Gemma 4 12B Brings Local Multimodal AI to 16GB Laptops
Google Gemma 4 12B pairs local 16GB laptop inference, audio and vision inputs, and a LiteRT-LM OpenAI-compatible server.

- What happened: Google DeepMind released
Gemma 4 12B Unifiedon June 3, 2026.- Google positions it as a mid-size open model that can run locally on laptops with 16GB VRAM or unified memory.
- Architecture: Gemma 4 12B accepts text, image, audio, and video-frame inputs without separate multimodal encoders.
- The developer guide describes a 35M vision embedder, 16 kHz audio split into 40ms frames, and a shared fine-tuning path through the LLM backbone.
- Developer impact:
litert-lm serveexposes a local OpenAI-compatible endpoint for tools such as Aider, Continue, OpenCode, and Open WebUI. - Watch: The 16GB claim still needs workload-specific testing across runtime, quantization, app overhead, long context, and tool-calling behavior.
Google DeepMind released Gemma 4 12B on June 3, 2026. Google describes the model as a mid-size open multimodal model that can run on laptops with 16GB of VRAM or unified memory. The launch centers on three concrete pieces: an 11.95B dense model, text-image-audio input support, and a unified architecture that avoids separate multimodal encoders.

This is not just another "smaller model" announcement. AI development tools have been moving toward cloud models wrapped in remote execution surfaces: Codex, Claude Code, Copilot, Cursor, and similar products all assume that important work often leaves the laptop. Gemma 4 12B pulls the execution point back toward the developer machine. For teams analyzing private repositories, internal docs, meeting audio, screenshots, or local datasets, model quality is only one variable. Runtime integration and data location decide whether a workflow can be adopted at all.
Google says Gemma 4 models have passed 150 million cumulative downloads. The broader Gemma 4 family, introduced in April 2026, already included edge-friendly E2B and E4B variants, a 26B A4B mixture-of-experts model, and a 31B dense model. The 12B Unified model fills the gap between small edge models and larger local-or-server models. It is aimed at developers who want more reasoning ability than E4B, but do not have the hardware budget or latency tolerance for a 26B MoE or 31B dense model.
The product shape is unusually practical for a model launch. The headline deployment target is local inference on 16GB VRAM or unified memory. The input set includes text, images, audio, and combinations of video frames. The serving path includes a local OpenAI-compatible endpoint through LiteRT-LM. The license is Apache 2.0, which lowers legal friction for commercial products, internal tools, and fine-tuning experiments. Those details matter because local models often fail to become useful not at the benchmark table, but at the point where a developer tries to connect them to an existing agent harness.
Google's developer guide explains the architecture change more directly. Traditional multimodal systems often process images or audio through a separate encoder, then pass encoded representations into a language model. Gemma 4 12B reduces that separation. Vision input goes through a 35M-parameter vision embedder that projects 48x48 pixel patches into the LLM hidden dimension. Audio is treated as a 16 kHz raw signal split into 40ms frames, or 640-float chunks, and linearly projected into the same input space.
That design affects fine-tuning and latency. Google says vision, audio, and text pass through the same weights, so downstream adapters or full tuning can operate in a single loop instead of adapting around a frozen external encoder. For teams using LoRA or Unsloth, the promise is less split-brain tuning: the text model is not adjusted while the vision or audio path remains a separate component with its own behavior. That claim comes from Google's architecture description; teams still need to validate quality on their own datasets before treating it as an operational guarantee.
The Hugging Face model card lists Gemma 4 12B Unified at 11.95B parameters and 48 layers. The same table shows a 1024-token sliding window and 256K context length. The 31B Dense model also has a 256K context length, but 12B Unified adds audio input. The 26B A4B MoE model uses 3.8B active parameters out of 25.2B total parameters, making it a different tradeoff: faster active inference rather than the unified audio-image-text path.
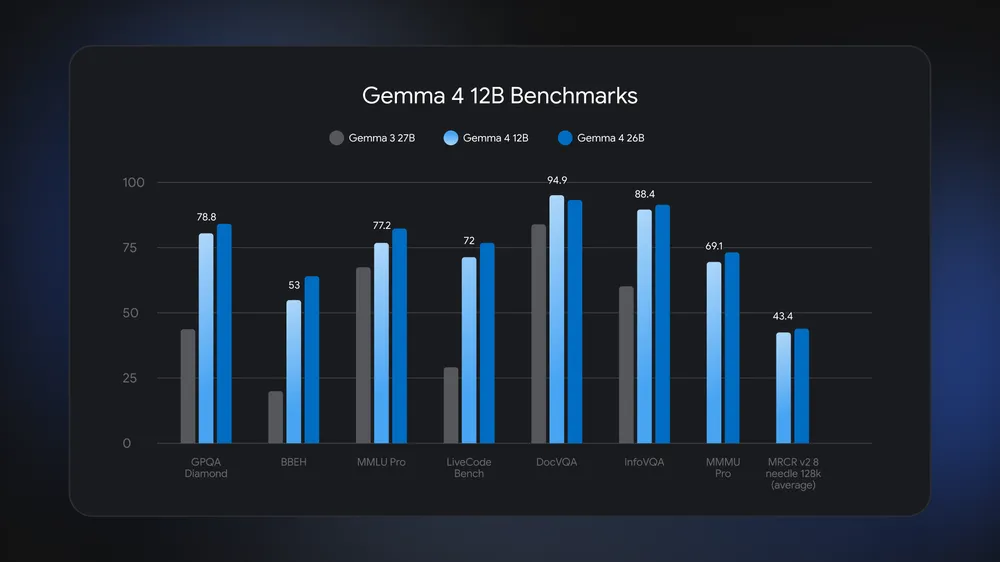
The benchmark numbers place the model more precisely than the marketing shorthand. On the Hugging Face card, the instruction-tuned Gemma 4 12B Unified reports 77.5% on AIME 2026 without tools, 72.0% on LiveCodeBench v6, and a Codeforces ELO of 1659. The same table reports 78.8% on GPQA Diamond, 69.1% on MMMU Pro, and 79.7% on MATH-Vision. By comparison, Gemma 4 26B A4B MoE reports 77.1% on LiveCodeBench v6, a Codeforces ELO of 1718, and 73.8% on MMMU Pro. "Near 26B" does not mean parity on every row. It means a mid-size local model is close enough on several reasoning, coding, and vision metrics to deserve evaluation in real workflows.
LiteRT-LM is where the local story becomes actionable. Google's AI Edge post says litert-lm serve starts a local OpenAI-compatible server, allowing standard SDKs and tools to call /v1/chat/completions. The example looks like this:
litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm gemma-4-12B-it.litertlm gemma4-12b
litert-lm serve
curl http://localhost:9379/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gemma4-12b,gpu",
"messages": [{"role": "user", "content": "Hello!"}]
}'
That endpoint is the developer-facing bridge. Aider, Continue, OpenCode, Open WebUI, and similar tools already know how to speak to OpenAI-style APIs. If the local server behaves consistently enough, a developer can replace a cloud API key with a local Gemma 4 12B endpoint for selected tasks. The model does not need to outperform frontier systems to be useful. Repeated summarization, confidential repository triage, screenshot analysis, chart interpretation, long-context compression, and pre-review cleanup can be routed locally while harder planning or final patch generation remains on a cloud frontier model.
Google AI Edge Gallery and Eloquent show the product direction. Google's AI Edge article describes the Gallery macOS app receiving a data-analysis prompt from Gemma 4 12B, producing Python code, running it locally, and generating a chart PNG. Eloquent, a macOS app for on-device dictation and Voice Edit, says Gemma 4 12B improved overall quality by more than 60% compared with the previous model in its own evaluation context. That 60% figure should be read as an app-specific internal result rather than an independent benchmark. It still shows where Google expects the model to land: local workflows that combine language, media input, and constrained tool execution.
The second developer-facing change is input range. The developer guide's video example samples five minutes of a Google I/O keynote at 1 FPS. The model receives 313 frames, a prompt, and audio, then explains the scene. That is different from a code-only or log-only agent. A local assistant can plausibly mix meeting recordings, product demo videos, chart screenshots, local CSVs, Python output, and repository context inside one workflow. The question for builders becomes less "can this model chat?" and more "which local inputs can be safely exposed to it, and which tools should it be allowed to call?"
It would be a mistake to call Gemma 4 12B a cloud frontier replacement. The research note for the Korean article captured mixed early community reactions. Reddit r/LocalLLM users welcomed the 12B size and audio support, but one user reported that a 6-bit version looped on a simple HTML calculator prompt. In r/artificial, users pointed to privacy, air-gapped development, and internal-document automation as advantages while noting that fresh information and tool access require a separate agent harness. Local inference reduces network cost and data export, but retrieval, tool calling, sandboxing, evals, and audit trails remain product responsibilities.
Hacker News attention was also substantial. On June 3, 2026, the item "Gemma 4 12B: A unified, encoder-free multimodal model" reached the front page with 917 points and 348 comments; a June 4 aggregate page recorded 1007 points and 379 comments. The discussion was less about the name and more about operating details: how far a 12B model can go locally, whether encoder-free design actually reduces latency in practice, and whether "16GB laptop" includes quantization choices and app overhead.
The 16GB condition deserves its own test plan. Google's launch says 16GB VRAM or unified memory, but a working developer laptop also runs an operating system, browser, IDE, vector database, agent harness, Python runtime, and background services. A 12B dense model's memory and quality change with quantization. Apple Silicon unified memory is not the same deployment target as every 16GB Windows laptop. Before adopting the model, a team should fix the runtime, quantization, prompt length, tool schema, batch size, and media-input format, then measure latency and failure modes under representative work.
Even with that caution, the release raises the baseline for local AI infrastructure. Local models have often been positioned as text summarizers or small coding assistants. Gemma 4 12B packages audio, vision, OpenAI-compatible serving, macOS apps, LiteRT-LM, llama.cpp, MLX, SGLang, vLLM, and Unsloth support into one launch surface. For a developer tool, "use the cloud API" and "use a local endpoint" can become a routing policy rather than two separate products.
The cost angle is concrete. Agentic coding tools burn tokens quickly because long context, repeated tool calls, multiple agents, and iterative review loops compound usage. A local Gemma 4 12B instance will not handle every coding task, but it can take over cheap helper work: compressing previous tool output, summarizing local files, extracting chart details, turning meeting audio into action items, or running a first-pass review on private code. A cloud frontier model can then be reserved for the parts that need stronger planning, security-sensitive judgment, or final patch writing. In that architecture, routing policy becomes as important as raw model quality.
The security story is also two-sided. Keeping data on device helps with confidential code, private documents, and regulated environments. But a local agent with file-system access, shell access, browser control, or Python execution moves prompt-injection and command-execution risk onto the user's machine. Google's AI Edge Gallery language around a secure sandboxed Python execution loop is a sign that the risk is not theoretical. Enterprises should evaluate local models alongside workspace permissions, network egress controls, tool allowlists, and audit logs, not only against a "no data leaves the device" checklist.
The broader message is that model suppliers want both the cloud and the edge. Google continues to sell Gemini API and Vertex AI paths while distributing Gemma through Hugging Face, Kaggle, Google AI Edge, and LiteRT-LM. One side captures managed frontier inference. The other side captures developer devices, on-device apps, and embedded product runtimes. As local models improve, AI product pricing and architecture will shift from a single API bill toward a mix of cloud routing, local fallback, privacy tiers, and hardware targets.
Developers evaluating Gemma 4 12B can start with four questions. Which repeated tasks do not need a frontier model? How far can quantization go before quality drops on those tasks? How much work is required to attach an existing OpenAI-compatible agent harness to a local endpoint? Does local execution make security review simpler, or does it introduce new device-level controls? Google's release does not answer those questions for every team. It does provide a model card, runtime, app path, and server endpoint that make the evaluation concrete.
The practical conclusion is not that a 12B local model replaces everything. It is that a 12B multimodal model is now packaged well enough to enter the developer's default tool list. A 16GB laptop target, Apache 2.0 license, 256K context, audio and vision inputs, and OpenAI-compatible local serving give AI teams a real comparison point between cloud-only agents and local-first assistants.