa setup, an ingestion entrypoint, a search entrypoint, and Vespa app migration. Its README requires Docker and uv, then indexes sample data and runs make search query="hello world".
Vespa is not an accidental choice. It is an open source search engine that handles vector search, lexical search, and ranking profiles together. Mistral's starter app launches local Vespa and tests hybrid retrieval. Even if Search Toolkit presents a backend-agnostic abstraction, its fastest starting path is designed around Vespa. Teams already operating Elasticsearch, OpenSearch, Pinecone, Weaviate, Qdrant, or Postgres pgvector will need to price the plugin and custom-store work.
Search Toolkit overlaps with general retrieval abstractions in LangChain and LlamaIndex. It also touches the territory of managed products such as Azure AI Search, AWS Bedrock Knowledge Bases, and Google Vertex AI Search. Mistral's difference is that Search Toolkit sits inside the company's broader agent stack with Studio, Connectors, Agents, and Workflows. A portable framework may appeal to teams that do not want a single cloud search service to own the pipeline. Teams that prefer managed operations may see that same portability as extra work.
Agents need both indexed data and live data
Mistral gives agentic search its own section in the announcement. Enterprise agents need access to enterprise context, and because they make many autonomous retrieval decisions, search-infrastructure quality affects downstream steps directly. Mistral distinguishes large document corpora, where indexed semantic search fits, from data that must be current, where Connectors pull live data from systems such as CRMs, code repositories, and productivity tools.
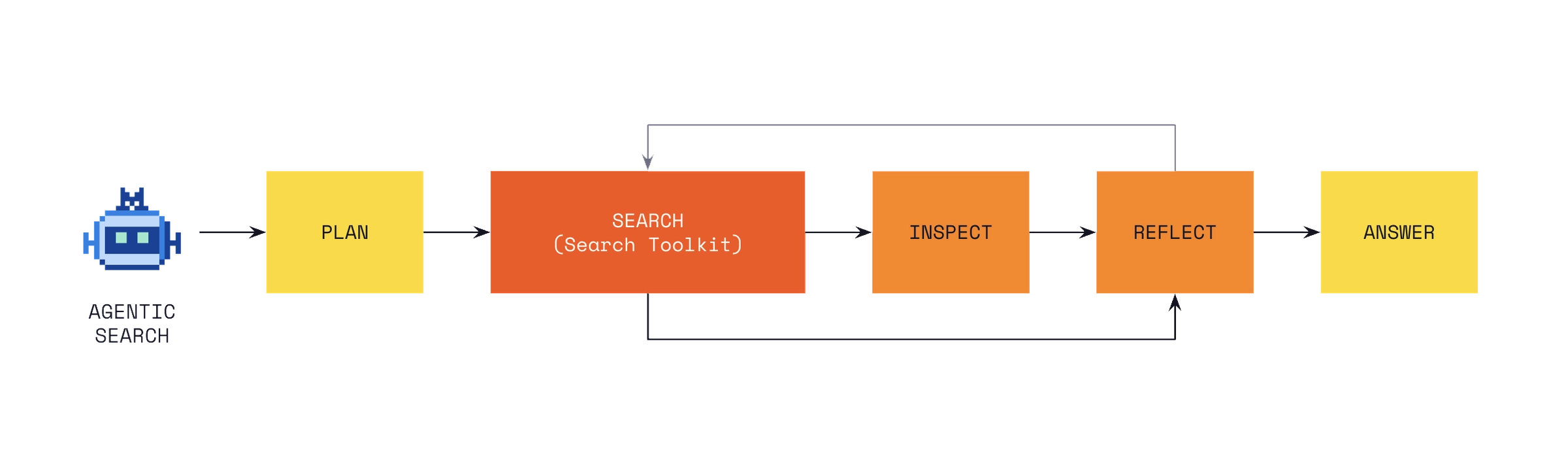
That split matters in architecture reviews. Reading every source through live connectors increases latency and rate-limit pressure. Indexing everything creates freshness and permission-propagation problems. Internal handbooks, API docs, and historical support tickets may fit an indexed corpus. Current account status, open incidents, latest invoices, and branch-protection settings often need live source access. An agent has to know which path it is using.
Search Toolkit owns the indexed search path. Connectors and MCP integrations handle live source access. Once both paths exist, observability also splits. Teams need to trace whether an answer came from an outdated indexed document, a failed connector call, or model reasoning. Mistral's product message is to ask where the search path failed instead of flattening every error into "the model was wrong."
The CMA CGM example mentions a 15-second alert
Mistral says Search Toolkit has been battle-tested in financial services, manufacturing, public sector, and media and entertainment. The public customer detail with a number is CMA CGM. According to the announcement, CMA CGM uses Search Toolkit with Voxtral to help journalists detect fake news. Mistral says the pipeline processes three audio data sources and returns an end-to-end alert in 15 seconds.
That is not a benchmark paper. The announcement does not disclose corpus size, relevance judgments, false positives, false negatives, or operating cost. It is still useful for understanding the relationship between agents and search pipelines. In fake-news detection, the model is only one stage. Product quality depends on which sources are pulled, how quickly transcription and indexing happen, whether alert criteria are verifiable, and whether human reviewers receive evidence they can inspect.
The 15-second figure also challenges the assumption that search is only offline preprocessing. Production AI applications often move ingestion and retrieval close to the user request. In environments with live audio, support tickets, incident logs, or code-review comments, index freshness becomes a quality metric. Mistral's decision to put ingestion and evaluation next to retrieval reflects that time dimension.
The competition is wider than vector storage
Search Toolkit's direct competitors are retrieval frameworks. LangChain, LlamaIndex, and Haystack already provide loaders, splitters, retrievers, and evaluators. Search backends include Pinecone, Weaviate, Qdrant, Elasticsearch, OpenSearch, Vespa, and pgvector. Evaluation tools such as Ragas, TruLens, Phoenix, and Braintrust measure RAG or broader LLM pipeline quality.
Mistral's position is wider than a single library. The company is building Studio for agents and apps, Connectors for MCP and enterprise systems, and Workflows for long-running processes. Search Toolkit's role in that bundle is the trustworthy search path an agent can use. The larger signal is not merely that a model company released a retrieval framework. It is that an agent-platform company is making search evaluation a control point.
For development teams, that market position changes the selection criteria. If a team already uses a cloud-managed search service, Search Toolkit may be a candidate for pipeline portability and evaluation. If a custom RAG system already runs on LangChain or LlamaIndex, the question is whether component-level experiment management and Mistral-stack integration justify the move. Teams already using Mistral models, Mistral OCR, Voxtral, Studio, or Workflows may see lower integration cost. Teams prioritizing multi-provider governance should check how tightly Search Toolkit binds them to the Mistral ecosystem.
Build the eval set before adopting the framework
The first task for a team evaluating Search Toolkit is not installation. It is a small relevance dataset. A support RAG system needs real customer questions paired with the correct document IDs. Developer-documentation search needs API names, error messages, migration guides, and deprecated functions in the query set. Legal or financial search should mix clause numbers with similar-looking clauses to expose false positives. Without an eval set, BM25, vector, hybrid, and reranker comparisons become preference arguments.
The second task is freshness and permission testing. A RAG pipeline cannot enter production if it ignores access filters, even when search quality is high. Tenant-specific documents, role-specific documents, deleted documents, and embargoed material need query-time exclusion tests. Stale-document tests matter too. After a document changes, the team should measure how many seconds or minutes pass before the index and cache reflect it. An agent executing a tool call from an old policy can create a larger operational issue than a bad chat answer.
The third task is a latency budget. Search Toolkit offers semantic caching, reranking, and query rewriting. These features can improve quality, but they add calls and latency. A chat answer where the user waits in real time has a different budget from a background agent's nightly analysis. A code-search agent that gathers repository context has a different path from a customer-support copilot answering during a live conversation. The same retrieval stack may need different budgets by workflow.
A tool for blaming the model less
The practical value of Mistral Search Toolkit is not that it teaches RAG from scratch. Many teams have already shipped RAG. The production problem is that incidents become hard to diagnose. When a user receives a wrong answer, the model, prompt, retriever, indexer, permission filter, source connector, and cache are all suspects. Search Toolkit gives teams a way to measure retriever and pipeline quality separately.
The announcement gives AI application teams an uncomfortable checklist. "We connected a strong model" is not enough to explain enterprise agent quality. They need corpus-specific relevance sets, source-specific extractors, sparse and dense retrieval comparisons, reranking experiments, index freshness, access filters, and audit logs. Mistral wraps that work in a framework, but the correct-document labels and business rules still have to come from the team.
The direction is clear enough. As agents take on more work, search becomes the evidence base for action rather than a helper feature. Teams that explain RAG failures only by model name will repeat the same incidents. Mistral Search Toolkit tells them to separate those failures into retrieval evaluation. Because the toolkit is still a public preview, it is not an automatic migration target. As a checklist for reviewing existing RAG and agent-search paths, it is concrete enough to use now.