Anthropic maps 832 malicious Claude accounts to MITRE ATT&CK
Anthropic mapped 832 banned Claude cyber-abuse accounts to MITRE ATT&CK. The risk signal is shifting from skill level to execution orchestration.

- What happened: Anthropic mapped 832 Claude-related accounts banned for malicious cyber use to MITRE ATT&CK.
- The dataset covers March 2025 through March 2026, with 13,873 observations and 482 sub-techniques in the Red Team write-up.
- Why it matters: Medium-or-higher-risk actors rose from about 33% in the first six months to about 56% in the next six months.
- Anthropic points less to raw technical skill and more to account discovery, lateral movement, credential dumping, and MCP scaffolding.
- Builder impact: Agent security now needs logs for prompts, tool calls, MCP servers, credentials, approvals, and network egress, not just code diffs or shell history.
- Watch: The data is anonymized internal account telemetry. Treat it as an AI-abuse taxonomy proposal, not as a public IoC report.
Anthropic published a newsroom post on June 3, 2026 about mapping AI-enabled cyber threats to MITRE ATT&CK. The company also released a Frontier Red Team analysis the same day. The headline is about ATT&CK mapping, but the more useful conclusion for developers and security teams is narrower: Anthropic says the risk in AI-enabled attacks is moving from the number of techniques an actor uses toward the execution structure wrapped around the model. Its dataset covers 832 Claude-related accounts banned for policy violations between March 2025 and March 2026.
The release follows Anthropic's November 2025 report on an AI-enabled cyber espionage operation. In that earlier case, Anthropic said Claude Code had been manipulated to support reconnaissance, vulnerability exploitation, credential collection, and parts of lateral movement. The criticism around that report was predictable: there were few indicators of compromise, hashes, domains, IP addresses, or ATT&CK mappings that outside teams could validate. The new Red Team post does not expose victim identifiers, but it does publish a larger operating sample: 13,873 observations, 482 unique sub-techniques, and coverage across all 14 ATT&CK tactics.
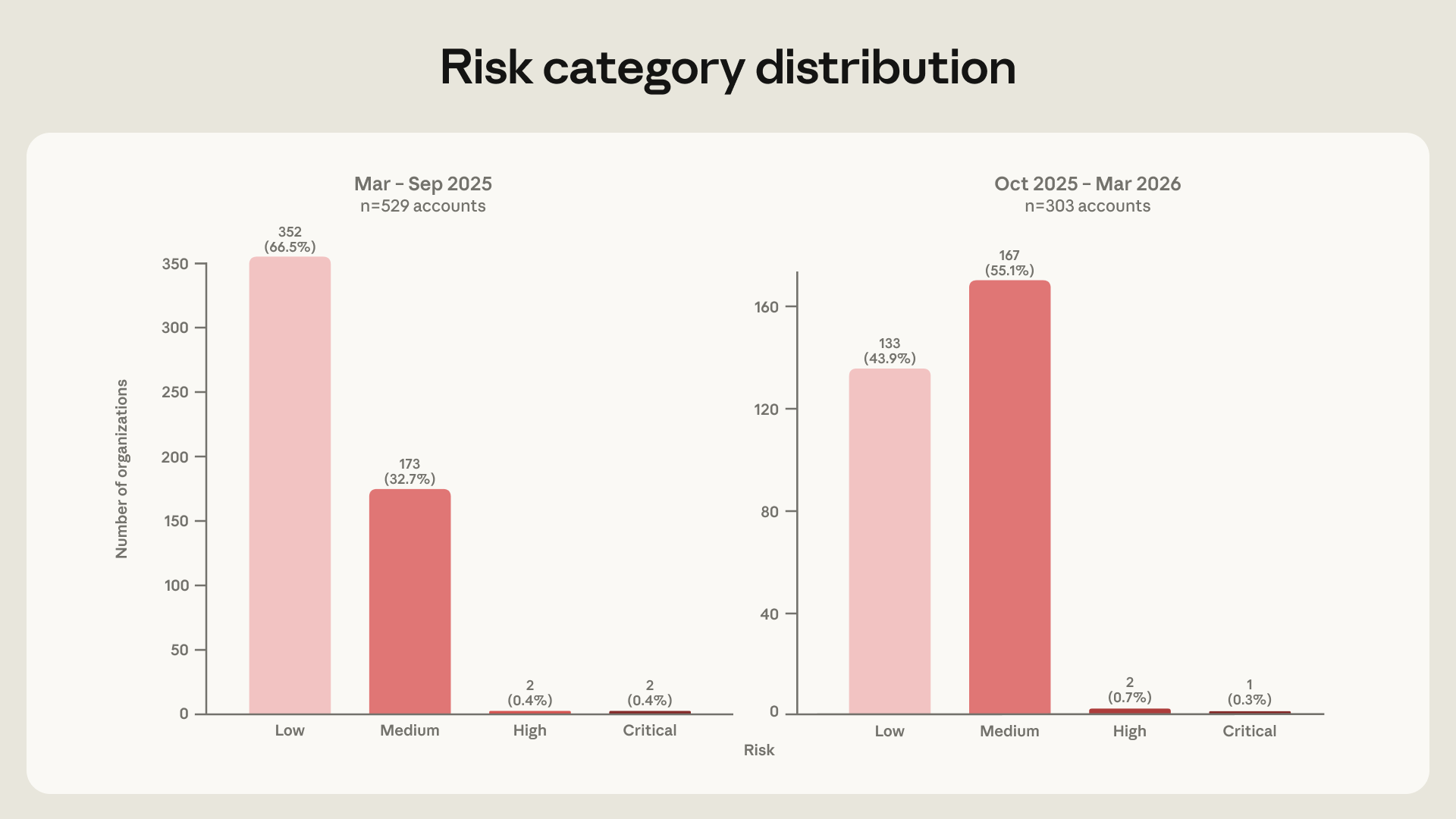
The 832 accounts are not every malicious account Anthropic has ever seen. Anthropic says it selected accounts with enough detail to assess attacker techniques. That constraint matters. The sample is not a measurement of total abuse across the Claude ecosystem. It is a set of cases that Anthropic's internal investigation teams could classify against MITRE ATT&CK v18. Because the company applies the same selection standard across the two six-month windows, the trend lines still give defenders useful operational data.
The most common behavior was attack preparation. The Red Team write-up says ATT&CK technique T1587, Develop Capabilities, appeared in 574 of the 832 actors. The malware development sub-technique appeared in 560 actors. Anthropic's newsroom post summarizes that as 560 out of 832 actors, or 67.3%, using Claude for malware development. The surrounding examples include malicious code generation, obfuscation, account-management automation, and canvas fingerprinting evasion.
Defense evasion was the largest tactic-level category. Anthropic says it observed defense-evasion behavior in 84.4% of the actors in the study. T1027, Obfuscated Files or Information, appeared in 64.7% of actors. T1562, Impair Defenses, appeared in 54.8%. T1055, Process Injection, appeared in 30.3%. Those numbers move the discussion beyond "AI can explain an exploit" and into model-assisted work on code and procedures designed to avoid detection.
The more interesting signal is not ordinary malware writing. Only 54 actors, or 6.5% of the sample, used AI for lateral movement. That group had a mean risk score of 56.4, roughly 10 points above the overall average of 46.8. Internal account discovery, remote services, credential dumping, web shells, and archive collected data were closer to the post-compromise behaviors that separated higher-risk actors from the rest of the sample.
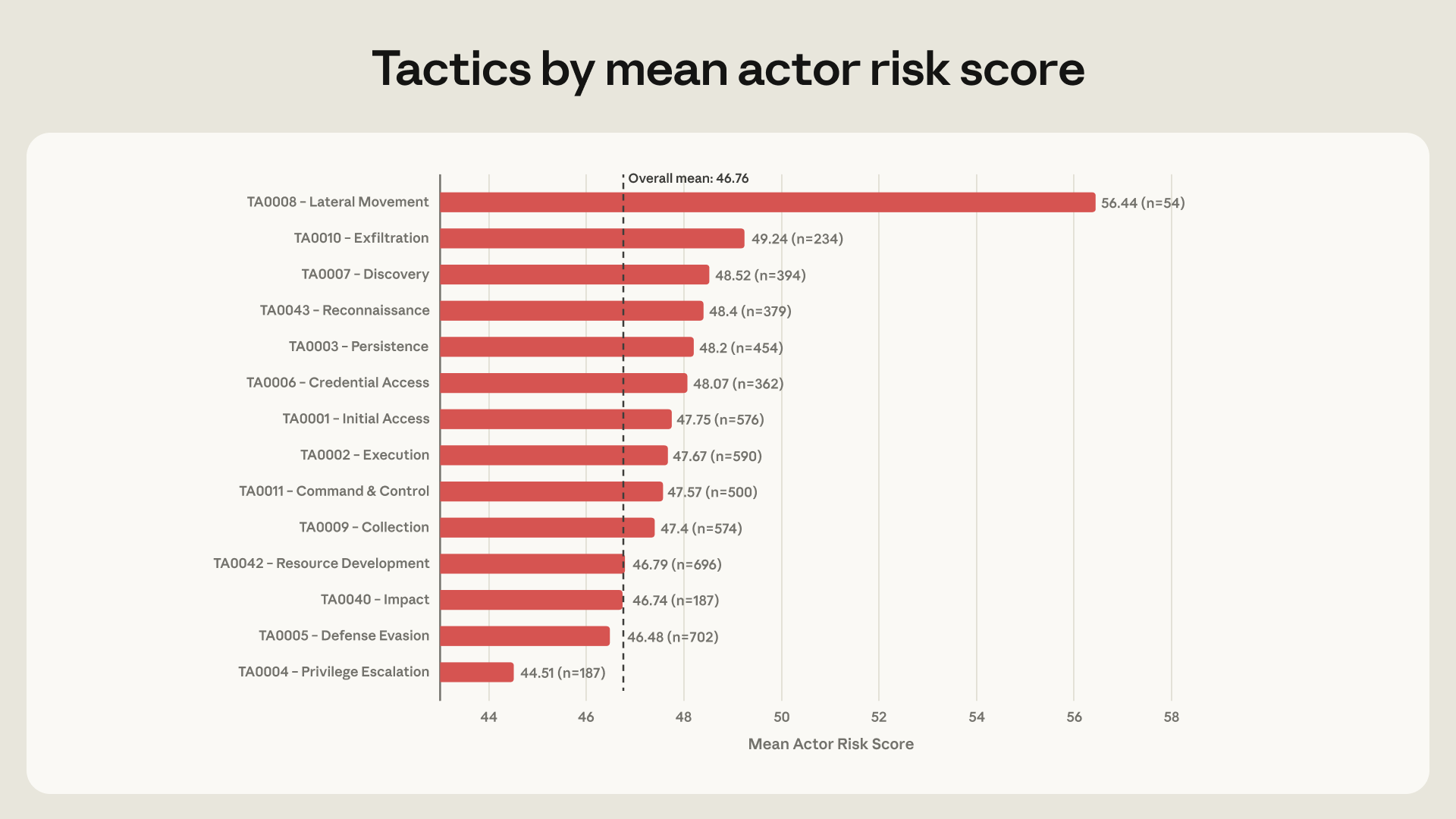
Anthropic calls its score ARiES, short for AI Risk Enablement Score. It splits risk into threat, vulnerability, and impact components weighted at 35, 35, and 30 points. The company says it deliberately avoided a multiplicative formula. A model interaction can deserve early detection even when the victim is unclear or the actor's intent is ambiguous, if the model materially increases operational capability. ARiES is therefore measuring how much the AI system enables attacker capability, not only whether a breach already succeeded.
The clearest trend is the change in risk categories. Anthropic's newsroom post says the share of medium-or-higher-risk actors rose from 33% in the first six months to 56% in the second six months. The Red Team post gives the more precise figures of 33.5% and 56.1%, about a 1.7x increase. Over the same span, Account Discovery increased by 8.9% and Automated Exfiltration increased by 6.2%, while Phishing declined by 8.6%. Anthropic reads this as a movement from initial-access wording and tooling toward internal-environment activity.
That pattern connects directly to AI coding agent security. The Red Team post says 80% of actors abused Claude Code. It would be easy to reduce that to "agentic coding tools are the dangerous interface," but Anthropic's analysis is narrower. The company says interface choice alone did not clearly separate high-risk actors from lower-risk actors. The same tool can be used for a single malware-generation step or connected to Kali Linux, MCP servers, credential stores, and internal-service discovery. The dangerous pattern is the scaffolding around the model.
The report's use of MITRE ATT&CK is also notable. Anthropic mapped 13,873 observations into existing ATT&CK tactics and techniques, but then says some of the most concerning behavior still lacks ATT&CK IDs. Autonomous kill-chain orchestration, real-time pivot decisions, and AI-directed execution without human intervention describe how multiple techniques are sequenced, not a single SSH login, credential dump, or web shell. ATT&CK can label the individual moves. It does not fully describe how an AI agent chooses the next move after reading tool output.
Anthropic brings back the November 2025 GTG-1002 case to make that point. The actor received the maximum risk score of 100, yet its raw number of ATT&CK techniques looked similar to some medium-risk actors. Anthropic says the difference was orchestration. In the company's account, the actor ran Claude Code inside Kali Linux and connected open-source penetration-testing tools through MCP servers. Claude then helped scan internet-facing services, identify internal admin portals, databases, and logging servers, and use an SSRF vulnerability to route commands into an internal cloud environment.
That description is still not a public incident-response package. Anthropic does not publish victim names, domains, hashes, packets, or full command logs. If you read this as an IoC report, it is incomplete. It is more useful as a taxonomy document from a model provider that can see abuse patterns on its own platform. Anthropic says it is in conversation with MITRE and provided some findings to Verizon's 2026 Data Breach Investigations Report. That level of disclosure is closer to an industry-framework proposal than a threat-intelligence feed.
The immediate question for engineering teams is where their own AI systems can execute. Blocking Claude Code, Codex, or another specific coding agent is not enough. A local shell, browser, MCP server, cloud credential, CI token, secrets manager, and internal document search can converge inside one agent session. At that point the AI is no longer only a code assistant. It is closer to an operator that can observe a system, decide on a next step, call a tool, and use the result to continue.
Logging needs to follow that shift. Traditional DLP and EDR tools inspect commands, files, processes, and network connections. Agent systems add prompts, tool calls, MCP server invocations, sandbox boundaries, credential access, and human-approval checkpoints. During an incident, the useful question is not only what command the model suggested. It is which tool the model directly called, what that call returned, and how that result influenced the next tool call. Anthropic's emphasis on orchestration outside ATT&CK exists because those chains are now part of the evidence.
The report also pressures defensive AI programs. Anthropic says it has deployed real-time cyber safeguards for its most capable models and blocks prohibited requests such as ransomware development or large-scale data exfiltration at the request level. It also routes dual-use activity through its Cyber Verification Program. That distinction matters because security researchers and attackers often use the same technique names. Access control for cyber work has to consider identity, stated purpose, execution environment, logging, and retention, not only whether a prompt contains a suspicious phrase.
The limits are just as important as the numbers. This is Anthropic's view of Claude abuse. Actors using OpenAI models, Google models, local open models, or custom fine-tuned systems are outside the dataset. Anthropic anonymizes the actors and does not reveal detection methods or raw data. The company also notes that the rise in higher-risk actors could reflect improved detection as well as a real shift in attacker behavior. Without that caveat, the claim "AI attacks became 1.7x more dangerous in a year" would be too broad.
The practical value is still real. AI security discussions often stall at whether a model can find a vulnerability or write malware. Anthropic's 832-account dataset asks the next question: what happens when vulnerability explanation, exploit writing, credential collection, internal discovery, result compression, and exfiltration preparation are tied together in one agent loop? The danger grows less from one impressive prompt and more from the model's ability to keep using tools across the kill chain.
For teams running AI coding agents, the report leaves three concrete checks. First, reduce the secrets and service accounts an agent can read by default. Second, manage MCP servers and shell tools by repository, network boundary, and credential scope, not merely by whether a tool is installed. Third, preserve agent-session logs that include plan changes, tool calls, credential access, human approvals, and network egress, not just the final code diff.
MITRE ATT&CK remains the shared language for security teams. Anthropic is not arguing that the language is wrong. It is saying AI agents need additional labels for behavior that spans multiple existing techniques. Until the standards catch up, organizations can add internal tags for AI-directed execution, autonomous pivoting, tool-augmented operation, and model-driven sequencing. Those tags will be imperfect, but they give incident responders something to query when a model uses output from one tool to choose the next.
This should not be read only as Anthropic defense marketing. Model providers see abuse early, but they also control what evidence becomes public. Outside researchers cannot reproduce the underlying dataset. The stronger takeaway is the change in the question. Evaluating an AI attacker now requires asking not only whether the actor is technically skilled, but whether the execution structure around the model lets attack stages connect automatically. That question applies to Claude, and it applies to every AI agent product that can call tools, reach credentials, and operate across a live environment.