Claude Fable 5 ships with Mythos-class safeguards and pricing
Anthropic released Claude Fable 5 and Mythos 5, splitting the same base model across safeguards, restricted access, pricing, and cloud retention rules.

- What happened: Anthropic announced Claude Fable 5 and Claude Mythos 5 on June 9, 2026.
- Fable 5 is the generally available Mythos-class model, while Mythos 5 is restricted to approved Project Glasswing customers.
- Product split: The two models use the same underlying model, but Fable 5 routes high-risk requests through a
Claude Opus 4.8fallback. - Builder impact:
claude-fable-5offers a 1M-token context window and 128k output at $10 per million input tokens and $50 per million output tokens.- Teams using AWS Bedrock need to review provider data sharing and 30-day input/output retention requirements at launch.
- Watch: The operational question is less about one benchmark table and more about access rights, false-positive safeguards, cost, and auditable deployment terms.
Anthropic announced Claude Fable 5 and Claude Mythos 5 on June 9, 2026. Its launch post describes Fable 5 as a Mythos-class model made safe for general use. The same day, Anthropic's API documentation added claude-fable-5 and claude-mythos-5, with the model overview positioning Fable 5 as Anthropic's strongest generally available model and Mythos 5 as an invitation-only model inside Project Glasswing. For developers, the naming is secondary. The more practical change is that one base capability is being divided by safeguards, access rights, price, and cloud data handling rules.
Fable 5 is available through the Claude API, Claude Platform on AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry from June 9. Mythos 5 also begins from that date, but it is not a general-availability product. Project Glasswing cybersecurity partners and approved customers are first in line for the upgrade. Anthropic also says it is working with the U.S. government to expand a trusted access program for cybersecurity organizations and is planning a separate access path for biological researchers. The launch is therefore not a single switch for every customer. It is a model release paired with role-based distribution.
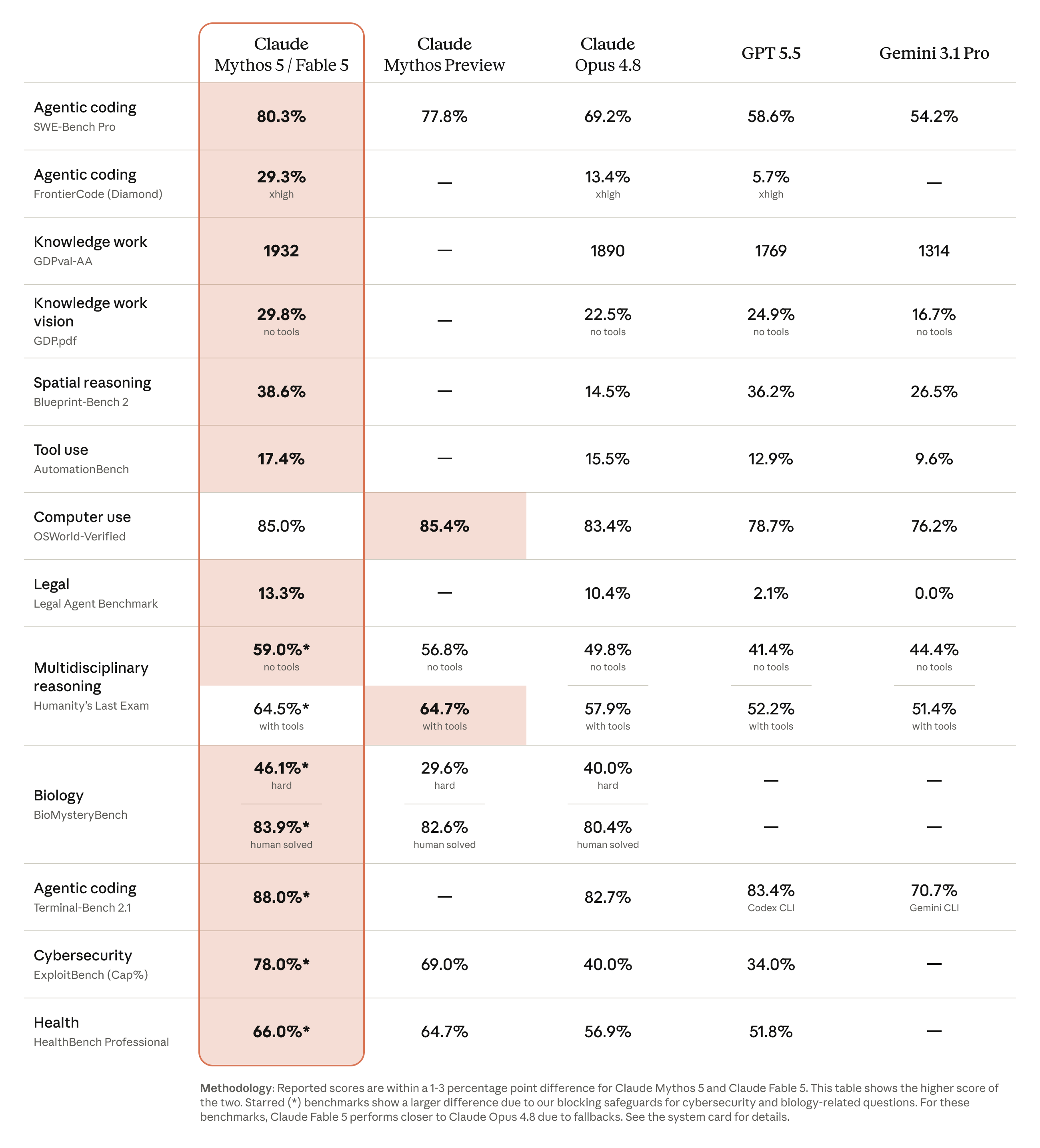
Anthropic's official benchmark image compares Fable 5 and Mythos 5 with other leading models. The company says the new models can work autonomously for longer than earlier Claude models and improve software engineering, knowledge work, vision, memory, and life-science research. The API details are more direct. Both models support a 1M-token context window, 128k max output, adaptive thinking that is always on, and text plus image input. The API IDs are claude-fable-5 and claude-mythos-5.
Pricing makes the launch immediately visible in Opus-tier budgets. Anthropic's pricing page lists the standard price for Fable 5 and Mythos 5 at $10 per million input tokens and $50 per million output tokens. The same table lists Opus 4.8 at $5 input and $25 output, making Fable 5 twice as expensive per token. Anthropic's long-context pricing page says Fable 5, Mythos 5, Mythos Preview, and Opus 4.8 include the full 1M-token context window at standard rates. A 900,000-token request and a 9,000-token request use the same per-token rate, even though the total bill is very different.
Anthropic explains the Fable 5 and Mythos 5 split through safeguards. The launch post says Fable 5 uses the same underlying model as Mythos 5, but requests that could be misused in areas such as cybersecurity are answered by Anthropic's next-strongest model, Claude Opus 4.8. The company says the conservative safeguard can catch harmless requests and activates in fewer than 5% of sessions on average. That percentage matters as much as the benchmark table. A team putting Fable 5 into a product now has to design for fallback behavior, user messaging, retry policy, and logs that explain why a response came from a different route.
Mythos 5 is the version with some of those safeguards removed for approved customers. Anthropic says Project Glasswing partners can upgrade from Mythos Preview to Mythos 5, and that Mythos 5 is similar to or stronger than Mythos Preview in most cases while costing substantially less. The policy question becomes who receives the strongest model first. Cyber defenders, critical infrastructure providers, and core open-source maintainers get a restricted access channel. General users get Fable 5, with additional safeguards in high-risk domains.
This structure follows Anthropic's June 2026 expansion of Project Glasswing. That earlier post argued that future frontier-model releases will become higher stakes in domains such as cybersecurity, where the same capability can help attackers and defenders. Project Glasswing prioritized critical infrastructure providers, core open-source maintainers, and safety testers. Fable 5 and Mythos 5 turn that principle into concrete model names, API IDs, and deployment paths.
The cloud terms are more sensitive. AWS News Blog announced Claude Fable 5 for Amazon Bedrock and Claude Platform on AWS, but also said Bedrock users need to configure provider_data_sharing through the Data Retention API at launch. The same AWS post says Anthropic requires 30-day retention of inputs and outputs, plus human review, for abuse detection on Mythos-class models. Enterprise teams that assume data stays fully inside an AWS boundary need to review that sentence separately before enabling Fable 5 in production.

AWS also published specific regional details. At launch, Fable 5 is available in Amazon Bedrock in US East (N. Virginia) and Europe (Stockholm). Claude Platform on AWS is available across North America, South America, Europe, and Asia Pacific. Bedrock access is not necessarily identical for every account on day one, and AWS says teams needing faster access should contact AWS Support. A multi-cloud fallback plan cannot stop at matching the model ID. Region, data sharing, account enablement, and contractual handling all have to line up.
Anthropic's subscription access has a temporary window as well. The official announcement says Fable 5 is included at no extra cost in Pro, Max, Team, and seat-based Enterprise plans from June 9 through June 22. Starting June 23, Fable 5 is removed from those included plans and requires usage credits, though Anthropic says it may extend the included period if capacity allows. It also says it intends to restore Fable 5 as a standard subscription feature once capacity is sufficient. Early access may feel like a free inclusion, but long-term adoption depends on credits and capacity updates.
The first operational question for developers is how fallback appears in the user experience. If Fable 5 flags a high-risk request, Opus 4.8 answers instead. Security products, vulnerability analysis tools, life-science literature tools, and incident-response workflows sit near that boundary. A user complaint that "the model got weaker" might actually mean the request triggered a safety route, the prompt was classified as high-risk, or the account lacks Mythos access. API clients need a logging schema that captures fallback state, refusal cause, and retry restrictions so operators can reconstruct what happened.
The second question is the cost of a 1M-token context window. Fable 5 benefits from long context being billed at the same per-token rate, but that base rate is twice Opus 4.8. An agent that loads a 700,000-token repository, design system, log bundle, or PDF collection can spend money quickly as the window grows. Designs that simply "send everything" get more expensive on Fable 5 unless they use prompt caching, batch processing, or retrieval trimming. Anthropic's pricing table lists batch pricing for Fable 5 at $5 input and $25 output per million tokens, so asynchronous analysis workloads may have a cheaper route.
The third question is data retention and human review. A team using the Claude API and a team using Bedrock may need different security review documents. AWS says Bedrock customers must enable provider data sharing for Fable 5 at launch, and that doing so means data leaves AWS's data and security boundary. Organizations that define the cloud provider boundary as the trust boundary need to revisit DPA terms, retention periods, human-review scope, and sensitive-data removal before approving Fable 5.
The fourth question is audit material for long-running agents. Anthropic emphasizes long-horizon coding tasks and knowledge work. AWS mentions long-running asynchronous execution, advanced vision, and proactive self-verification. As agents become more capable, reviewing only the final output is not enough. Plans, tool calls, intermediate files, failed steps, fallback events, costs, and approvals need to be tied to a single run. In coding-agent products, the execution trace can become more important evidence than the pull request itself.
The launch also targets the AI coding-agent market directly. Anthropic's announcement includes partner quotes from GitHub, Replit, Factory, Rakuten, Cognition, Hex, Periodic Labs, and Vercel. GitHub says Fable 5 shows more autonomy and reliability on complex long coding tasks than earlier benchmark runs. Cognition says Fable 5 reached the top score on FrontierBench. Vercel says Fable 5 scored highly on ViBench while building apps with less time and fewer tokens. These are partner statements inside a supplier announcement, not independent benchmarks. They still show how Anthropic wants Fable 5 to be read: as the premium model for coding agents.
Community reaction is not just about performance. Hacker News discussion included a user saying Claude becomes strong at design work when a design system or spec is encoded well in skill files, and that Fable 5 improves on Opus 4.7 and 4.8. Another user pushed back that it still does not match the UI quality a top-end company would ship. Reddit discussion in r/ClaudeAI focused on the fact that Fable 5 shares a base model with Mythos but adds safeguards, that usage credits apply after June 22, and that early limits are tight. The first user reaction is closer to "where does it block and how much can I use" than "which benchmark is highest."
Simon Willison's June 9 initial notes add a useful practitioner lens. He described Fable 5 as slow, expensive, and strong, and noted that guardrail triggers are frequent enough that the API now exposes guardrail hits and an option to request fallback. That changes how teams should read performance claims. Whether the model can solve a hard task is separate from whether a product can show which step was routed through the safety layer.
In competitive terms, Fable 5 will be compared with OpenAI GPT-5.5, Google's Gemini family, xAI, and other frontier models. The distinctive part of this announcement is not only benchmark ranking. The public model carries safeguards. The restricted model goes to approved defenders and researchers. Cloud deployment can require provider data sharing and retention. Subscription access can move between included capacity and usage credits. The frontier-model race is shifting from "which API is strongest" toward "who can use the strongest model, under which constraints."
Enterprise AI teams should run three tests before making Fable 5 the default model. First, measure how often existing production prompts trigger the safety fallback. Second, compare Fable 5's task-level success rate with Opus 4.8 and decide whether the improvement justifies twice the token price. Third, if the deployment path includes Bedrock, Vertex AI, or Microsoft Foundry, compare region, data handling, logging, and contract terms rather than assuming the same claude-fable-5 ID means the same risk profile everywhere.
For individual developers and small teams, limits and credits may matter first. The June 9 to June 22 subscription inclusion is useful for experimentation, but repeated long agent runs become harder once usage credits are required. In a coding-agent setup, Fable 5 may be best used selectively for architecture review, difficult bug isolation, large refactor planning, or cross-file reasoning where failure is expensive. Routine completions and iterative edits still need routing to cheaper models.
Security teams should avoid approving Fable 5 simply as "safe Mythos." Anthropic says safeguards activate in fewer than 5% of sessions on average, but that is an overall average. A workload centered on vulnerability analysis, incident response, malware triage, or biotech literature review may trigger at a much higher rate. Overly conservative classification can also route legitimate defensive work to Opus 4.8 and lower quality. Approval documents should describe allowed defensive purposes, fallback handling, and human escalation, not only banned prompts.
The larger meaning is that frontier-model release now looks less like ordinary software deployment and more like a mix of financial product terms and security clearance. The same model family can be split into general, restricted, cloud-specific, and credit-metered subscription versions. The price sheet includes context and batch terms. Cloud documentation includes retention and human review. Developers choosing a model are now also designing access rights, data boundaries, cost controls, and audit logs.
The next indicators are concrete. Can developers clearly observe safety fallback in API responses? What limits remain for subscription users and team accounts after the June 23 credit transition? What application process and audit terms will Project Glasswing trusted access require? And do independent benchmarks or production-agent case studies justify Fable 5's twice-Opus token price? The news value of Fable 5 is not just a new model name. It is that these four conditions have become part of the product.