Google says Agentic RAG raises accuracy 34% by checking missing evidence
Google Research introduced Agentic RAG for Gemini Enterprise Agent Platform, with cross-corpus routing and a sufficient-context check before answers are finalized.

- What happened: Google Research introduced Cross-Corpus Retrieval powered by Agentic RAG for the Gemini Enterprise Agent Platform.
- The June 5, 2026 announcement describes the feature as a public preview offering.
- The number: Google reports up to a 34% improvement in factuality dataset accuracy over standard RAG in FramesQA experiments.
- The mechanism: A
Sufficient Context Agentchecks retrieved snippets, a draft answer, and missing evidence before the system responds.- In the cross-corpus setup, the planner chose among four corpora and reached 90.1% accuracy with average latency within 3% of the single-corpus version.
- Developer impact: Enterprise RAG design moves beyond vector search toward corpus routing, permissions, evaluation, and audit traces.
Google Research published a June 5, 2026 post on Agentic RAG inside the Gemini Enterprise Agent Platform. The release is not simply about retrieving better chunks. Google Research and Google Cloud describe a multi-agent workflow that decomposes complex enterprise questions, searches across more than one corpus, checks whether the evidence is sufficient, and loops back when the answer is missing required facts.
RAG is no longer a new pattern, but Google's failure case is familiar to teams that run enterprise knowledge systems. A user might ask, "What are the server specifications for Project X?" The first search may find a Project X document. If that document only contains a server ID, while CPU, memory, and region live in a separate asset database, a standard RAG pipeline can answer with the ID alone or say the information is unavailable. Google frames multi-source and multi-hop questions as the normal enterprise case, not an edge case.
This announcement differs from recent Google agent news because it centers on the retrieval loop rather than tool execution. devlery has already covered Gemini Managed Agents API, Gemini Enterprise Agent Platform, and Gemini File Search. This article is about a narrower product problem: how an agent decides whether it has enough evidence before finalizing an answer. In enterprise RAG, wrong answers often come from fragmented data, partial first-pass retrieval, and a missing distinction between "the information is absent" and "the system has not searched enough yet."
Google's architecture is not a single search engine. An orchestrator, or root agent, reads the request and decides whether one search is enough or whether the task should be broken apart. A planner agent chooses the information paths that need to be checked. A query rewriter turns the user's natural-language question into search-ready queries. Search fanout, or a RAG agent, sends refined queries to retrieval sources. A synthesis model then reads the gathered context and drafts the answer.
The component Google emphasizes is the Sufficient Context Agent. Before the answer is sent, that agent inspects three objects: the text chunks returned by retrieval, the intermediate draft answer, and the missing pieces relative to the original question. Google's medical example asks for discharge medications, dietary restrictions, and allergic reactions during a hospital stay. If retrieval covers medications and diet but says nothing about allergic reactions, the sufficient-context check flags the missing evidence instead of allowing a partial answer to pass.
That signal matters because RAG failure is not one category. Sometimes the information truly is not in the accessible data. Sometimes the retrieval query is too broad or pointed at the wrong corpus. In Google's example, the system can search again with more specific terms such as "rash" or "adverse events." A standard RAG pipeline may stop after the first retrieval result. Agentic RAG records the missing item as feedback and sends the query rewriter back into the loop.
Google's benchmark section uses FramesQA, a dataset derived from the FRAMES paper for multi-hop questions. One example asks which of the two most-watched TV season finales as of June 2024 was longer, and by how many minutes. The system must identify MAS*H and Cheers, find each finale runtime, and calculate the difference. A single retrieval pass can find viewership references while missing runtime evidence.
Google says the experiment used 824 FramesQA queries and 2,676 PDF documents. The vanilla baseline is Google RAG Engine, which Google describes as including an advanced retrieval engine, an LLM parser, and a re-ranker. The comparison includes single-corpus agentic RAG and cross-corpus agentic RAG. In the cross-corpus setting, Google adds three distractor datasets next to the FramesQA corpus, so the planner must choose among four corpora. That setup approximates a company where finance records, project-management documents, clinical notes, and support tickets live behind different corpus boundaries.
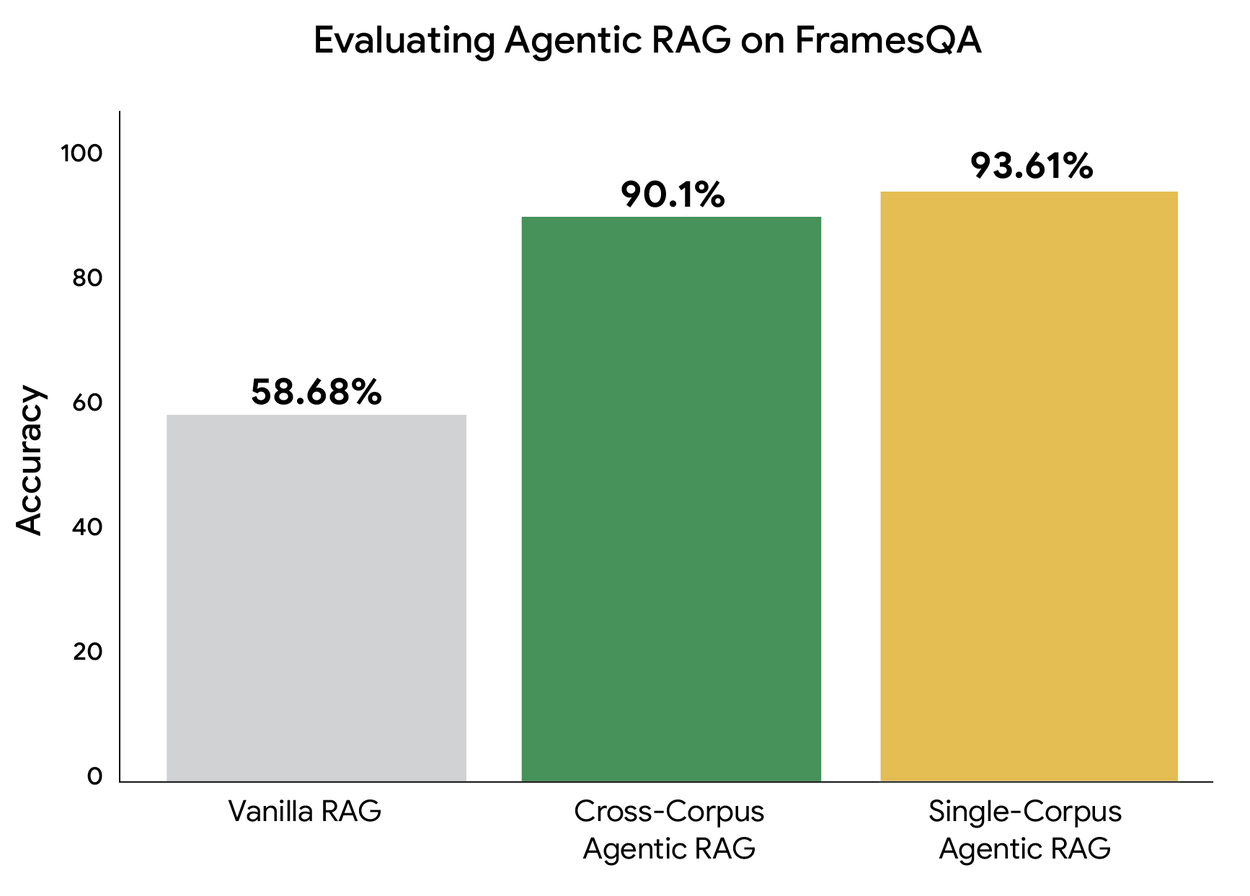
The reported results should be read in three parts. First, Google says factuality dataset accuracy improved by up to 34% over standard RAG. Second, in the cross-corpus setup, the system routed to the right source among four corpora and answered 90.1% of questions correctly. Third, Google says the average latency difference between single-corpus and cross-corpus versions stayed within 3%. The claim is that corpus routing and the retrieval loop can add reliability without a large average latency penalty in this benchmark.
The limitations are just as important as the headline number. Google evaluates accuracy with an LLM-as-a-judge comparison between system responses and ground-truth answers. The post also mentions a proprietary internal dataset but gives only a broad claim of better grounding and reasoning accuracy, not enough detail for independent reproduction. FramesQA is public, but real enterprise deployments add ACLs, stale documents, duplicate records, contradictory sources, PII redaction, regional data boundaries, and hundreds of connectors. A 90.1% result across four corpora should not be casually extended to every internal knowledge graph.
Still, the announcement is useful because it pushes RAG evaluation beyond retrieval hit rate. Many production RAG systems are still designed around whether a relevant chunk appears in the top-k results. Agentic RAG asks additional questions. Were all subconditions in the user request satisfied? Did the system rewrite the query when evidence was missing? Did another corpus need to be searched? Did the final answer carry a trace showing why the sufficient-context check passed? Retrieval quality becomes the loop's termination condition, not a single score attached to one step.
The most immediate developer consequence is corpus design. Standard RAG often starts by loading documents into one vector store and narrowing the search with namespaces or metadata filters. Cross-Corpus Retrieval treats each corpus as a routing target. If finance databases, HR policies, engineering design docs, and CRM notes are separate corpora, the planner needs a reliable description of what each corpus contains and when to use it. A weak corpus description can misroute a query even if the embedding model is strong. Better corpus descriptions, permission mappings, freshness signals, and evaluation examples become part of the retrieval system.
Permission handling cannot be bolted on later. Multi-source RAG lets one question cross several data boundaries. A user may have access to a Project X document but not the entire server inventory. In the medical example, medication records, nutrition guidance, and clinical notes may carry different access policies. Google's research post explains the retrieval mechanism, but production systems also need user identity, service accounts, corpus-level ACLs, row-level filtering, and audit logs. Every retry must inherit the authority of the original request.
The Gemini Enterprise Agent Platform packaging also matters. Google is presenting this as a platform public preview, not just a research demo. For enterprise buyers, the evaluation question is not only whether Agentic RAG works in isolation. It is whether agents, corpora, connectors, runtime, evaluation, and governance can be managed inside Gemini Enterprise. A May discussion on Reddit's r/googlecloud around custom agentic RAG pipelines raised exactly that deployment shape: ingestion endpoints, query-serving agents, and the Gemini Enterprise frontend may need to be separated rather than packed into one serving instance.
The competitive map is crowded. Microsoft ties Copilot Studio, Azure AI Search, Fabric, Purview, and Entra to work data and permissions. AWS connects Bedrock Knowledge Bases, OpenSearch Serverless, and agent runtimes. Mistral has put search tooling and RAG evaluation into its developer story. Chroma is pushing retrieval-specialized models such as Context-1 to improve the quality of context after retrieval. Google's position is to bring model access, RAG Engine, corpus routing, and agent orchestration into the Gemini Enterprise Agent Platform as a managed route.
Engineering teams evaluating this pattern should ask four concrete questions. First, can the knowledge base remain one vector index, or does the organization need corpus-level routing by business domain? Second, does telemetry distinguish "no information exists" from "retrieval did not search enough"? Third, does the evaluation set include multi-source questions rather than only single-hop FAQs? Fourth, what is the real latency budget after connectors, network hops, document parsing, permission checks, and retry loops are included?
The Sufficient Context Agent is not a universal hallucination shield. It depends on model judgment. Teams still need policies for contradictory snippets, conflicts between fresh and stale documents, source priority, and the maximum number of retry attempts. LLM-as-a-judge can help during evaluation, but production systems also need human-reviewed golden sets, regression tests, and domain-specific rubrics.
The practical conclusion is not "make every RAG system agentic." It is more specific: make missing-evidence detection a product requirement before answers go out. Retrieved chunks, draft answers, missing pieces, rewritten queries, and final citations should become traceable artifacts. When a RAG answer fails, "the model hallucinated" is not enough for the next incident review. The team needs to know which corpus was skipped, which query dropped a condition, and why the sufficient-context check allowed the answer.
Google's June 5 release puts the retrieval layer back in the foreground of enterprise AI agents. Long-context models and tool-calling agents still fail when work knowledge is split across data islands. Cross-Corpus Retrieval and the Sufficient Context Agent are Google's answer to that gap. For builders, the design shift is clear: treat RAG less like "retrieve, then generate" and more like a state machine for searching, checking evidence, tracking missing facts, retrying retrieval, and only then synthesizing an answer.