Claude Wrote 80% of Anthropic's Merged Code, Moving the Bottleneck to Review
Anthropic says Claude authored over 80% of merged production code. The harder question is whether review, tests, and incident prevention can keep up.

- What happened: Anthropic Institute published
When AI builds itselfon June 4, 2026.- As of May 2026, more than 80% of lines merged into Anthropic's production codebase were attributed to
Claude.
- As of May 2026, more than 80% of lines merged into Anthropic's production codebase were attributed to
- The numbers: Code merged per engineer is up 8x from 2024, and Claude Code reached a 76% success rate on open-ended tasks in May 2026.
- Builder impact: The bottleneck moves from writing code to review queues, test harnesses, incident prevention, and experiment selection.
- Watch the caveat: Anthropic says lines of code and employee estimates can overstate productivity and quality gains.
Anthropic Institute published When AI builds itself on June 4, 2026. The first number in the post is hard to ignore: as of May 2026, more than 80% of lines merged into Anthropic's production codebase were attributed to Claude. Before the Claude Code research preview in February 2025, that share was in the low single digits. The same post says a typical Anthropic engineer in Q2 2026 merges 8x more code per day than in 2024.
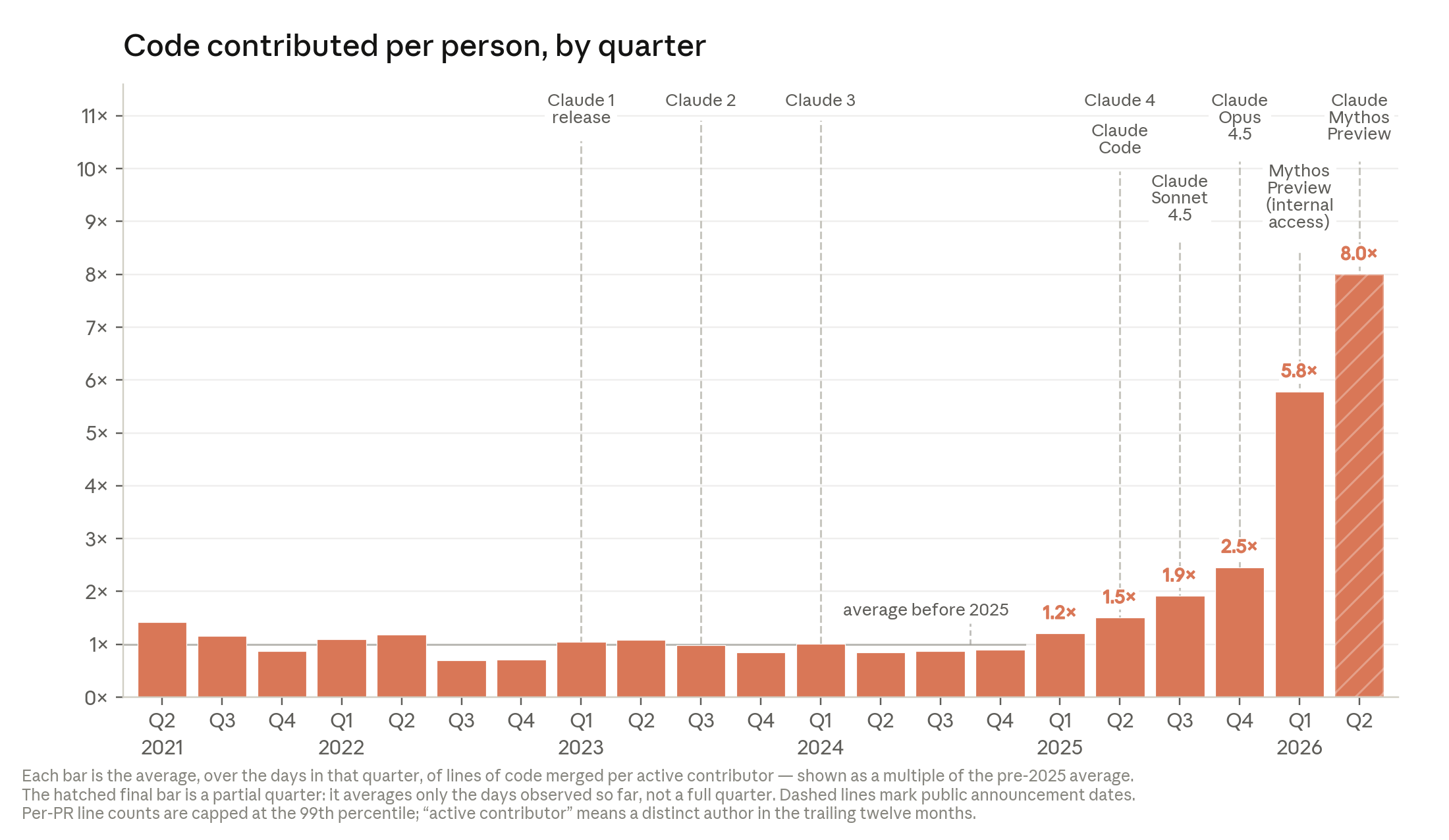
This is not a new model launch or a pricing update. Anthropic Institute is using internal data to ask whether AI is already accelerating AI development. The company writes that full recursive self-improvement has not happened yet and is not inevitable. It also argues that once AI systems can design and develop their own successors, security, monitoring, and behavior shaping become harder. For software teams, the nearer question is more operational: if code writing becomes 8x faster, did review and verification scale at the same rate?
Anthropic separates AI development work into engineering and research. Engineering means writing code, building infrastructure, and overseeing training systems. Research means choosing which experiments are worth running, interpreting results, and deciding the next idea. The company's conclusion differs by category. Claude can now handle underspecified engineering problems and search for a solution path, but Anthropic says a large gap remains in judging which goals are valuable. That gap is the current boundary between today's coding agents and full recursive self-improvement.
The code volume metric uses lines of code, a weak productivity proxy. Anthropic acknowledges in a footnote that the 8x increase in code merged per engineer may overstate real productivity. It also notes that employees are not rewarded by line count. Even with that caveat, the direction is visible. The 2023 to 2025 pattern of humans copying Claude snippets into editors is different from the 2025 to 2026 pattern of Claude editing files, running tests, and taking over longer tasks.
Anthropic's second internal datapoint is an employee poll. In March 2026, 130 members of Anthropic's research team were asked about output with Mythos Preview. The median respondent estimated roughly 4x the output compared with doing core project work without that model. Anthropic says that number should also be discounted because respondents may not have accounted for bias or the exact definition of the question. The post also cites recent METR work arguing that developers can overestimate AI productivity uplift. Still, code attribution, merge volume, and employee estimates all point in the same direction.
The most concrete case study is an API error-class cleanup from April 2026. Anthropic says Claude shipped more than 800 fixes and reduced a specific API error class by a factor of 1,000. The supervising engineer estimated that doing the work manually would have taken four years. This is narrower than the phrase "AI writes code fast," but it is closer to the work teams actually defer: stale cleanup, bug classes with scattered context, repetitive reproduction, and verification loops that are too tedious for a human queue.
Anthropic also reports Claude Code session success rates. A Claude judge evaluates whether a session completed the user's task without correction. On the most open-ended task category, Claude reached a 76% success rate in May 2026, up 50 percentage points over six months. The example Anthropic gives is an incident after a routine upgrade caused tens of thousands of training jobs to crash. An engineer gave Claude text context and cluster access. Claude tested environment settings, found an obscure debugging flag, and finished in about two hours what Anthropic says would usually take two to three days.
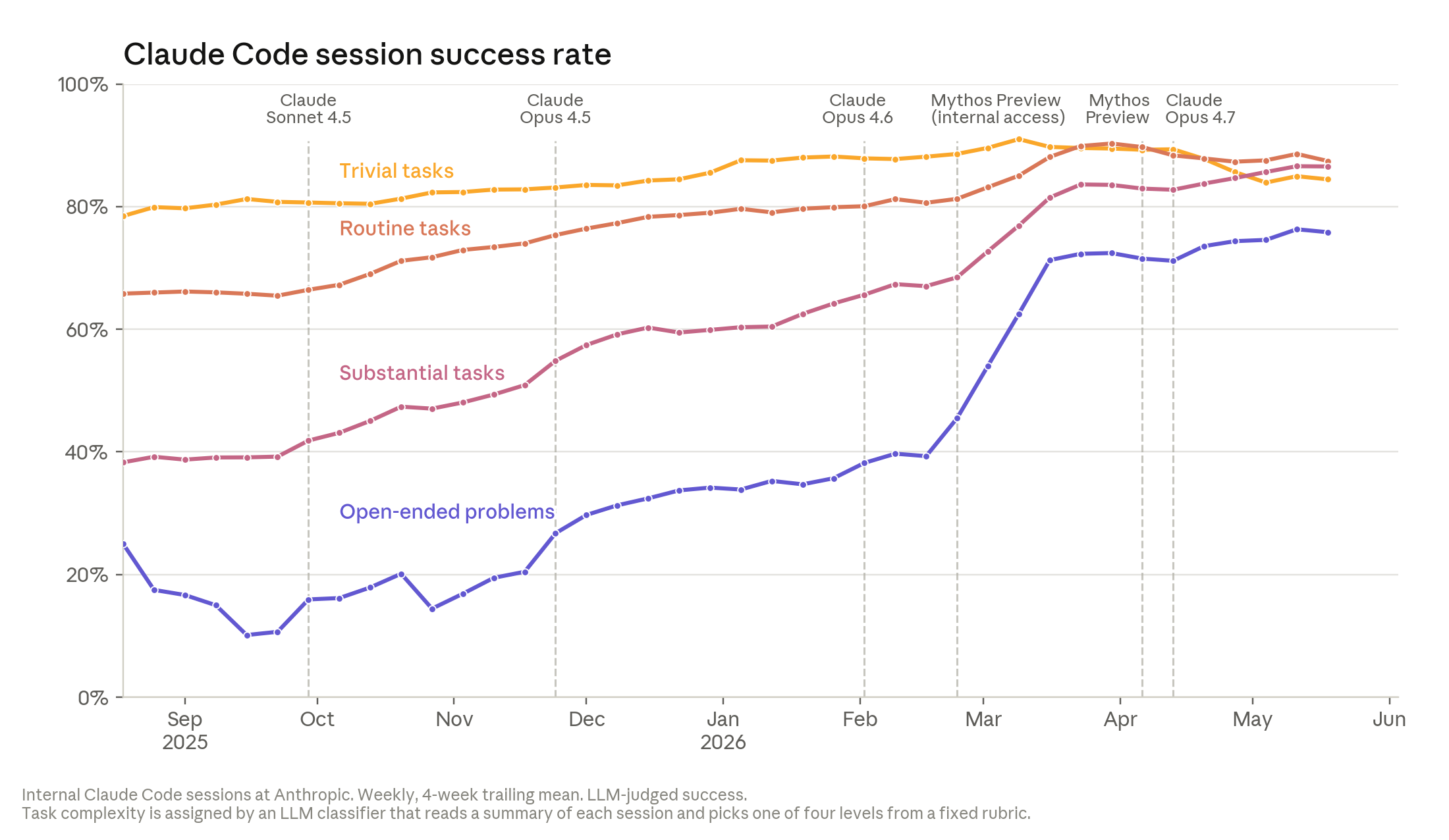
That is where the review bottleneck appears. Anthropic says Claude-written code was somewhat worse than human-written code in late 2025, is now roughly near parity, and many employees expect it to become better within a year. When code writing moves faster than code review, the merge queue becomes the place where humans judge Claude's output rather than the place where humans wait for implementation. Anthropic already runs an automated Claude reviewer over proposed changes to look for bugs, security flaws, and defects. In a retrospective analysis, the company says the reviewer would have caught about one third of past claude.ai incident bugs before production.
The lesson for development teams is not simply "turn on an AI reviewer." If the writing agent and review agent come from the same model family, the review process may share blind spots with the author. Teams need to decide how human sampling works, how detected defects become regression tests, and which independent signals can contradict the model. Compilers, type systems, integration tests, fuzzing, policy checks, code-owner approval, and incident postmortems all matter more when the author can create more diffs than the team can comfortably read.
The research-side numbers are just as aggressive. Anthropic gives each Claude release a fixed-goal optimization benchmark: make code that trains a small AI model run faster. In May 2025, Claude Opus 4 achieved about a 3x speedup over the starting code. In April 2026, Claude Mythos Preview achieved about a 52x speedup. Anthropic warns that the absolute multiplier should not be read as a real-world training speedup because the benchmark depends on how much room the starting code leaves for improvement. The meaningful comparison is within the same setup: one year moved the result from 3x to 52x.
Anthropic also describes an open-ended research project from April 2026. Claude-powered agents explored whether weaker models can supervise stronger models, an AI safety problem framed around weak-to-strong supervision. Two human researchers recovered 23% of the supervision gap in about one week. Agents recovered 97% using 800 cumulative hours and about $18,000 of compute. Anthropic adds two limits: the result did not cleanly transfer to production-scale models, and humans still defined the problem and scoring rubric. The agents executed the research loop, but humans chose the target and measured success.
Mapped onto a software organization, the bottleneck splits into four parts. First is review throughput. More generated pull requests mean more diff reading, architecture approval, and security sign-off. Second is the test harness. If an agent can patch code quickly, tests must cover real user workflows, migrations, permissions, and rollbacks, not only isolated units. Third is attribution. During an incident, the team needs to know which lines came from which agent session, prompt, tool permission, and command history. Fourth is experiment selection. When execution cost shifts from human time to compute, deciding what not to run becomes a leadership job.
The Hacker News reaction was fast and skeptical. The thread posted at 16:20 UTC on June 4, 2026 had 469 points and 628 comments when checked on June 5. Some commenters linked the post to possible Anthropic IPO positioning and criticized lines of code as a weak measure of productivity or quality. Others described real experiences where frontier models found edge cases that older coding assistants missed. A third set focused on compute, energy, data centers, code review, correctness, and human judgment as constraints that could slow recursive self-improvement.
That reaction matches Anthropic's own scenarios. The first scenario is a trend that bends into an S-curve because judgment, research taste, compute, energy, or interconnect bandwidth become stronger constraints than model intelligence. The second is a world where AI labs keep compounding efficiency gains while humans still choose research directions and judge results. The third is full recursive self-improvement by AI systems themselves. Anthropic says the second scenario fits current evidence best, but it does not rule out the third.
For developers, the second scenario is already close enough to change process design. Even if AI never fully builds its own successor models, agents that can handle bug fixes, cleanup, benchmark optimization, and incident investigation at scale alter the control plane of engineering. Branch protection, CI budgets, code-owner rules, security review SLAs, and incident ownership need to match agent throughput. As code generation gets cheaper, codebases can grow, diffs can multiply, and verification can become the slowest part of shipping.
Anthropic's slowdown and pause discussion can also be read in software-team terms. The company says it would be useful to have options to slow or pause frontier AI development, but only if there are ways to verify that other labs are not secretly racing ahead. Inside a smaller engineering organization, the same problem appears in miniature. Teams must decide which agents can hold production credentials, which tasks require human approval before execution, which benchmark gains count as real quality gains, and how review standards stay consistent across teams.
The sharpest part of Anthropic's post is not the phrase recursive self-improvement. It is the review bottleneck. Inside Anthropic, code production has already moved beyond the pace of human typing. The remaining human role is goal selection, result judgment, code review, and incident accountability. In an organization where Claude writes more than 80% of merged code, the human developer is not simply writing less. The human developer is judging more often.
If that judgment is slow or shallow, AI-generated code becomes a future incident backlog rather than a productivity gain. Teams adopting coding agents should track three logs before arguing over model names: who gave the goal, what files, commands, services, and credentials the agent could access, and which tests and reviewers approved the result after merge. Anthropic's numbers come from a large AI lab, but the operational question applies to smaller teams too. Once writing accelerates, the next bottleneck is verification.