Claude security harness shows a 7-step path from AI-found bugs to proof
Anthropic released Claude Code skills and a gVisor-based vulnerability discovery harness focused on verification, triage, and patch validation.
- What happened: Anthropic published the
defending-code-reference-harnessrepository.- It includes six Claude Code skills and an autonomous recon, find, verify, report, and patch harness for vulnerability discovery.
- Why it matters: The bottleneck in AI security automation is moving from finding bugs to verification, triage, and patch validation.
- Builder impact:
THREAT_MODEL.md, gVisor sandboxing, independent verifiers, PoCs, and dedupe become core units of security-agent workflows.- The README frames the repository as a reference implementation, not a maintained product.
- Watch: The autonomous pipeline runs target code, so credential mounts and egress controls need to be designed before any scan.
Anthropic has released a public repository called defending-code-reference-harness. According to the GitHub API snapshot used for the Korean article, the repository was created on May 22, 2026 and last pushed on June 2. Around 18:03 UTC on June 5, it showed 2,706 stars, 187 forks, and 2 open issues. The name can sound like another AI security scanner, but the README points to a narrower and more useful scope: Claude Code skills plus an autonomous reference pipeline for C/C++ memory vulnerability discovery.
The first thing to strip away is the product-launch reading. This is not a tool that a company should install, point at its whole codebase, and treat as a managed service. The README explicitly says the repository is not maintained and is not accepting contributions. For the managed option, it points readers to Claude Security. The news value is therefore not a new commercial scanner. It is Anthropic publishing part of the operating shape it learned from Project Glasswing, Claude Security, and partner security teams: skills, harness code, docs, sandboxing, proof artifacts, and patch checks.
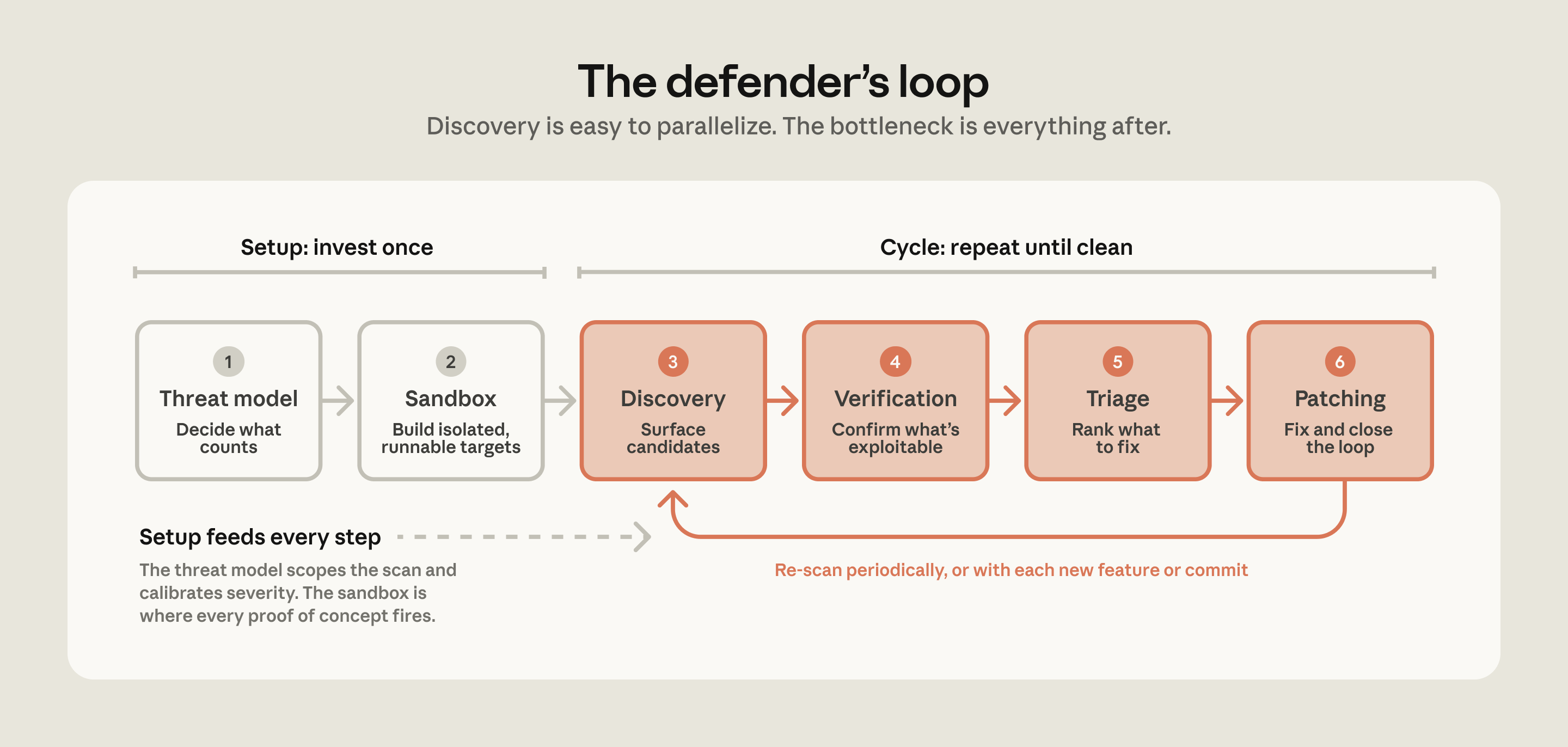
Anthropic's companion write-up starts from a concrete bottleneck. As model capability improves, vulnerability discovery becomes easier to parallelize. Verification, triage, and patching become the limiting steps. The same write-up says Anthropic's open-source scanning had disclosed 1,596 vulnerabilities as of May 22, 2026, and that 97 were patched within Anthropic's known scope. Those numbers are less interesting as a model victory lap than as a queueing problem: once AI can produce more candidate findings, how many can the ecosystem prove, prioritize, fix, and merge?
That framing connects directly to Anthropic's recent Glasswing work. On May 22, Anthropic said Glasswing partners had found more than 10,000 high or critical severity vulnerabilities. devlery has already covered that discovery volume, the patching bottleneck, and the ARiES and ATT&CK context. The new repository adds something different. It turns the same argument into file structure and command flow: build a THREAT_MODEL.md, run agents in a sandbox, require a separate verifier to challenge each finding, preserve the PoC, dedupe reports, and validate patches by trying to break them again.
The first surface is the Claude Code skills layer. The repository includes /quickstart, /threat-model, /vuln-scan, /triage, /patch, and /customize. /quickstart walks through the demo target. /threat-model reads code, docs, CVE history, and system-owner input to create THREAT_MODEL.md. /vuln-scan reads that threat model, divides the target into focus areas, and runs parallel review agents. /triage handles validation, duplicate collapse, and exploitability reassessment. /patch proposes diffs and asks an independent reviewer agent to check them.
The threat model is not decorative documentation in this design. Anthropic says false positives often come from models assuming the wrong trust boundary. If a model assumes an attacker controls a configuration file that is actually internal-only, it can label non-vulnerable code as critical. If it assumes an internet-facing service is internal-only, it can miss real risk. The companion write-up describes one partner case where model findings were 90% exploitable in systems with well-defined threat models, design docs, requirements, and constraints.
For development teams, the most immediately reusable artifact is THREAT_MODEL.md. In many security reviews, threat models live across spreadsheets, wiki pages, meeting notes, and oral knowledge. In Anthropic's loop, discovery agents and triage agents read the same versioned file inside the repository. "What counts as a vulnerability here?" becomes a maintained artifact rather than a one-line prompt. As agents rerun over time, that file becomes both scanner configuration and security-operations memory.
The second surface is the autonomous reference pipeline. The README and docs/pipeline.md explain that the harness is written around C/C++ memory vulnerability discovery and uses Docker plus ASAN. A representative command is bin/vp-sandboxed run drlibs --model <model-id> --runs 3 --parallel --stream --auto-focus. Results land under results/<target>/<timestamp>/. With --stream, the first report can appear within minutes under reports/bug_NN/. This file-first design is useful for long agent runs because transcripts, reproducer files, and reports survive a failed or interrupted session.
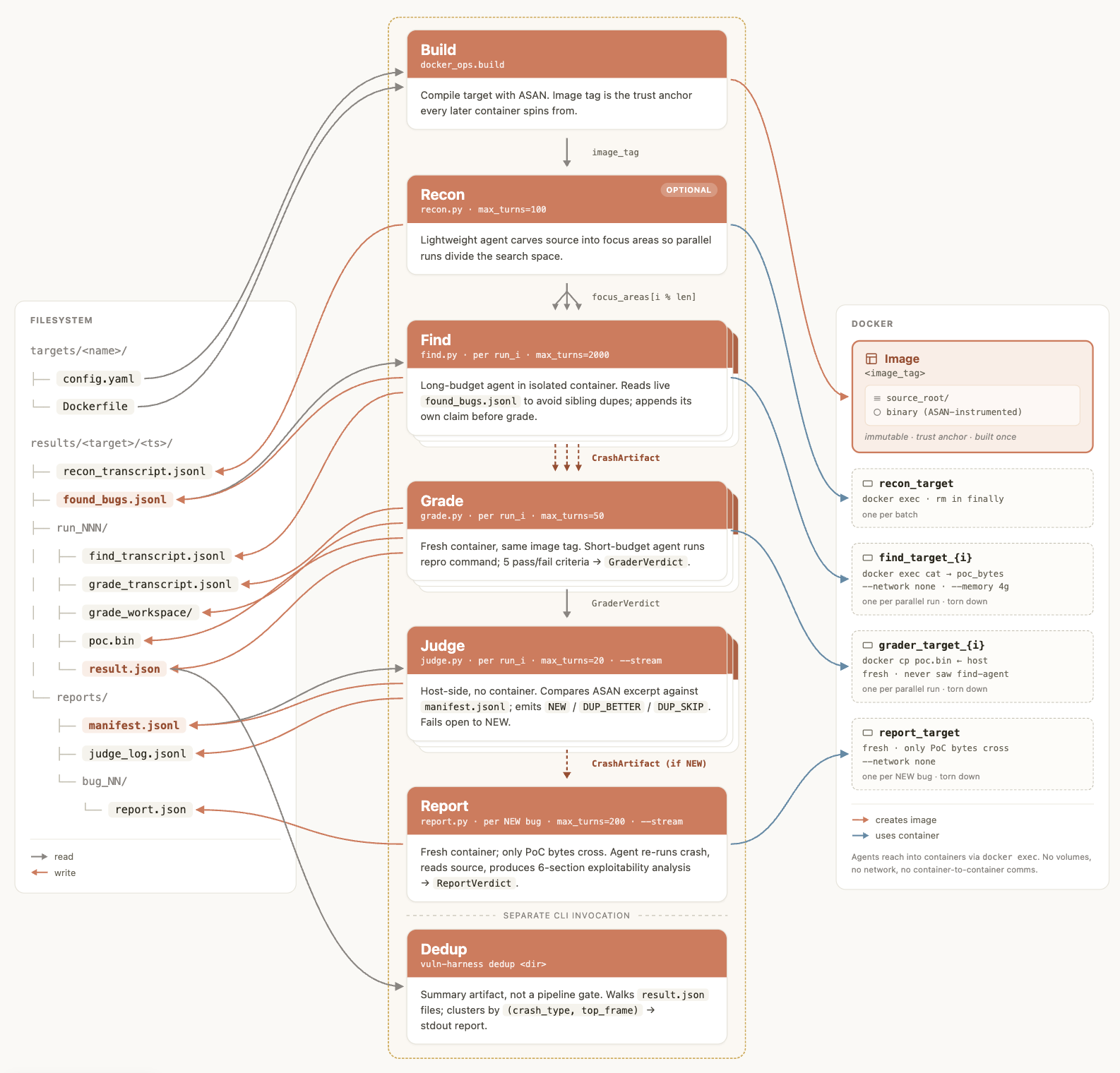
The pipeline breaks into seven stages. Build creates an ASAN-instrumented image from the target Dockerfile. Recon has an agent read the source tree and propose partitions such as eight distinct input parsers. Find runs multiple agents in isolated containers, where each agent reads source, creates malformed input, and executes ASAN binaries. A candidate finding must crash three times out of three before it moves forward.
The next stages are the heart of the repository. Grade runs a separate agent in a fresh container and asks it to reproduce the PoC. It checks whether the crash is real, whether it occurs in project code, and whether the signal is more than simple memory exhaustion. The find agent's reasoning is not handed to the verifier. The verifier receives the PoC bytes, which limits anchoring on the original agent's narrative.
Judge then compares the candidate against previous reports and decides whether it is a new bug, a duplicate, or a better reproducer for an existing issue. Report structures the exploitability analysis and sends it to another grader to score whether the evidence supports the claim. Patch creates a candidate fix and checks four things: the original PoC no longer crashes, the test suite still passes, the fix is minimal enough to preserve behavior, and a fresh find agent cannot easily discover a bypass.
That architecture is different from simply asking an AI to do a security review. Anthropic separates discovery, which increases recall, from verification, which increases precision. The companion write-up argues that asking the same agent to both find and refute a bug can suppress true positives. Its verifier therefore does not share the discovery agent's filesystem or conversation history. The prompt also asks the verifier to assume the finding may be a false positive and look for evidence against it. Anthropic says an adversarial verifier cut non-exploitable findings by roughly half, and requiring the verifier to produce a PoC pushed false positive rates near zero in one reported workflow.
The security boundary is not a footnote. docs/security.md says the autonomous pipeline runs target code and should be launched through bin/vp-sandboxed. That wrapper checks that gVisor is registered and that the allowlist proxy is running. Agent-spawning subcommands do not start outside the sandbox unless the user explicitly opts into --dangerously-no-sandbox. The docs warn that ordinary Docker with runc shares the host kernel, shortening the path from target code or agent action to host compromise.
docs/agent-sandbox.md makes the isolation model more specific. Agent Read, Write, and Bash tools operate on the container filesystem and shell, not the host filesystem and shell. Network egress is limited by default to api.anthropic.com:443. gVisor puts the container on a user-space kernel instead of the host kernel, while the vp-internal Docker network removes the normal internet route. Model API calls go through a small proxy container on the same network.
This design is not portable without work. The docs say gVisor runs directly on Linux, while macOS and Windows users need a Linux VM or the unsafe bypass flag. The default API endpoint is Anthropic's API, so teams using Bedrock, Vertex, Azure, or private routing need to adjust the egress allowlist. Setup and attack phases also need to be separated. Dependency downloads, tool installation, builds, and tests belong in a networked setup phase. The scan phase should load a prepared snapshot and close egress except for the model API route.
The line developers should keep from the docs is that constraints must be enforced through code and configuration, not prompts. Anthropic describes one team that told the model it had no network access while it could still fetch from GitHub. Another team saw an agent reply to a GitHub issue during a scan. Those are not necessarily malicious actions. They are authority-boundary failures. Agents use the capabilities they actually have. Telling an agent not to use the network is not the same as removing the route.
The patching loop is also more demanding than "generate a fix." Anthropic recommends writing a new test before the patch, confirming it fails on the vulnerable code, and then applying the fix. The system should confirm that the original PoC no longer crashes, the existing test suite still passes, and a new discovery agent cannot find the same class of bypass. The companion write-up notes that generated patches can be too narrow and can break real service dependencies. A security patch has to respect the trust boundary and compatibility surface, not only silence a crashing input.
The repository is a reference implementation because each organization has different languages, build systems, exploit witnesses, and severity criteria. The customization guidance uses ASAN crash signatures and crashing input files as the C/C++ example. In another stack, the witness might be an exception, a canary file, a DNS callback, an HTTP request sequence, a transaction list, or a test harness. The practical work is creating targets/<your-service>/, running a smoke test, and proving that the witness means what the team thinks it means.
Hacker News reactions picked up the same point. On June 5, 2026, the related HN discussion showed about 486 points and 137 comments at the time captured for the Korean article. Some security practitioners treated the repository like a shop jig rather than a finished product: a working aid that teams adapt to their target, interface, alerting path, and validation rules. Other comments widened the discussion to whether AI-era harnesses and skills will become portable assets like dotfiles, and how teams can move them without leaking company-specific policy or security assumptions.
That reaction is also a signal for the developer-tools market. AI coding-agent competition started with model names and IDE surfaces. In security, the harness is closer to the product. GitHub Advanced Security, Snyk, Semgrep, Wiz, and similar systems already manage findings, reachability, ownership, policy, and pull-request workflows. Anthropic's reference harness shows the extra units an LLM agent brings into that loop: transcripts, PoC artifacts, independent graders, sandbox snapshots, egress allowlists, generated patch review, and re-attack after the patch.
For teams evaluating this repository, the near-term question is not whether to run an autonomous vulnerability hunter against production code tomorrow. Three smaller questions come first. Does the repository contain a threat model and security policy that an agent can read? Are code-reading permissions and target-code execution permissions separated? When findings arrive in volume, is there a queue for owner assignment, duplicate collapse, severity reassessment, patch validation, and release-note work?
The repository lowers and raises expectations at the same time. It lowers them because the README says this is not a maintained product and will not work out of the box for every codebase. Claude Security is the managed path. It raises them because a prompt-only security review is no longer an adequate mental model for AI vulnerability discovery. An AI-found bug needs a PoC, an independent verifier, dedupe, exploitability analysis, patch validation, and re-attack evidence before humans can safely trust it.
The next metrics to watch are operational rather than social. How quickly can security teams port this reference shape to their languages and runtimes? How much do false positives and duplicates fall when verifiers receive only PoCs? What share of generated patches become merged PRs instead of abandoned suggestions? If Anthropic is right about the bottleneck, the next competition will not be won only by the model that finds the most candidate bugs. It will be won by the harness that turns those candidates into evidence, patches, and decisions that human teams can act on.