RTX Spark Debuts as a Local AI PC for 120B LLMs
NVIDIA and Microsoft introduced RTX Spark, a Windows PC category for local agents with 120B LLMs, 128GB unified memory, and OpenShell.

- What happened: NVIDIA and Microsoft introduced a new RTX Spark Windows PC category for personal AI agents.
- The announcement landed on May 31, 2026 at GTC Taipei during COMPUTEX, with systems from ASUS, Dell, HP, Lenovo, Surface, and MSI planned for the fall.
- The numbers: NVIDIA is putting
1PFLOP FP4,128GB unified memory,120Blocal LLMs, and up to1M tokensof context on the spec sheet. - Why builders should care: The local-agent race is moving from model APIs into PC memory, CUDA runtimes, and OS-level permission boundaries.
- Watch: Price, thermals, Windows on Arm compatibility, and the real security model behind
OpenShellstill need shipping-system proof.
NVIDIA and Microsoft used GTC Taipei at COMPUTEX on May 31, 2026 to introduce RTX Spark, a Windows PC category aimed at personal AI agents. NVIDIA's newsroom framed the announcement less like a gaming GPU launch and more like a new execution surface for local agents. The public claims combine 1 petaflop of FP4 AI performance, up to 128GB of unified memory, Windows security primitives, and NVIDIA's OpenShell runtime.
RTX Spark is not just a smaller DGX Spark story. DGX Spark had already positioned itself as a compact AI supercomputer for researchers and developers. RTX Spark instead aims at the broader Windows PC ecosystem. NVIDIA and Microsoft are arguing that local AI should not stop at a small NPU feature or a cloud assistant calling back into the screen. Their pitch brings CUDA, TensorRT, PyTorch, llama.cpp, vLLM, Hugging Face tooling, and agent runtimes into Windows laptops and compact desktops.

The headline numbers are aggressive. NVIDIA says RTX Spark systems can deliver 1 petaflop of AI performance and up to 128GB of unified memory, then run a 120B-parameter LLM locally with an agent and as much as 1 million tokens of context. The same announcement bucket also includes 90GB-plus 3D scene rendering, 12K 4:2:2 video editing, 4K AI video generation, and 1440p AAA gaming above 100fps. NVIDIA is not presenting this as a narrow developer appliance. It wants creators, gamers, and software builders to share one local AI PC category.
The hardware reads like a PC version of Grace Blackwell. NVIDIA's GeForce announcement describes a Blackwell RTX GPU with 6,144 CUDA cores, fifth-generation Tensor Cores, and FP4 precision. That GPU connects to a 20-core NVIDIA Grace CPU over the NVLink-C2C chip-to-chip interconnect. Microsoft's Windows Experience Blog repeats the same shape: up to 6,144 Blackwell RTX cores, 20 power-efficient Arm architecture cores, and as much as 128GB of unified memory.
For builders, the first spec to inspect is not the 1PFLOP line. It is the 128GB unified memory ceiling. Local LLM work hits memory capacity and bandwidth before peak compute becomes the only problem. Small 7B and 14B models can already run on a single high-end GPU. Larger 70B-class models, long context windows, tool traces, retrieval caches, image workloads, and video generation quickly run past 24GB or 32GB of VRAM. NVIDIA's narrative is that the PC is moving from a machine that runs apps into a machine where agents perform tasks, and unified memory is the technical anchor for that claim.
Unified memory does not erase every bottleneck. DGX Spark's reference specs list 128GB of LPDDR5x coherent unified memory, a 256-bit memory interface, 273GB/s of memory bandwidth, and a 140W GB10 TDP. Having one large memory pool available to the model is useful, but bandwidth still differs from high-end workstation cards built around HBM or fast GDDR7. Real local-agent speed will depend on model size, quantization format, context length, tool-call frequency, batch size, driver maturity, and thermal behavior inside each OEM chassis.
That is why NVIDIA and Microsoft are not only talking about raw hardware. A local agent is not just a model loaded into memory. It reads files, observes the screen, moves the mouse, calls browsers, launches local shell commands, and may touch credentials or private repositories. Letting that run on a primary PC forces a harder product question than "is the GPU fast?" The system has to define which apps the agent can access, where filesystem writes are allowed, how user-approved actions differ from automatic actions, and how network requests or credential access are contained.
NVIDIA's answer is OpenShell and Microsoft security primitives. NVIDIA's blog says OpenShell is coming to Windows, and that Hermes Agent and OpenClaw will integrate OpenShell with Microsoft security primitives in new Windows apps. The same post says the NemoClaw blueprint is expanding across GeForce RTX, RTX PRO, RTX, DGX Spark, and DGX Station, with Hermes Agent support and a streamlined installer. The packaging is deliberate: local agents are being presented as OS-governed runtimes, not just risky automation scripts on a personal machine.
That framing maps directly onto coding-agent users. Claude Code, Codex, Cursor, Copilot CLI, and ComfyUI already pull developers between local environments and cloud devboxes. Microsoft's post names GitHub Copilot, Claude Code, ComfyUI, and Cursor as tools that run across modern PC silicon. On the RTX Spark side, NVIDIA says CUDA-accelerated PyTorch, llama.cpp, TensorRT, Hugging Face frameworks, Unsloth, and Kohya are part of the planned developer stack. Once an agent becomes a local runtime rather than a prompt window, OS vendors and GPU vendors both get new control points.
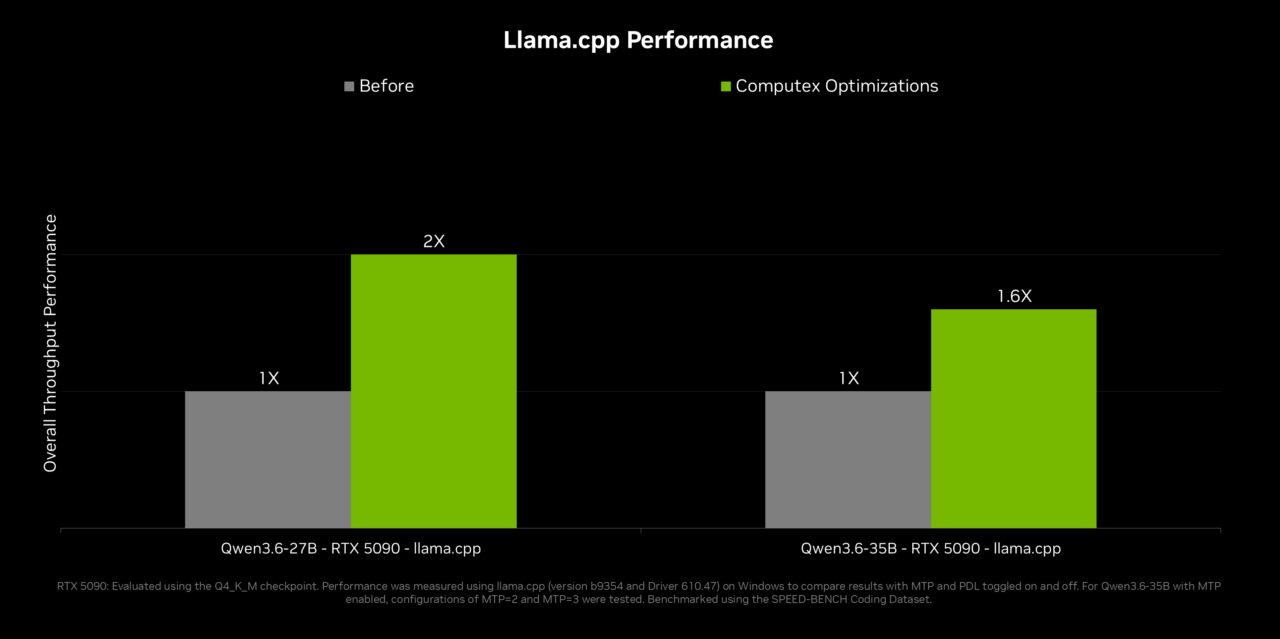
The performance work is also aimed at the agent runtime layer. NVIDIA's blog points to multi-token prediction in llama.cpp and vLLM, plus multi-GPU optimization in llama.cpp and ComfyUI, and describes up to 2x inference performance on top agentic models. That claim should be read as a broader local AI stack signal, not as an RTX Spark-only benchmark. If a model emits one token at a time too slowly, the agent UI feels broken. Tool calls stack up behind latency. Multi-token prediction and runtime optimization are low-level plumbing for making an agent feel like software rather than a batch job.
The partner list clarifies the intended market. NVIDIA says ASUS, Dell, HP, Lenovo, Microsoft Surface, and MSI will ship RTX Spark laptops and compact desktops in fall 2026, with Acer and GIGABYTE following. Microsoft separately points to Surface Laptop Ultra. Example systems include ASUS ProArt P16 and P14, Dell XPS 16 Creator Edition, HP OmniBook Ultra 16 and OmniBook X 14, Lenovo Yoga Pro 9n, and MSI Prestige N16 Flip AI+. If the same chip and runtime show up across multiple OEM designs, developers will compare "AI PCs" by memory, CUDA support, sandboxing, and local model compatibility rather than NPU TOPS alone.
The Apple Silicon comparison is unavoidable. MacBook Pro and Mac Studio machines are already used by developers as quiet local inference boxes with large unified memory pools. MLX, Ollama, llama.cpp, Apple Neural Engine, and Metal-based stacks are familiar to teams trying to avoid constant cloud spend. NVIDIA is countering with CUDA, TensorRT, RTX graphics, Windows app compatibility, and OEM variety. The useful comparison is no longer "can a model run locally?" It is whether the developer's tools, agent harnesses, drivers, and permission model keep working under realistic workloads.
Windows on Arm compatibility is one of the first shipping details to verify. Microsoft's post mentions MATLAB's official Windows on Arm support, Epic Easy Anti-Cheat and BattlEye, the Xbox PC app, Prism emulator compatibility, and games such as League of Legends, VALORANT, and PUBG. That list matters for AI builders too. Agents need to test real apps, browsers, IDE extensions, command-line tools, package managers, and local services. If those pieces behave inconsistently on Arm Windows, local automation becomes a demo rather than a daily development workflow.
Price is the second open question. NVIDIA's announcement gives partner availability and fall timing, but consumer pricing will vary by model. DGX Spark discussions on Hacker News and Reddit repeatedly returned to the same concerns: 128GB unified memory is attractive, CUDA is valuable, but buyers still compare total cost against a high-end RTX desktop, Mac Studio, cloud GPU devbox, or company-provided remote environment. RTX Spark's identity will depend on pricing. It could become a personal developer machine, a corporate workstation, or a premium creator laptop with unusually strong AI tooling.
Security boundaries are the third question. The name OpenShell signals a safer shell for agents, but actual security is determined by policies, defaults, prompts, audit logs, and enterprise integration. When an agent runs package installs, opens a browser with saved credentials, reads files outside the source tree, or asks for camera and microphone access, Windows and NVIDIA's runtime need to show what is happening and enforce limits. Microsoft refers to new security primitives, but developers still need to see whether those controls are preview-level APIs or something enterprise policy teams can manage.
Community reaction is already mixed between curiosity and skepticism. GeekNews items around June 1, 2026 included Claw Patrol, CodeBoarding, React Doctor, and Decepticon alongside other agent security and code-verification tools. That context matters: a local AI PC announcement is being consumed as part of the broader question of whether agents can safely receive production-adjacent permissions. Older Hacker News debates around DGX Spark spent time on FP4 peak-performance labeling, memory bandwidth, price/performance, shipping delays, and CUDA compatibility. RTX Spark inherits that checklist.
For development teams, the direct impact falls into three buckets. First, more prototyping can move local. Teams that cannot send sensitive code or data to a cloud agent could test quantized 70B- or 120B-class models, retrieval indexes, UI automation, and image or video generation on one workstation. Second, agent evaluation can move into an internal PC lab. A team can run the same prompts across local models and runtimes, then measure tool permissions, latency, and failure modes. Third, cost accounting changes. Instead of buying cloud tokens and GPU minutes for every experiment, some teams may amortize an expensive local machine.
That does not make RTX Spark the right default for every team. Companies already invested in cloud development environments and managed coding agents may care more about policy, audit trails, data residency, and CI integration than local FP4 throughput. Web SaaS and mobile app teams often need reliable browser automation, test runners, GitHub or GitLab permissions, and production logs more than a 120B local LLM. Media generation, CAD and 3D workflows, robotics simulation, privacy-heavy enterprise prototypes, and local evaluation labs are more likely to benefit from a single device that combines GPU compute, unified memory, and a local agent runtime.
The concrete shift in this announcement is how the AI PC category gets measured. In 2024 and 2025, AI PCs were often described through NPU TOPS and a Copilot key. NVIDIA's 2026 version describes the PC by whether an agent can work across local files, apps, shell commands, and model runtimes. That is closer to a buying criterion than a slogan. Developers now need to evaluate unified memory capacity, CUDA and TensorRT support, local LLM runtime maturity, sandbox policies, audit logs, OEM thermal design, and the boring compatibility matrix that decides whether automation survives beyond a keynote.
NVIDIA and Microsoft also have clear incentives. NVIDIA wants CUDA and RTX to extend from cloud GPUs back down to personal devices. Microsoft wants Windows to become the default local surface where agents execute under user and enterprise control. Their shared claim is that the personal PC can become developer infrastructure again. As cloud model APIs get stronger, a local PC risks becoming only a client. RTX Spark argues for the opposite: the PC can host model execution, agent permissions, creative rendering, and game runtime in one place.
The next evidence should be measured systems, not launch slides. Developers need to see which quantization format was used for the 120B LLM claim, what latency looks like at long context, how 1 million tokens affect memory pressure, what OpenShell exposes as an API, which Windows on Arm tools fail, and how prices compare with Mac Studio, RTX workstations, and cloud GPU subscriptions. NVIDIA has published the specs and partner list. Microsoft has opened the OS story. Builders now need reproducible repos, driver versions, runtime policies, benchmark methodology, and pricing.
If RTX Spark succeeds, local agents will stop being just hobbyist LLM launchers and become part of PC purchasing criteria. If it fails, it may remain a capable niche workstation category with strong headline numbers. NVIDIA is clearly trying to avoid the latter by tying together Windows, Surface, OEM partners, Adobe, Blender, llama.cpp, vLLM, and OpenShell in one announcement. The test is straightforward: agents have to run quickly, users have to stay in control, existing apps have to keep working, and the total cost has to make more sense than another cloud bill.