MiniMax M3 brings 1M context to open-weight coding models
MiniMax M3 combines 1M context, multimodality, and coding-agent benchmarks, but its weights and technical report are still pending verification.
- What happened: MiniMax announced M3 on June 1, 2026.
- The official page opened the
MiniMax-M3API, MiniMax Code, and integrations for coding tools, while saying the weights and technical report would arrive within 10 days.
- The official page opened the
- Product claim: M3 packages 1M token context, native multimodality, and coding-agent benchmarks into an open-weight candidate.
- Developer impact: teams get another model candidate for Claude Code, Codex CLI, Cursor, OpenCode, and self-hosted coding-agent stacks.
- The useful test is not the headline context length alone. It is whether M3 keeps relevant repo constraints, logs, and tool results stable through long agent runs.
- Watch: parameter count, license, model weights, and independent benchmark reproduction were still unavailable at launch.
MiniMax announced M3 on June 1, 2026. The company describes it as a frontier-class model for coding, agent work, 1M token context, and native multimodality. The model page says the API supports a maximum 1M token context window and guarantees at least 512K tokens. It also lists the model name as MiniMax-M3, gives the endpoint https://api.minimax.io/v1/text/chatcompletion_v2, and points developers toward MiniMax Code plus integrations with existing coding tools.
The phrase that needs the most careful reading is open weight. MiniMax says M3 brings complete frontier capability to the open world, but on June 1 the weights and technical report were not yet available. The official blog says MiniMax will keep improving serving stability and throughput, then release the technical report and corresponding model weights within 10 days. What can be inspected today is the hosted API, product integration path, benchmark descriptions, official images, and benchmark footnotes.
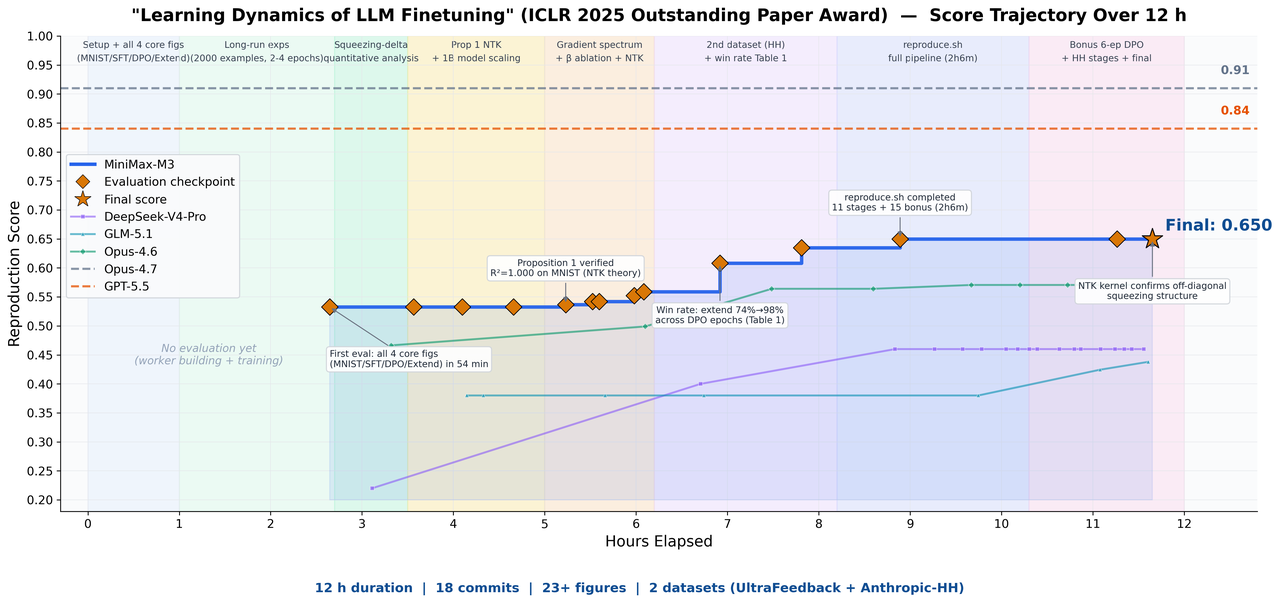
The official image shows MiniMax's long-running paper reproduction example for M3.
Why 1M context leads the announcement
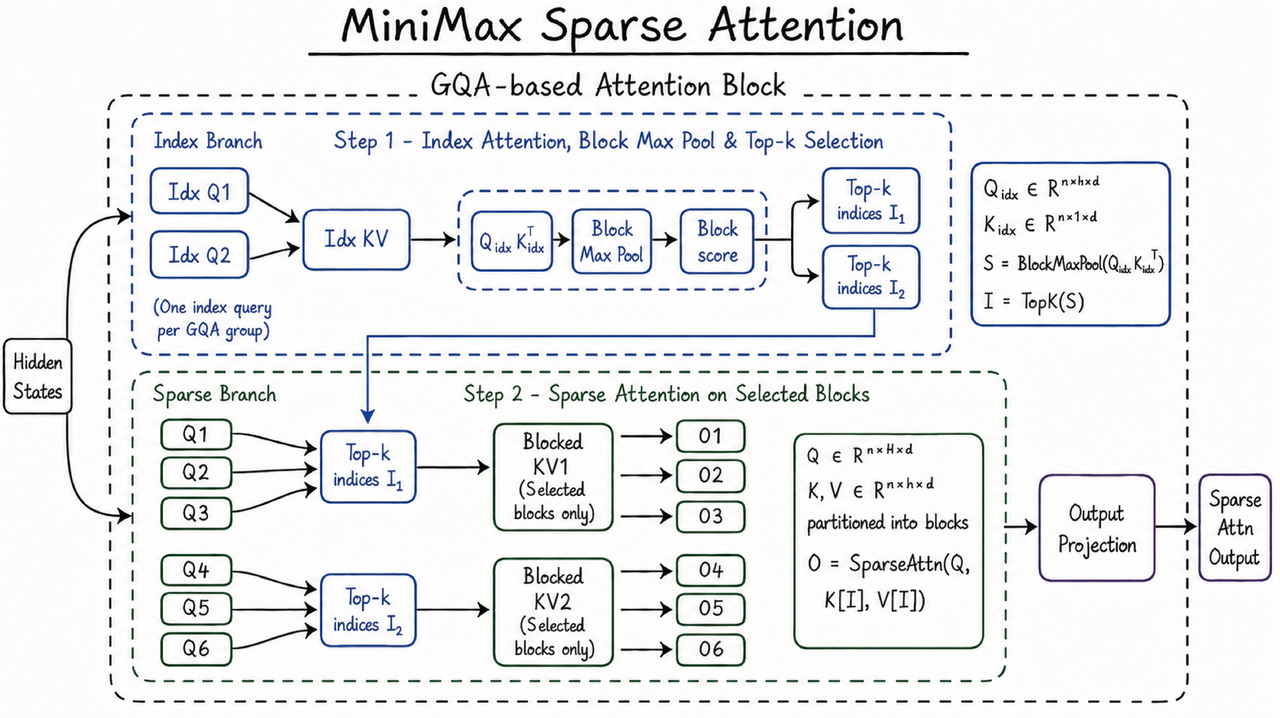
MiniMax calls M3's architecture MiniMax Sparse Attention, or MSA. The official description says MSA enables native ultra-long context pretraining and positions 1M context as infrastructure for long-range agent tasks, long-range coding, and long-video understanding. The launch does not present long context as a standalone number. It ties that number to coding agents and multimodal input.
In coding-agent products, context length is often marketed as if an entire repository can simply be dropped into a prompt. Real work is narrower. A model can accept one million tokens and still fail if the harness cannot choose the right files, logs, issue comments, and review rules. The opposite is also true: for large migrations, long CI histories, design docs, issue threads, and test failure traces, a 512K or 1M window can reduce pressure on retrieval and short-term memory. M3 should be judged less by how much it can read and more by how long it can preserve the evidence that actually matters.
The model page also says M3 supports caching automatically. That detail connects directly to cost and latency. Long coding sessions reuse repository context many times. Effective cache behavior can reduce repeated input cost and avoid restating the same project background after each tool call. The launch material does not yet answer harder operational questions: cache hit policy, stale context handling, privacy boundaries for private deployment, or whether hosted and self-hosted runs will behave similarly.
Strong benchmark claims, with conditions attached
MiniMax leads with coding and agent benchmarks. The model page says M3 scores 37.1 on PostTrainBench, placing third behind Opus 4.7 at 42.4 and GPT-5.5 at 39.3. It also claims 83.5 on BrowseComp, above Opus 4.7's 79.3. Across the blog and model page, MiniMax lists SWE-family tasks, Terminal, MCP Atlas, Claw-Eval, OSWorld-Verified, OmniDocBench, VideoMMMU, and other evaluations.
The footnotes matter as much as the charts. For SWE Atlas-Test Writing, MiniMax says GPT-5.5, Claude Sonnet 4.6, and Gemini 3.1 Pro scores came from labs.scale.com. Claude Opus 4.7, MiniMax-M2.7, and MiniMax-M3 were evaluated on MiniMax internal infrastructure with Claude Code scaffolding, a 4C8G sandbox, a three-hour timeout, and four-run averages. LiveSQLBench used 600 questions and 22 PostgreSQL databases, with each question run in a dedicated PostgreSQL sandbox and a 25-minute timeout. Several entries, including VIBE-V2, SVG-Bench, and GPDval-Rubrics, are described as internal benchmarks or internal evaluations.
Those conditions do not invalidate the launch. They define the order of verification. Engineering teams do not need one more leaderboard number in isolation. They need to know whether the model can finish pull requests inside their repositories, CI budgets, code review rules, private documentation, and security policies. MiniMax's numbers put M3 on the candidate list. Production routing still needs independent benchmarks and team-specific evals.
| Check | MiniMax claim | Question before adoption |
|---|---|---|
| Context | Up to 1M tokens, at least 512K guaranteed | Does it preserve relevant files and constraints through long repo input? |
| Coding agent | High ranks across SWE, terminal, Claw-Eval, MCP Atlas, and related tasks | Are patch quality and failure recovery stable under the team's CI and review rules? |
| Open weight | Weights planned for Hugging Face and GitHub | Are license, parameter count, serving memory, and quantization path public? |
| Tool integration | Works with Claude Code, Codex CLI, Cursor, OpenCode, and other tools | Does it fit existing approval, audit log, and secret-handling policies? |
The 24-hour CUDA example targets agent durability
MiniMax uses FP8 GEMM kernel optimization to illustrate M3's long-run behavior. The model page says M3 ran for about 24 hours, made 147 benchmark submissions, issued 1,959 tool calls, and improved hardware peak utilization from 7.6% to 71.3%, a 9.4x speedup. The starting point was a non-runnable Triton skeleton plus a task description, and MiniMax says no human intervention was involved.
That example is different from a typical coding-assistant demo. Coding agents often fail after the first patch, when they must read a failed benchmark, try again, cross a performance plateau, remember previous experiments, and avoid losing direction after many tool calls. MiniMax emphasizes 147 submissions and 1,959 tool calls because agent-loop durability is becoming a buying criterion alongside model quality.
The CUDA example still needs public reproduction. Kernel optimization is sensitive to hardware, benchmark harnesses, timeouts, compiler versions, allowed libraries, and scoring rules. An internal demo can be a useful signal, but a team choosing M3 should run comparable long tasks in its own environment: flaky test triage, dependency migration, database query optimization, UI snapshot repair, or another workflow where the local toolchain defines success.
Paper reproduction combines multimodality and long context
The official blog says MiniMax asked M3 to reproduce the ICLR 2025 Outstanding Paper "Learning Dynamics of LLM Finetuning." MiniMax says the run lasted almost 12 hours, producing 18 commits and 23 experimental figures. In the company's framing, M3 used multimodal capability to read charts and formulas in the paper, long context to keep the paper, code, and experiment logs together, and agentic coding ability to continue the experiment loop.
That example explains where MiniMax wants to place M3: not just as a code completion model, but between research assistant and coding agent. Paper reproduction includes text understanding, equation and figure interpretation, repository creation, experiment execution, figure generation, and result comparison. For product teams, that mixed workload may be closer to real work than a narrow benchmark. Internal model evals, report generation, data analysis, migration design reviews, and technical investigations all combine text, code, tables, screenshots, charts, and logs.
At the same time, paper reproduction is an easy demo format to overread. Eighteen commits and 23 figures measure activity, not correctness. The technical report will need to show how closely the reproduction matched the original paper, how random seeds and compute budgets were handled, which attempts failed, and where human review entered the process. Until then, the example is evidence of intended capability, not final proof.
API and coding-tool integrations are already live
The M3 model page is designed around developer choice. It lists Claude Code, Roo Code, Kilo Code, Cline, Codex CLI, OpenCode, Droid, TRAE, Grok CLI, and Cursor. API examples are shown in Python and curl. The request payload follows a simple chat completion shape: set model to MiniMax-M3 and send a messages array. MiniMax says the API versions return the same results while improving speed.
This lets MiniMax collect market feedback before releasing weights. Developers can connect M3 to tools they already use, while MiniMax can observe usage patterns and failure traces to improve serving stability. It also creates a direct provider path without waiting for third-party routing. For enterprises, the next questions are procurement and data boundaries. If the final goal is private cluster deployment, hosted API testing is only the first pass; license, weights, and inference stack details will need a second evaluation.
M3 will be most attractive to three kinds of teams. The first group wants to move some coding work away from expensive closed frontier APIs. The second works with repositories and document sets that exceed 200K context. The third wants multimodal input inside coding workflows. UI screenshots, architecture diagrams, paper figures, and spreadsheet screenshots create different failure modes from text-only coding tasks.
The community is asking for parameter count and weights
Early r/LocalLLaMA reaction mixed interest with missing-information checks. Some users were excited by the rare combination of open weights, 1M context, and multimodality. Others noted that the weights were not yet available and that parameter count was not visible. Some comments raised API output cost and token-plan changes. Others said they would wait for independent SWE-style tests before treating the benchmark claims as durable.
That reaction captures the open-weight community's standard. API benchmarks are not enough. Model size, active parameters, MoE routing, license, quantization, memory footprint, local serving throughput, tool-call formatting, and long-context degradation all need to be public. A 1M-context multimodal model immediately raises the question of whether it can run on a single GPU, a workstation, or only a larger hosted cluster.
Skepticism about context length is also practical. A huge window filled with irrelevant files can be worse than a smaller, clean context. Coding-agent products repeatedly hit that issue. Context selection often matters more than simply stuffing in a repository. Dependency graph, recent diff, test failure, owner rules, and security policy are the pieces that should reach the model. M3's 1M context does not remove the context-selection problem. It gives a better harness more room to work.
Open-weight competition comes back to operating cost
M3 is not competing with one model. On the closed frontier API side, it faces OpenAI GPT-5.5 and Codex, Anthropic Claude Opus and Sonnet, and Google Gemini. On the open-weight and self-hosting side, it sits near Qwen, DeepSeek, GLM, Kimi, Mistral, Cohere, and other model families. Inference and routing layers include OpenRouter, Fireworks, Together, and CoreWeave. At the product surface, Cursor, Claude Code, Codex CLI, Cline, and OpenCode bring model choice into daily developer workflow.
MiniMax's sharper positioning is that M3 is packaged as an agent model that plugs into coding tools, not just as a model endpoint. The benchmark footnote about using Claude Code scaffolding fits that stance. Developers usually compare coding models through an agent harness rather than through raw chat answers. M3 will be judged by diff quality, shell-command choices, failed-log interpretation, test rerun strategy, and response to review comments.
Cost should be evaluated the same way. The official page says M3 offers an ultra-low commercial threshold, but real cost depends on token price, cache hit rate, context length, output length, repeated tool calls, and rerun rate. A 1M-context model is not automatically cheap. If every attempt resends too much context and fails repeatedly, a low per-token price can disappear quickly. If caching works and the model reduces repeated exploration inside one long task, total cost can fall below a closed frontier run.
How to evaluate M3 now
The first useful experiment is not leaderboard reproduction. It is a small internal eval set built from real work. A team might collect 20 bug fixes, 10 dependency migrations, 10 flaky-test investigations, and 10 screenshot-based UI repairs. Each task should include a starting branch, expected tests, forbidden files, review rules, and a budget. M3, the team's current closed model, and the team's current open-weight model can then run under the same harness. Compare accepted diffs, total tokens, wall-clock time, and human intervention count.
The second experiment is long-context degradation. Run the same task at 50K, 200K, 512K, and 1M context. Vary the ratio of relevant to irrelevant files. Measure whether the model improves with larger context or whether command choice and patch focus become noisier. For coding agents, "can read it" is less important than "can read it and still act safely." Include policy tests around secrets, destructive commands, unrelated refactors, and generated-file edits.
The third experiment comes after the weights appear on Hugging Face and GitHub. Check the model card, license, technical report, parameter count, and active parameters. Then test recommended inference stack, quantization support, GPU memory, and throughput. Hosted API performance and self-hosted performance may diverge. MiniMax's endpoint may use cache and scheduling behavior that a private vLLM or other runtime deployment does not reproduce.
What M3 changes if the release holds up
MiniMax M3 raises the bar for open-weight coding model announcements. If the pending release matches the launch claims, developers will evaluate 1M context, multimodal input, coding-agent benchmarks, tool integrations, and private deployment in one model candidate. That combination creates a credible path for moving parts of long coding workflows away from closed frontier APIs and into infrastructure a team can control.
The conclusion still has to wait. As of June 1, 2026, weights and the technical report were not public. Parameter count and license details remained open. Many benchmark numbers involved internal infrastructure or internal evaluation conditions. M3 is therefore closer to "put this in the eval queue when the weights land" than "route production work to it immediately."
The direction is clear even before that proof arrives. Coding-agent competition is splitting into context length, tool-call stability, long-run durability, multimodal parsing, cache economics, and self-hosting options. MiniMax M3 puts all of those claims into one announcement. The next job for developers is to find out whether those claims keep the same meaning inside their own repositories, CI systems, security rules, and cost models.