Gemma 4 12B Brings Local Multimodal Agents to 16GB Laptops
Google Gemma 4 12B targets local multimodal agents that can process images, audio, and text on 16GB-class laptops.

- What happened: Google released
Gemma 4 12Bon June 3, 2026.- It is a 12B dense multimodal model, and Google is positioning 16GB VRAM or unified-memory laptops as a first-class runtime.
- The weights are available on Hugging Face and Kaggle under the Apache 2.0 license.
- Architecture: Google calls the design
encoder-free, routing vision and audio inputs into the LLM backbone without separate heavy encoder towers. - Developer impact:
LiteRT-LM,llama.cpp,MLX, andgemma-skillsturn the release into a local agent harness, not just a model checkpoint. - Watch: Early HN testing with 4-bit GGUF on 12GB VRAM showed promise, but also reported low tokens/s and syntax errors that needed manual repair.
Google released Gemma 4 12B on June 3, 2026. The launch copy says the model brings "high-performance multimodal intelligence" to laptops. The developer-facing event is more specific: Google put image, audio, and text input into a 12B dense model and framed 16GB VRAM or unified-memory machines as a practical target for local agent workflows.

Gemma 4 12B sits between Google's edge-friendly E4B models and the larger 26B MoE tier. The Google Developers guide describes it as a dense multimodal model and lists four launch points: an architecture that avoids heavy vision and audio encoders, the first medium-sized Gemma model with native audio input, local execution on 16GB-class hardware, and a macOS desktop app experience.
In 2026, 12B parameters is not a headline number by itself. MiniMax M3 can talk about million-token context, and Microsoft MAI-Thinking-1 can emphasize a 35B-active MoE design. Gemma 4 12B is not a parameter-race story. It is a runtime-location story. The test is whether a multimodal agent loop that sees screenshots, listens to audio, edits files, and calls tools can move far enough down from cloud infrastructure to a developer laptop.
Google says the Gemma family has crossed 150 million downloads. That number matters because local model adoption is shaped by distribution as much as model quality. Hugging Face, Kaggle, Ollama, LM Studio, llama.cpp, MLX, vLLM, and SGLang all give developers a way to experiment before creating a managed endpoint. Google also mentions Cloud Run, GKE, and the Gemini Enterprise Agent Platform Model Garden, so the release is not framed as local-only. It is framed as a path from local harness to cloud deployment.
The architectural phrase Google emphasizes is encoder-free. In a traditional multimodal model, a vision encoder or audio encoder turns raw input into a feature representation before passing it to the language model. Gemma 4 12B reduces that stack. The developer guide says the 27 vision-transformer layers used in the existing medium-sized Gemma 4 model are replaced by a 35M-parameter vision embedder. A raw 48x48 pixel patch is projected into the LLM hidden dimension with a single matrix multiplication, and factorized X/Y coordinate lookup adds spatial position.
The audio path is even more explicit. Google says it removed the 12 conformer-layer audio encoder used in Gemma 4 E2B and E4B. A raw 16kHz audio signal is split into 40ms frames, or 640 floats, and linearly projected into the LLM input space. That does not mean the model accepts audio with no processing at all. It means the separate conformer-style tower is gone, and the model pushes audio into the same backbone path used by text and vision.
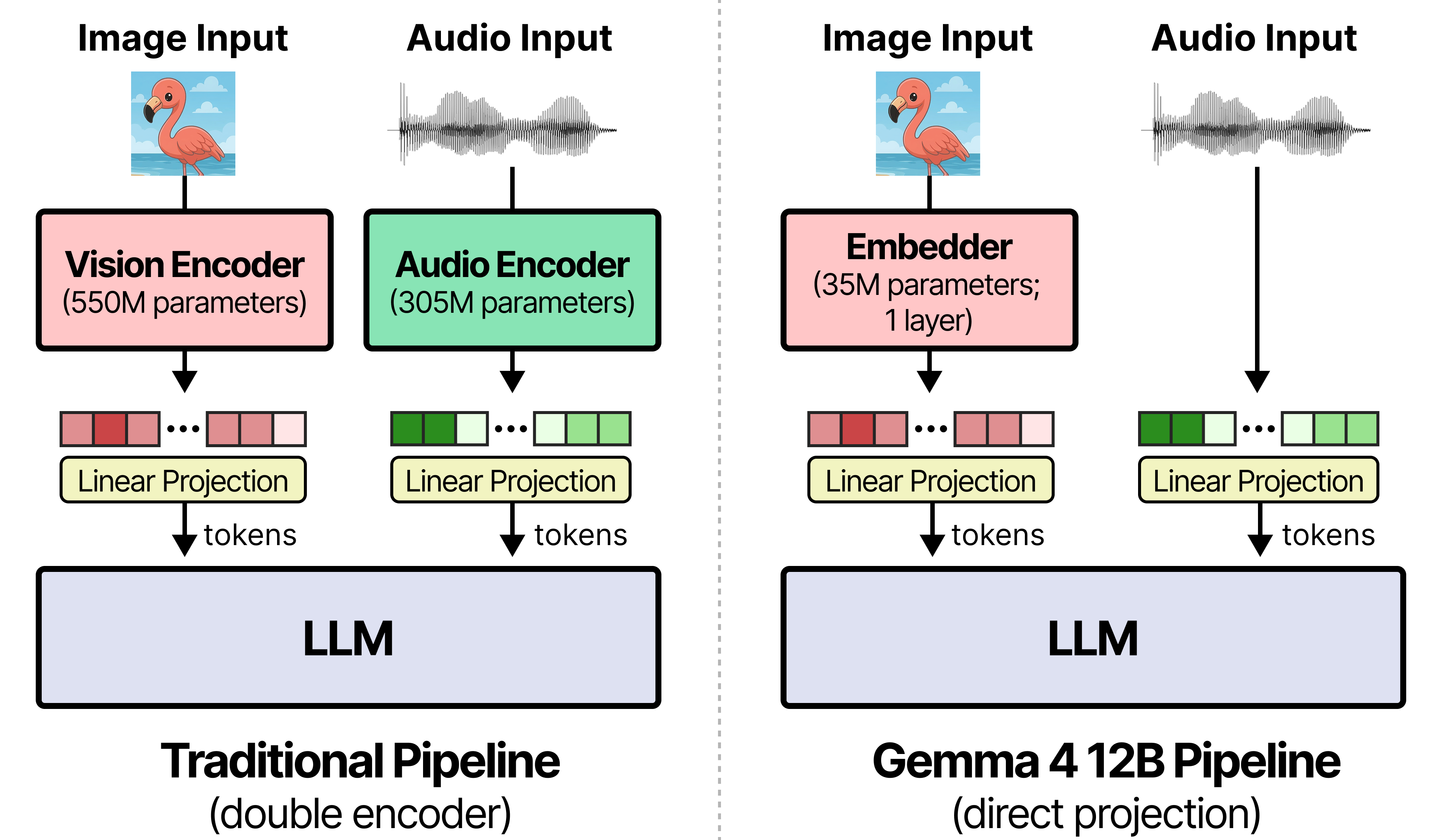
This design affects fine-tuning. Google argues that because vision, audio, and text inputs share the same weights, downstream adapters or full tuning can update the multimodal token loop together. A team tuning LoRA or Unsloth workflows for a local assistant does not have to coordinate separate frozen encoders in the same way. If a local agent needs to read an internal form image, parse a screenshot, and summarize a spoken note, one shared loop is operationally simpler than three modality-specific towers.
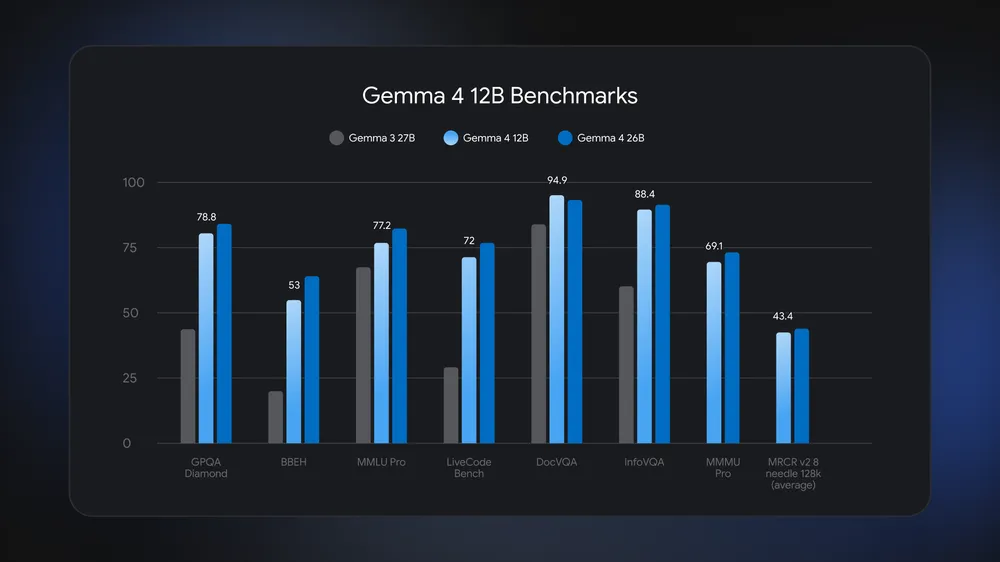
Google also makes performance claims. The launch post says Gemma 4 12B approaches the larger 26B MoE model on standard benchmarks while using less than half the total memory footprint. That claim should be read carefully. Benchmark proximity depends on the task set and inference configuration, while real local agents deal with longer context, tool-call recovery, lint/test feedback loops, image preprocessing, and audio robustness. The operating question is not only "does it score near 26B?" but "does it stay useful after quantization and repeated tool use?"
The most directly usable developer piece is LiteRT-LM. Google documents litert-lm serve as a way to run Gemma 4 12B through an OpenAI-compatible local API server. The example imports a LiteRT-LM artifact from Hugging Face and starts a local server.
litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm gemma-4-12B-it.litertlm gemma4-12b
litert-lm serve
OpenAI-compatible local servers are powerful because the agent ecosystem already knows how to swap endpoints. Continue, Aider, OpenCode, OpenClaw, and similar tools can point at a chat-completions-style server without rewriting their whole integration. Google putting that path in official documentation signals that Gemma 4 12B is meant to be more than a downloadable model. It is a local endpoint with prefix caching, desktop execution, and agent harnesses around it.
Google also published the google-gemma/gemma-skills repository under Apache-2.0. Its README includes a gemma-dev skill. The developer guide describes a local workflow that serves Gemma 4 12B through llama.cpp, connects it with OpenCode and gemma-skills, and builds a Gradio image-processing app. That example places Gemma beside coding agents such as Codex or Claude Code, but not necessarily as a direct replacement. It looks more like a specialist local model that a broader agent workflow can call.
The desktop story points in the same direction. Google AI Edge Gallery desktop runs Gemma 4 12B offline on Apple Silicon GPU and includes a secure sandboxed Python execution loop inside the chat experience. The Eloquent app uses Gemma 12B for Voice Edit conversational input. Local models are moving from simple chat windows toward small work environments that combine files, screenshots, voice, and code execution.
Cloud and local models split roles here. Frontier models still matter for complex planning, long-horizon reasoning, enterprise integration, and high-stakes review. A local 12B multimodal model fits better where privacy, latency, offline access, or repeated API cost dominates the decision. Field equipment photo classification, meeting-note summarization, personal document triage, screenshot-based bug reports, and test-failure image analysis are all cases where sending every input to a cloud model may be undesirable or expensive. A local model can become the filter, draft worker, or first-pass assistant before a cloud fallback takes over.
The early Hacker News discussion shows both the appeal and the limits. As of June 4, 2026 KST, the HN thread had passed 500 points and 180 comments in about four hours. One highly visible commenter said they ran a 4-bit GGUF quant with llama.cpp on a consumer GPU using 12GB VRAM and tested a minesweeper vibe-coding benchmark. They reported about 5 output tokens per second, described the result as decent, and still had to manually fix several trivial syntax errors.
That is a useful counterweight to the launch framing. "Runs locally on 16GB-class hardware" is an accessibility claim, not a full productivity claim. Developers still need to verify quantization quality, context length, sustained tokens per second, syntax reliability, and recovery behavior. Five tokens per second can be acceptable for experiments or background workers, but it feels slow for an interactive coding assistant. Syntax errors may be fine in a harness with linters and retries, but they become real cost when an agent edits files and calls tools repeatedly.
Another HN thread focused on the phrase encoder-free. One user objected that a 35M-parameter vision embedder is still a kind of encoding. Others clarified that Google appears to mean "no dedicated encoder neural network," not "no input transformation." That distinction matters. Gemma 4 12B does not pour raw pixels and audio straight into an LLM with no mediation. It replaces heavier ViT and conformer towers with projection and coordinate mechanisms that feed the LLM backbone more directly.
The audio comments are worth watching separately. One user pointed to the raw-audio-to-token-space projection as the more interesting part of the release. Vision-encoder reduction has appeared in multiple research paths, but a medium-sized open-weight model that combines native audio input, local execution, and an agent-development story is a product-level combination. For developers, the question is whether that path is robust enough for meeting audio, voice edits, spoken bug reports, or multimodal desktop agents.
The release also lands in a crowded agent market. OpenAI Codex and ChatGPT Sites are pushing code and web-app creation inside a workspace. Anthropic Claude Code emphasizes long-running coding tasks with dynamic workflows and subagent harnesses. GitHub Copilot app ties worktrees, PRs, review, and Agent Merge into a GitHub-native experience. Meta, Mistral, Qwen, and MiniMax continue to pressure the open-weight side with local execution and server-cost advantages. Gemma 4 12B is Google's way of reconnecting an open-weight multimodal model to that agent competition.
For practical teams, four checks come before adoption. First, test the exact hardware. A 16GB unified-memory Mac and a 16GB VRAM GPU laptop differ in memory bandwidth, thermal behavior, and quantization options. Second, define the modality. Image captioning, UI screenshot reasoning, audio transcription, and video-frame-plus-audio analysis have different preprocessing costs. Third, choose the agent harness. OpenCode, Aider, Continue, MCP tools, and custom agents recover from failures differently. Fourth, set the cloud fallback boundary. A local model should know when to hand work to Gemini, Claude, GPT, or another frontier model.
Security is not solved just because inference is local. Keeping data off a cloud API is valuable, but a local agent that can read files, run shell commands, open browsers, or execute Python moves the permission boundary onto the user's machine. Google AI Edge Gallery's sandboxed Python loop, LiteRT-LM's local server, and gemma-skills all raise the same operational question: what can the model read, write, and execute, and can a human audit that scope?
Cost accounting changes too. Cloud APIs expose token price and latency directly. Local models look free after download, but GPU memory, battery use, fan noise, quantization loss, support burden, and device heterogeneity are real costs. A "local-first" policy is easy when every developer has a fast M-series Mac. It becomes a support policy when one teammate uses a thermally constrained laptop and another uses a workstation GPU.
The practical significance of Gemma 4 12B is that Google documented local AI as an agent-development path, not as a side demo. Hugging Face checkpoints, Kaggle weights, LiteRT-LM, desktop apps, gemma-skills, Cloud Run, and GKE appear in the same release orbit. The model is not a replacement for frontier systems. It is a testable baseline for local multimodal agents that can act as privacy filters, offline assistants, cheap first-pass workers, and specialist tools inside a larger cloud-backed workflow.
The next measurements should be operational rather than only benchmark-driven. Developers need to compare 4-bit, 8-bit, and higher-precision runs on image and audio tasks. They need sustained tokens/s numbers on 16GB-class machines. They need to see whether OpenAI-compatible local endpoints behave reliably with existing coding agents. They need repo-level evidence that gemma-skills can complete real tasks without fragile manual repair. Google's June 3 release does not answer those questions. It gives builders a concrete local-agent testbed for asking them.