IBM Agentic CLEAR tracks agent failures across three levels
IBM Research released the Agentic CLEAR paper and open source tool for analyzing agent traces at the system, trace, and node levels.
- What happened: IBM Research released the Agentic CLEAR paper and an open source evaluation tool for LLM agents.
- The paper was submitted to arXiv on May 21, 2026, and appeared on Hugging Face Papers on May 27.
- How it evaluates: Agentic CLEAR reads execution traces and analyzes failures at the
system,trace, andnodelevels. - Supported stacks: The project covers LangGraph, CrewAI, MLflow, Langfuse, CSV traces, the
clear-evalpackage, and a dashboard.- IBM's project page reports experiments across four benchmarks, seven agentic settings, and tens of thousands of LLM calls.
- Builder takeaway: The next bottleneck in agent observability is not collecting more logs. It is classifying failure causes and ranking what to fix first.
IBM Research has released Agentic CLEAR, formally titled Agentic CLEAR: Automating Multi-Level Evaluation of LLM Agents. The paper was submitted to arXiv on May 21, 2026, and posted to Hugging Face Papers on May 27 under IBM Research. The authors are Asaf Yehudai, Lilach Eden, and Michal Shmueli-Scheuer. The problem statement is direct: agents now produce long execution traces, but developers still spend too much time reading those traces manually to understand why a run failed.
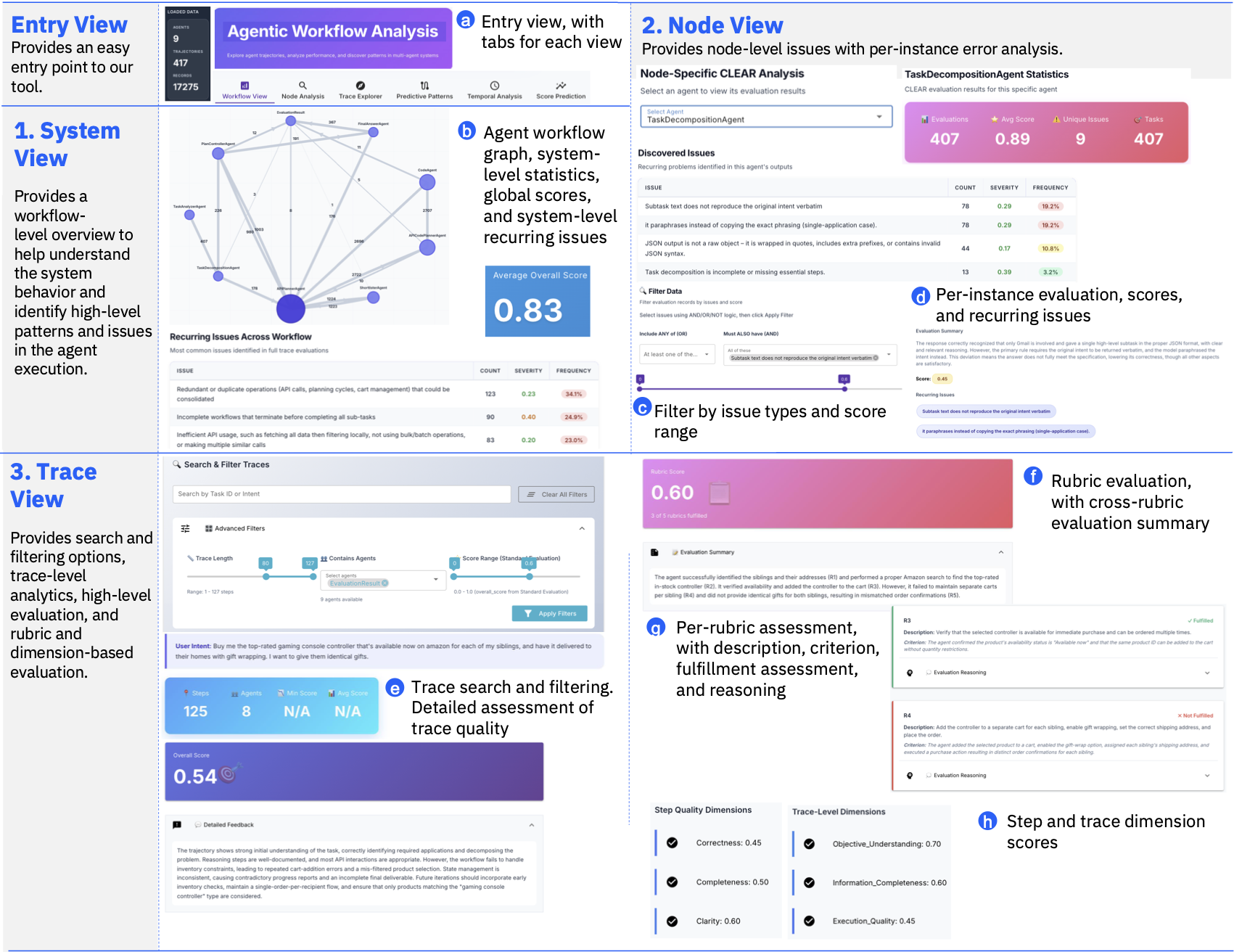
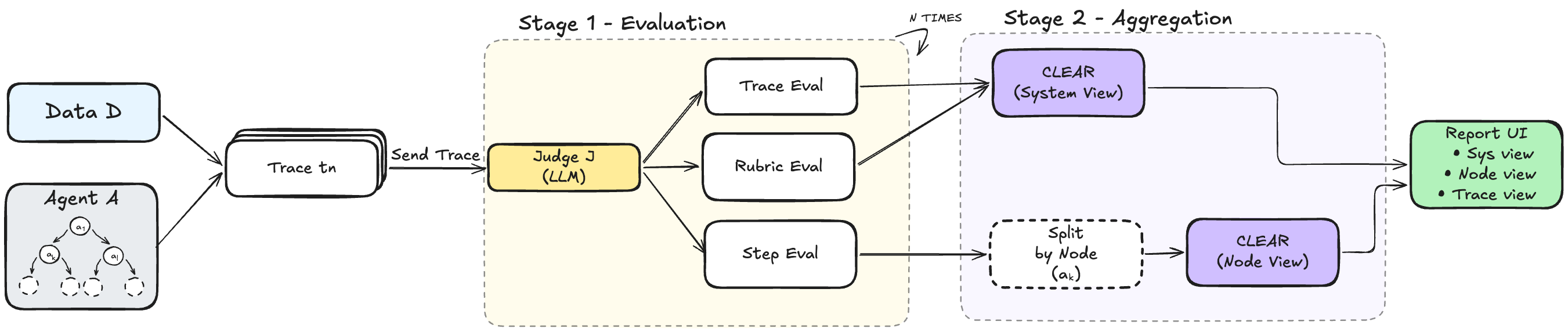
Agentic CLEAR targets that gap. It ingests execution traces from LangGraph or CrewAI agents recorded through MLflow, Langfuse, or CSV, then evaluates them at three levels. The system level looks for recurring failures across the full agent setup. The trace level evaluates a single task execution path. The node level isolates problems at a particular agent, tool call, or workflow component. Instead of stopping at "the success rate is low," the framework asks which stage failed, how often, and under which recurring issue label.
Recent agent evaluation work has centered on leaderboards and benchmark scores. IBM Research also published the Open Agent Leaderboard on Hugging Face to compare general-purpose agents. Agentic CLEAR sits beside that kind of comparison rather than replacing it. A leaderboard can tell a team which model or agent configuration scores higher before adoption. Agentic CLEAR reopens failed traces during development or operations and groups the repeated errors that explain the score.
The project page's TL;DR says observability platforms capture execution traces, but meaningful evaluation remains underdeveloped. That maps closely to what agent teams see in production. Langfuse, MLflow, and OpenTelemetry-style traces can show when a tool was called, what the latency was, and which span failed. As the number of traces grows, the amount a human can read shrinks. When 1,000 failed traces accumulate, a team needs ten common causes and reproducible examples, not a larger log viewer.
Agentic CLEAR's inputs and outputs reflect that goal. It accepts raw JSON traces or preprocessed trajectory CSV files. Its outputs include step-level CLEAR analysis, trajectory-level scores, rubric evaluation, and system/node/trace dashboards. The GitHub README shows installation through pip install clear-eval and a smoke test that evaluates three MLflow traces from a LangGraph research agent in roughly two minutes.
pip install clear-eval
run-clear-agentic-eval \
--data-dir src/clear_eval/sample_data/agentic/research_agent_traces/mlflow \
--results-dir my_results \
--from-raw-traces true \
--agent-framework langgraph \
--observability-framework mlflow \
--max-files 3 \
--eval-model-name gpt-4o \
--provider openai
run-clear-agentic-dashboard
The support matrix is pragmatic. IBM lists LangGraph with MLflow, LangGraph with Langfuse, CrewAI with Langfuse, and CSV-based custom traces. That framing matters because the paper is not trying to benchmark only one agent framework. It is positioning evaluation as a layer above any agent stack that already leaves structured traces. The README also says Agentic CLEAR uses LiteLLM as the inference backend, which lets teams connect providers such as OpenAI, Anthropic, WatsonX, AWS Bedrock, and Google Vertex AI.
The experimental setup on the project page is specific enough to understand the intended scope. AppWorld used the CUGA agent with a GPT-4o backbone across 417 traces. GAIA used HAL Generalist Agent with Claude 4.5 Sonnet and GPT-4.1 backbones, with 165 traces for each configuration. HF DeepResearch included 165 Claude 4.5 Sonnet traces and 117 OpenAI o3 traces. SWE-bench Verified used 50 Claude 4.5 Sonnet traces, and TAU-bench used 50 Claude 3.7 Sonnet traces. This is broader than a single browsing-agent demo.
The headline number in IBM's analysis is 195. The project page says Agentic CLEAR identified 195 unique recurring issues across all configurations. In AppWorld, the examples include execution flow management flaws, validation and precondition gaps, and blockage handling failures. It also separates incomplete execution and entity resolution weaknesses. At the node level, a specific TaskDecompositionAgent is shown assuming unsupported app capabilities or violating strict app constraints.
That distinction changes who owns the fix. A system-level issue may require a product policy change, a new planner design, or a different evaluation gate. A node-level issue may point to one tool wrapper, one subagent prompt, or one routing rule. A trace-level issue is closer to reproducing and debugging an individual failed run. Two agents can both fail 20 percent of tasks while requiring very different work if their failures cluster at different levels.
The GAIA and SWE-bench Verified examples illustrate why agent evaluation has to be domain-specific. In GAIA-style research tasks, IBM lists issues such as weak independent source cross-verification, unreliable references, premature conclusions before all search avenues are exhausted, and formatting specification violations. In SWE-bench Verified coding tasks, the recurring issues include malformed diffs, missing hunks, monkey-patching, missing regression tests, dependency misunderstandings, and failures to compile or test. Both are "agent failures," but they do not share the same repair path.
Agentic CLEAR does not rely only on a fixed taxonomy. The paper abstract argues that existing tools either stop at basic observability or depend on static hand-crafted error categories. Agentic CLEAR uses LLM-as-a-Judge evaluation over traces, then applies CLEAR aggregation to cluster recurring issues. In other words, the team does not have to define every possible failure mode before running the evaluation. The tool attempts to derive repeated patterns from execution data.
That design fits a 2026 agent environment where workflows change quickly. New tool calls, approval steps, retry policies, browser tasks, code patches, and research subtasks can alter the failure surface every week. A static list such as "planning error" or "tool error" may be useful for reporting, but it often hides the next engineering action. A dynamic issue cluster like "fails to verify source identity before using a citation" can become a concrete backlog item.
LLM-based judging still carries risk. A judge model can misread a trace, over-credit a plausible but wrong action, or miss a domain-specific success condition. Agentic CLEAR should be read as an error analysis assistant rather than a fully automated verdict engine. The practical workflow is that the tool groups candidate recurring issues, then engineers inspect representative traces and decide the fix order. Automating the analysis does not automate operational accountability.
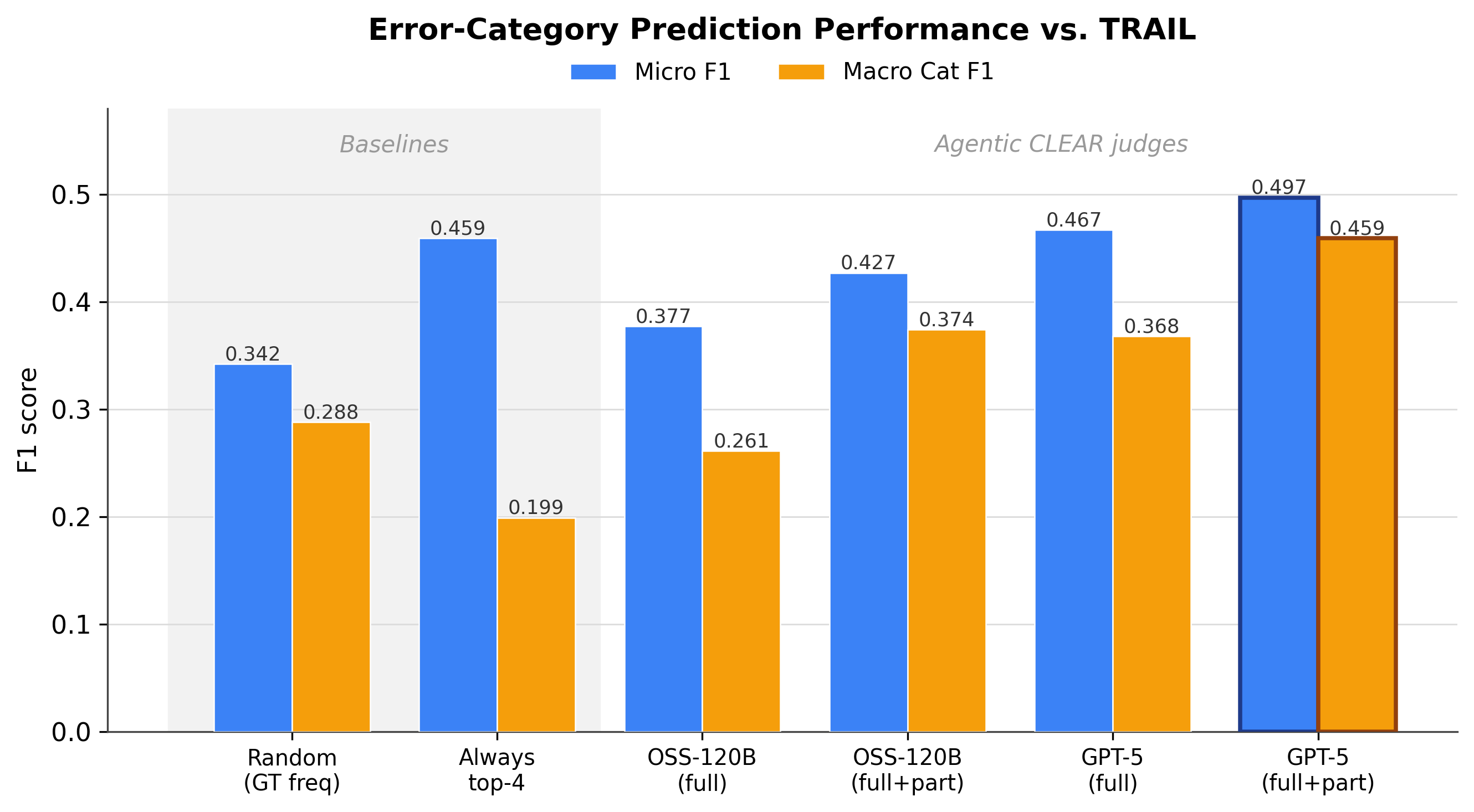
The score prediction results are useful because they avoid a one-signal story. The project page compares step-wise average scores, trace-level holistic judgment, and rubric-based criteria ratios for predicting trajectory success. According to IBM's description, trace-level evaluation is generally strong and reaches 0.890 AUC on AppWorld. The best signal still varies by benchmark and agent. For a production team, that means a single universal score is unlikely to explain every agent class.
The dashboard covers workflow view, node analysis, trajectory explorer, path analysis, temporal analysis, and score prediction. Workflow view shows the agent graph and transition counts. Node analysis shows CLEAR issues and score distributions by component. Trajectory explorer filters runs by length, agent, and score. Path analysis compares common successful and failed routes. Temporal analysis follows how scores change by step position.
That may sound like an APM product for agents, but the differentiator is the language of cause. A generic trace UI can show latency, error rate, spans, and token counts. Agentic CLEAR produces labels such as source verification gaps, broken patch output, or fails to isolate the minimal reproducible case. Those labels are closer to engineering work items. If a SWE-bench agent repeatedly omits regression tests, the fix might be a merge gate or verifier, not another planner prompt.
The open source details are worth checking before adoption. The IBM/CLEAR repository is licensed under Apache 2.0. At the Korean article's verification time on May 30, 2026, GitHub showed 45 stars and 10 forks. The PyPI package is clear-eval, requires Python 3.10 or newer, and showed version 1.0.8 with an October 22, 2025 release date. Because the Agentic CLEAR paper and project page were published in May 2026, teams should install the package and inspect command help to confirm which agentic modes are present in the released build they use.
The community signal is still small. Hugging Face Papers showed four upvotes, and the submitter left a comment that repeated the abstract-level explanation. Librarian Bot recommended related work such as Holistic Evaluation and Failure Diagnosis of AI Agents, AJ-Bench, Claw-Eval, and AgentEscapeBench. That is not a negative signal by itself. Research tooling for agent evaluation often reaches agent infrastructure teams before it reaches the broader developer audience.
Teams considering Agentic CLEAR should start with trace quality. Node names, tool call arguments, observations, final answers, and error messages need to be stable enough for evaluation. A LangGraph or CrewAI app whose tool wrappers emit generic span names will produce weak node analysis. A stack that records tool results, retries, exceptions, and human approval events in structured form gives a CLEAR-style analyzer more material for grouping failures.
The second adoption question is judge cost. Agentic CLEAR uses LLM-as-a-Judge evaluation, and the README example uses gpt-4o as the evaluation model. Long traces and multi-step agents can turn one failed trajectory into many judge calls. Most teams should start with sampling, nightly batches, release candidate evaluations, or regression suites rather than judging every production trace in real time. Full real-time evaluation can raise both latency and model spend.
The third question is how an issue becomes a product change. If Agentic CLEAR groups repeated source verification gaps, there are several possible fixes. The planner can require two independent sources. The browser or search wrapper can attach structured source metadata. A final-answer validator can block unsupported citations. A workflow policy can require a separate review node before user-visible output. The dashboard gives the starting point; the engineering team still chooses which control surface to modify.
Agentic CLEAR's larger message is that the unit of agent evaluation is changing. A single model score, pass@1, or task success rate is no longer enough for long-running agents. An agent can choose the wrong tool, repeat the same search, skip fallback after an intermediate error, patch the wrong file, stop before the final answer, or produce an answer that satisfies formatting while missing the user's request. Those failures all end as "incorrect," but they require different repairs.
In 2026 agent operations, observability is the baseline. Agentic CLEAR adds evaluation and failure clustering above that baseline. If a success-rate chart drops, the useful follow-up questions are which node degraded, which path leads to failure, and which issue label repeats most often. It is too early to know whether IBM's tool becomes a standard part of agent stacks. It is already a useful example of the question teams need to ask after they have collected the logs.