Cohere North Mini Code tests a 3B-active model for coding agents
Cohere released North Mini Code, an Apache 2.0 coding model that activates 3B of 30B parameters for agentic software engineering, terminal work, and long-context tool use.

- What happened: Cohere released
North Mini Codeon June 9, 2026.- The model is a 30B total / 3B active sparse MoE coding model available on Hugging Face under Apache 2.0.
- Developer impact: its headline specs point directly at coding agents: 256K context, 64K output, tool-call templates, and vLLM deployment instructions.
- Reality check: Cohere lists 1 H100 at FP8 as the minimum hardware in its published snapshot.
- This is better read as an open-weight option for internal GPU clusters and private inference, not a casual laptop-local model.
- Watch: the practical test is whether teams can keep tool calls, long terminal traces, GPU cost, and audit logs stable in real repositories.
Cohere released North Mini Code on June 9, 2026. The name suggests a small model, but the more precise description is a coding-agent model that activates a small part of a larger sparse system. Cohere's announcement introduces it as the company's first agentic coding model and the first North model built for developers. The model has 30B total parameters, activates 3B parameters per token, and is available through Hugging Face under an Apache 2.0 license.
The release is not just another model-card update because Cohere is explicit about the target workload. North Mini Code is tuned for code generation, agentic software engineering, and terminal tasks. That framing assumes a system that reads repositories, calls tools, receives terminal output, and feeds those results back into the conversation. In the open-weight model market, "can it write code?" is no longer enough. The separate product question is whether the model can keep tool calls, context, and recovery loops coherent across a long agent run.
A 30B model with 3B active parameters
The central numbers are 30B and 3B. The Hugging Face model card describes North Mini Code as a 30B-A3B parameter model. The full model has 30B parameters, but token processing activates a smaller expert path. The architecture note describes a sparse Mixture-of-Experts model that routes each token through 8 of 128 experts. The feed-forward block uses SwiGLU activation, while attention combines sliding-window attention and global attention in a 3:1 ratio.
That design touches two costs that matter in coding agents. The first is capacity. A useful coding agent must handle repository structure, dependencies across files, terminal logs, previous reasoning, and failed-test recovery. A very small dense model can hit those limits quickly. The second is inference cost. Coding agents do not usually stop at a short answer. They produce plans, diffs, test analysis, retries, and review notes. A smaller active parameter count can reduce compute per token even when the total model remains larger.
The hardware requirement keeps the release grounded. Cohere's published snapshot lists a minimum of 1x H100 @ FP8. "3B active" is a serving-efficiency claim, not a promise that the model will comfortably run on an 8 GB laptop GPU. Open weights and easy local execution are different things. For teams, the more realistic deployment discussion is internal GPU capacity, private inference, Cohere Model Vault, OpenRouter, OpenCode, or another managed path that can host the model with the required serving stack.
What the benchmarks say, and what they leave open
Cohere published agentic coding benchmark numbers in the announcement and model card. The headline set is specific: SWE-Bench Verified 67.6, SWE-Bench Pro 40.2, Terminal-Bench v2 36.0, Terminal-Bench Hard 31.1, SciCode 38.2, and LiveCodeBench v6 70.3. The comparison group includes Devstral Small 2, Poolside XS.2, Gemma4, and Qwen3.6.
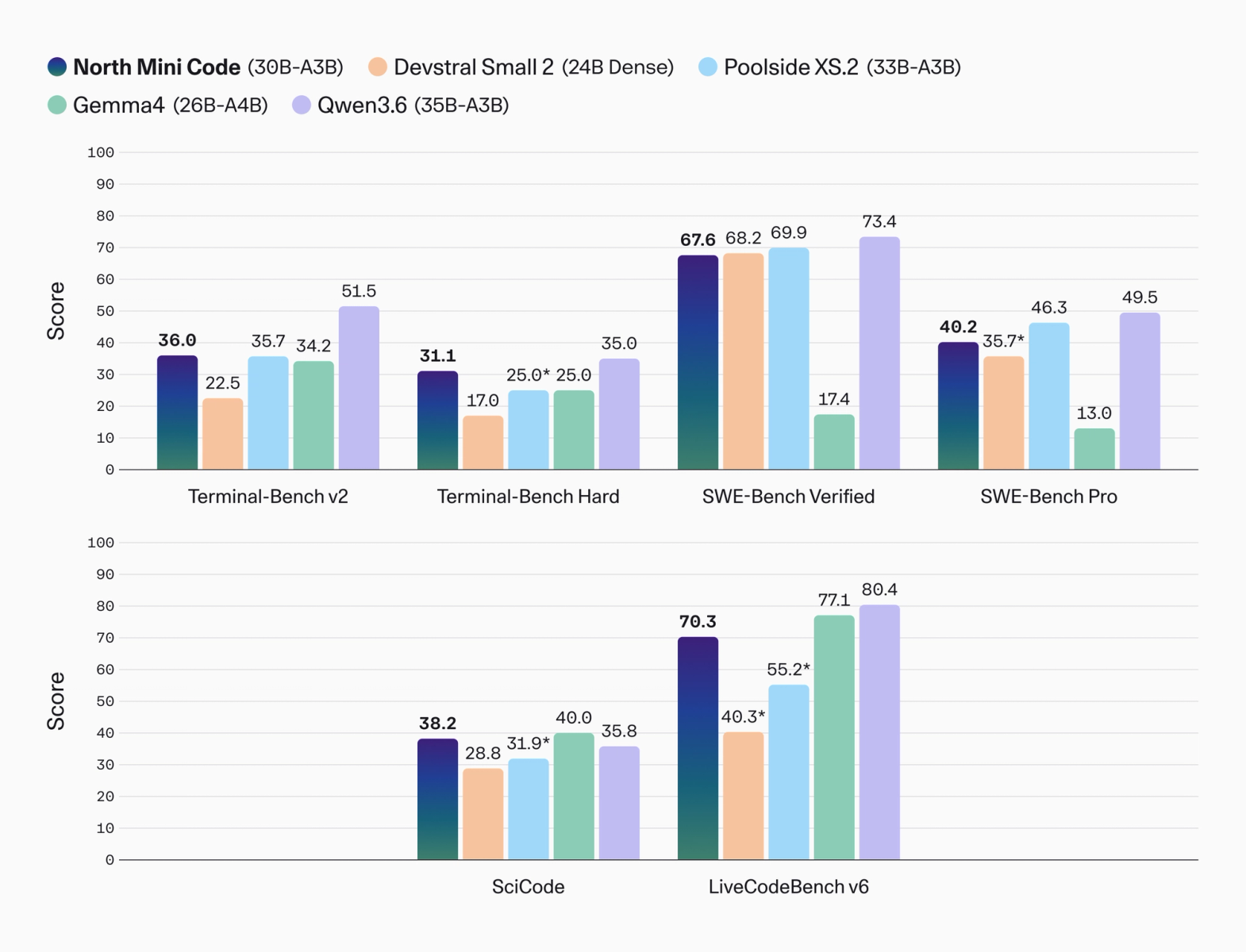
North Mini Code does not win every axis in Cohere's chart. On SWE-Bench Verified, Poolside XS.2 and Devstral Small 2 are slightly ahead, while Qwen3.6 is higher at 73.4. On LiveCodeBench v6, Qwen3.6 and Gemma4 also land above North Mini Code. The stronger signal is Terminal-Bench Hard, where North Mini Code posts 31.1 against Devstral Small 2 at 17.0, Poolside XS.2 at 25.0, and Gemma4 at 25.0. That is the part of the chart that aligns most closely with Cohere's terminal-task positioning.
The evaluation setup deserves scrutiny. The model card says SWE-Bench used SWE-agent harness v1.1.0. Terminal-Bench v2 used Harbor's Tmux-session-based single-terminal-use ReAct harness. Terminal-Bench Hard used Terminus-2 with a methodology aligned with the Artificial Analysis Intelligence Index. Cohere also marks some missing competitor scores as internally run with recommended settings. That mixture makes the numbers useful but not final. Agentic benchmarks are sensitive to harness design, tool formatting, retry policy, timeout settings, and how terminal results are serialized.
Even with those caveats, the direction is clear. Coding-model comparisons are moving away from short HumanEval-style function completion and toward repository modification, terminal command execution, long context, tool-result handling, and test-failure recovery. North Mini Code is a case study in a smaller active MoE model being marketed first through agentic benchmarks rather than generic chat scores.
Throughput is aimed at Devstral Small 2
Cohere's most aggressive claim is about serving speed. The company says its internal testing showed North Mini Code delivering up to 2.8x higher output throughput than Devstral Small 2, with a 30% advantage in inter-token latency. It also states that Devstral Small 2 was slightly ahead on time to first token. That tradeoff matters in coding agents because the first token is not the whole experience. Long diffs, repeated test logs, and recovery analysis can make sustained output throughput more important than the first few milliseconds of response time.
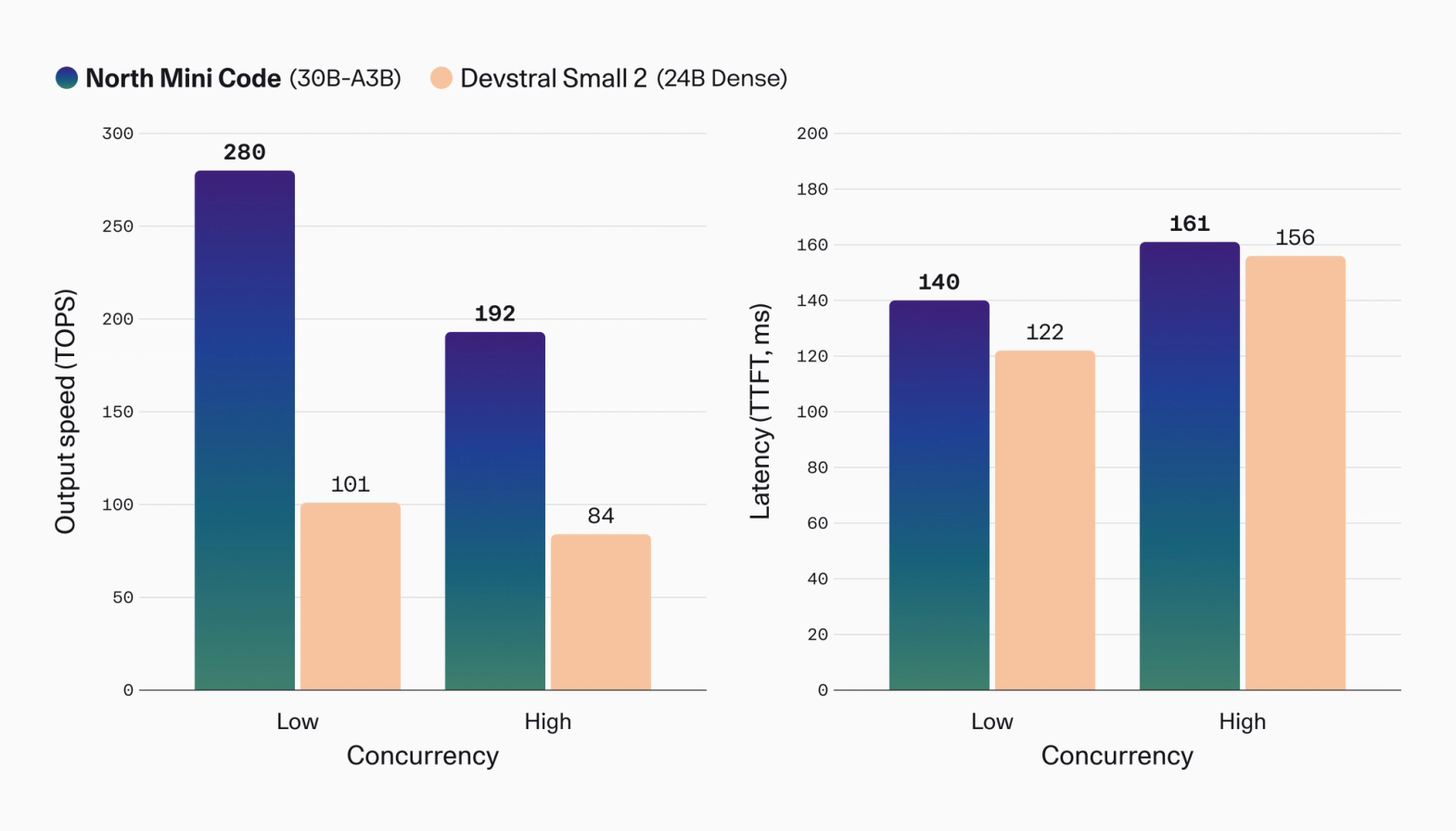
The chart frames the gap in throughput terms. At low concurrency, North Mini Code is shown at 280 TOPS versus Devstral Small 2 at 101 TOPS. At high concurrency, the chart shows 192 versus 84. Latency is closer: 140 ms versus 122 ms at low concurrency and 161 ms versus 156 ms at high concurrency. If Cohere's claim holds in outside deployments, North Mini Code is not primarily a model for shaving first-response delay. It is a model for pushing more generated output through the same kind of serving setup.
That difference translates into product cost. A coding agent that opens one pull request may generate a plan, read files, propose edits, run tests, inspect failures, patch again, and write a review summary. Output tokens pile up quickly. If generation is slow, developers wait. If serving cost is high, teams narrow where the agent is allowed to run. North Mini Code's best-fit workload is not "one frontier model call for the hardest task." It is repetitive agent steps where a private or open-weight model can run many iterations at acceptable speed and cost.
Tool calling still depends on runtime integration
The model card's tool-use section is one of the most practical parts of the release. Cohere documents a chat-template approach where tool descriptions are passed as JSON schema. Its example defines a bash tool, lets the model generate thinking content and a tool call, then appends both back into chat history. Tool results are inserted with a tool role as dictionary-shaped content. That pattern is familiar from coding-agent runtimes, but in open-weight deployments the parser and template become part of the product.
vLLM setup is also not yet a one-command abstraction. The model card instructs users to run from the vLLM main branch, install cohere_melody>=0.9.0, and pass --tool-call-parser cohere_command4, --reasoning-parser cohere_command4, and --enable-auto-tool-choice. OpenCode integration requires configuration for the interleaved reasoning field. Downloading the weights does not produce a finished coding agent. The tokenizer, chat template, reasoning field, tool-call parser, streaming format, and history serialization all have to line up.
That is both the advantage and the adoption cost. Closed APIs hide most of the tool-call and streaming details behind provider contracts. Open-weight models ask the team to own the boundary. If the integration works, the team gains more control over model update cadence, data flow, inference location, and logging. For regulated industries or companies that cannot send source code and terminal traces to an external model API, that control can justify the operational work.
Cohere's sovereign AI message reaches developer tooling
Cohere has been repeating a sovereign AI message across recent releases. Command A+ emphasized private deployment and open models. The Reliant AI acquisition attached workflow depth in regulated industries. North Mini Code moves the same argument into developer infrastructure. Cohere uses the phrase "sovereign developer ecosystem" in the announcement: developers should not have to depend only on vendor APIs to run coding agents against their own code.
That position puts Cohere against OpenAI, Anthropic, GitHub, Google, and the managed coding-agent market. Closed coding agents usually offer stronger frontier models, managed tool execution, and a more polished product experience. Open-weight models offer more choices around execution location and cost structure. The question for North Mini Code is not only whether it is smarter than Claude Code or Codex. The more direct question is whether a team that cannot send repository contents and terminal traces to an outside API can run a useful coding agent inside its own boundary.
| Evaluation area | North Mini Code | Closed coding-agent API |
|---|---|---|
| Data path | Can be controlled through internal GPUs, Model Vault, or a chosen inference path | Depends on the provider API and product policy |
| Operations | Requires vLLM, parsers, scaling, and monitoring work | Provider manages tool execution and streaming formats |
| Cost unit | GPU capacity, serving engineers, utilization, and quantization | Tokens, seats, premium requests, or action minutes |
| Validation | Needs repo-specific traces and tool-call stability tests | Uses provider benchmarks plus product telemetry |
Community reaction splits between interest and hardware reality
The first public reaction arrived quickly. On Reddit's r/LocalLLaMA, a Cohere representative posted the release and mentioned weekend feedback on an unreleased version before the official launch. Another LocalLLaMA thread summarized the 30B total / 3B active setup, Apache 2.0 license, Artificial Analysis Coding Index 33.4, and Hugging Face availability. OpenCode said on X that North Mini Code would be available with 256K context for free.
The split is predictable. Supporters see an Apache 2.0 coding model that comes with agentic benchmark data and tool-use guidance. Skeptics see the single-H100 requirement. Open weights do not erase serving cost, especially when the model advertises 256K context and 64K output. Large context windows create KV-cache pressure, concurrency limits, and tool-log-management problems. North Mini Code is closer to an internal agent-infrastructure candidate than to a hobbyist local model.
The Hugging Face page points in the same direction. The model card documents Transformers, vLLM, SGLang, Docker Model Runner, and quantization options, but the Inference Providers section currently shows no deployed provider. In open-model ecosystems, adoption is decided after the weight release. The first user experience depends on how smoothly llama.cpp, Ollama, LM Studio, vLLM, SGLang, OpenCode, and managed providers wire up the model, parsers, memory requirements, and quantized variants.
The questions a development team should test first
A team evaluating North Mini Code should start with its own repository traces, not Cohere's benchmark table. Pick 20 real tasks: a small bug fix, failed-test recovery, multi-file refactor, migration script, CI log analysis, and a dependency update with edge cases. Run the same set against North Mini Code, Devstral Small 2, Qwen3.6, Claude, Codex, or whichever candidates are realistic. Track success rate, command count, retry count, wall time, output tokens, and the human review diff.
The second question is tool-call format stability. The model may know how to describe a bash call, but a production agent usually needs read_file, edit_file, run_tests, issue metadata, pull-request comments, and secret redaction. Teams should test whether the model follows schema constraints under long context, whether reasoning fields improve the next turn, and whether stale reasoning creates false confidence. Cohere's model card recommends passing model-generated thinking content into future agentic steps and chat turns. That can help performance, but it also raises product-logging, privacy, and audit-trail questions.
The third question is cost. "One H100 to start" is encouraging from a procurement view, but coding-agent usage is bursty. Developers may launch several tasks during working hours, while CI or scheduled refactors may run overnight. If utilization is low, a managed API can be cheaper than self-hosting. If security policy blocks external APIs, however, cost comparison may be secondary. The open-weight path may be the only permitted path for code and terminal traces.
The signal North Mini Code leaves
North Mini Code does not support a simple "best coding model" conclusion. Cohere's own chart shows it does not lead every benchmark. The more useful signal is operational: coding-agent model choice is splitting into frontier APIs, IDE products, cloud agents, and open-weight self-hosting. Cohere is putting a developer model into the open-weight and private-deployment lane.
The next few weeks of usage reports will matter more than the release graph. Real repositories will show whether the tool-call parser is stable, how 256K context behaves with long codebases, and how far the single-H100 condition can be reduced through quantization and batching. Artificial Analysis Coding Index 33.4 and SWE-Bench Verified 67.6 are starting points. In production, test pass rate, diff quality, review burden, token budget, GPU invoice, and auditability will be the colder scorecard.
Cohere's direction is still clear. Coding agents will not live only inside closed chatbot products. Model weights, inference stacks, tool-call parsers, terminal harnesses, and IDE or CLI surfaces are now part of the same competitive bundle. North Mini Code is an experiment in whether a small-active MoE can run useful coding-agent work inside a team's own boundary. Whether it succeeds broadly or only in narrower enterprise deployments, the model-selection question is getting more concrete: not who announced the largest model, but which system can keep working on our code, in our terminal, inside our security boundary.