MiniMax M3 puts 1M-token open-weight agents to a cost test
MiniMax M3 arrives with a 1M-token context window, agentic coding support, and an open-weight promise. The launch separates API access from verification work.

- What happened: MiniMax announced
M3on June 1, 2026, positioning it around a 1M-token context window and agentic coding.- API access and MiniMax Agent usage are open now, while the weights and technical report were promised for later in the launch week.
- Why it matters: Open-weight model competition is moving from chat scores toward the runtime cost of agents in
Claude Code, Cursor, and Cline-style workflows. - Watch: The 1M context window, MSA architecture, and benchmark charts are official launch claims until independent teams can test the released weights.
- Teams should compare API price, quota, tool-loop stability, latency, and failed-run cost on the same task set.
MiniMax announced M3 on June 1, 2026. The launch post introduces the model through its workload before its branding: a 1M-token context window, agentic coding, tool use, and long-horizon reasoning. MiniMax also says M3 can be used through MiniMax Agent and the API, and it names developer tools such as Claude Code, Cursor, and Cline as target surfaces.
The useful reading for developers is not simply that another large language model has arrived. MiniMax describes M3 as an open-weight model while opening the API and agent-product paths first. In the launch post, the weights and technical report were still scheduled for later in the same week. That means the confirmed facts at launch are the official API path, integration claims, and benchmark presentation. The still-open work is weight availability, license inspection, training details, and independent reproduction.
Open model competition has spent much of the past year arguing over parameter counts and general benchmarks. M3 frames the question differently. It connects a 1M-token context window to coding agents and long-running tasks, then asks whether an open-weight model can make agent loops cheaper than closed frontier APIs. Claude Code, Codex, Gemini CLI, Cursor, and similar tools already sit inside developer workflows. In that setting, an open-weight model is valuable less because it chats well and more because it can read a large repository, call tools repeatedly, recover from failures, and keep the bill predictable.
A 1M-token window is a cost question
MiniMax presents M3 with a 1M-token context window. That number is easy to treat as a feature checklist item: larger documents, larger repositories, fewer manual chunks. Agent deployments make the number more operational. A coding agent reads repository state, creates a plan, edits files, interprets test output, and often retries the same task after a failed patch. Each stage can call the model again with overlapping context.
A long context window only helps if two conditions hold. First, the model has to retrieve the relevant information inside the long input. Second, API pricing and latency have to make long inputs practical. If every long-context call is expensive, slow, or unstable at retrieval time, teams will still build chunking, search, summary caches, and scoped file selection around the model. M3's real evaluation is not "does 1M fit?" but "what does a failed agent run cost when the model is allowed to see a large input?"
The official launch lists MiniMax Agent, API usage, Claude Code, Cursor, and Cline as usage paths. That list matters because models are no longer evaluated only in standalone chat interfaces. In a coding harness, the model has to decide which files to read, when to ask for shell execution, how to interpret failing tests, and how much of a diff to propose before approval. The same model can produce different costs and failure modes depending on the tool surface, system prompt, and approval flow around it.
MSA points at the bottleneck
MiniMax describes M3 around a hybrid Mamba-Transformer MSA architecture. The official diagram shows a design that combines Mamba-style sequence modeling with Transformer attention. In the launch framing, that architecture is tied to long context, efficient inference, and agentic workloads.
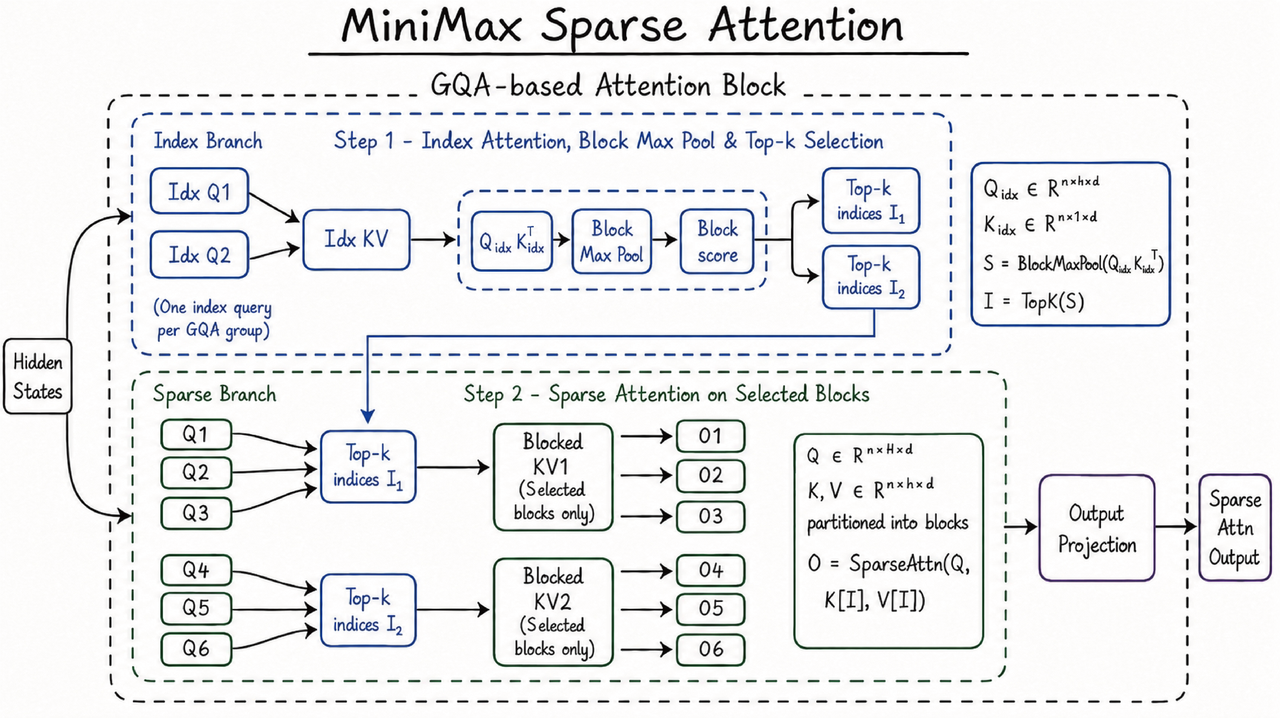
The architecture choice is relevant because the bottleneck for agents is not one-shot answer quality. A coding agent revisits the same repository across several steps. A document-analysis agent reads a source bundle, writes intermediate findings, and feeds those findings back into context. An operations agent may combine logs, runbooks, tickets, and metric snapshots in one task. Processing long sequences through full attention on every step can become expensive quickly.
Mamba-family architectures are commonly discussed as a way to reduce sequence-processing cost for long inputs. MiniMax's explanation that M3 blends that direction with Transformer attention is plausible and consistent with the launch's focus. The launch post alone does not answer how layers are split, how the training mix was constructed, or how long-context benchmarks were measured. Those details belong in the technical report and in third-party reproduction.
For now, MSA is best read as a clue about where MiniMax sees the pressure point. The company is not just claiming another chat assistant. It is claiming a model built for long inputs and long-running agents, where inference cost and latency decide whether a workflow survives outside a demo.
API access comes before the weights
The phrase "open-weight" needs careful handling in this launch. MiniMax calls M3 an open-weight model, but the launch sequence starts with API and product access. The weights and technical report were described as coming later in the week. That ordering changes how teams should evaluate the model.
API access is useful for fast experiments. A team can connect M3 to an existing coding-agent workflow, run small-repo and large-repo tasks, ask it to repair test failures, and compare model responses, latency, and logs against current providers. But the central promise of an open-weight model is different: self-hosting, private deployment, internal reproduction, and possibly fine-tuning. Those claims cannot be judged until the weights, license, quantization options, and serving recipes are visible.
The practical launch-week move is to separate smoke testing from migration decisions. Use the API to build a task set and collect traces. Freeze that task set so it can be rerun after the weights are available. A task that works well through MiniMax's hosted API may not behave the same way under a self-hosted serving stack, especially with 1M-token inputs, batching, KV cache pressure, GPU memory limits, and rate controls.
Token planning is an operations metric
MiniMax included a token-plan image in the official post. It positions M3 as a model for long-context training and agentic usage rather than as a generic chat release. For developers, the image raises a pricing and quota question more than a raw-capability question.
In an agent product, token planning is not just a model specification. It is an operations design. A code-review agent reading one pull request may include the diff, nearby files, test logs, style guides, and previous review comments. If the first patch fails, the task can repeat with more logs and additional file reads. A long-context model can reduce some retrieval plumbing, but it can also encourage teams to pass too much context into every call and inflate the cost of retries.
That makes M3's price competitiveness broader than a per-million-token line item. Teams need average task cost, failed-task cost, p95 latency, tool-call count, context-cache behavior, and rate limits. Official pricing is the starting point. The decision comes from workload traces. Coding agents in particular can spend more money on failures than on successes because a failed agent rereads logs, rewrites similar patches, and reruns the same validation loop.
Coding-agent integration sets the comparison surface
MiniMax's direct references to Claude Code, Cursor, and Cline are the practical hook in this announcement. The company is not only saying that M3 is available through an API. It is telling developers to plug the model into existing agent toolchains. That puts an open-weight model supplier directly inside the market shaped by closed coding-agent products.
Integration does not guarantee quality. In a coding agent, the model operates under many constraints: which file to inspect first, when to ask for shell execution, how to summarize test failure, when to stop, and how large a diff to create before user approval. A strong model can still burn tokens if the tool schema and system prompt produce noisy loops. A weaker model can outperform expectations in a narrow workflow if the harness keeps context scoped and validation tight.
The economic case for an open-weight agent model can therefore exist even if it does not beat the best closed frontier model on every leaderboard. Internal documentation refactors, repeated test migrations, monorepo exploration, and security-sensitive private deployments are candidates where cost, data boundaries, and context size may outweigh a small benchmark gap. The relevant metric is not a single score. It is how often the agent produces a clean diff before human review and how expensive the failed attempts are.
Benchmarks are a starting point, not a verdict
The official M3 post includes agentic coding and post-training benchmark images. That is expected for a model launch. Readers should separate two layers. One layer is what MiniMax wants the market to evaluate. The other is whether the numbers reproduce outside MiniMax's harness.
The first layer is already informative. MiniMax is positioning M3 around agentic coding, tool use, and long-context workloads rather than generic assistant chat. That matches the direction of the broader model market. Attention is moving from general knowledge tests toward SWE-bench-style coding tasks, terminal tasks, tool-use performance, long-context recall, and cost per completed task.
The second layer has to wait. External teams need the weights, technical report, evaluation harness, prompts, sampling settings, tool restrictions, repository snapshots, timeouts, retry rules, and patch-validation method. Coding benchmarks are sensitive to small setup differences. A different repository snapshot or retry budget can change the result.
The most accurate launch-week sentence is not "MiniMax proved M3 is the new best coding agent." It is that MiniMax has moved 1M-token context and agentic coding onto the public comparison surface for open-weight models. That is newsworthy, but it is not enough for a purchase or migration decision.
The quiet community response still asks the right question
The Korean research pass did not find a large standalone Hacker News or GeekNews discussion focused only on M3. Reddit and AI-community searches showed interest in the 1M-token window and the open-weight promise, but the common reservation was straightforward: wait for the weights and technical report before treating the benchmark claims as reproducible.
That quieter response is not surprising. M3 is closer to developer infrastructure than to a consumer chatbot launch. Infrastructure announcements are judged over the following days and weeks by repositories, licenses, serving examples, latency reports, quantization notes, and benchmark traces. An open-weight model starts its serious community evaluation when people can download it, run it, measure memory use, test vLLM or other serving support, and publish failures.
MiniMax appears to be speaking to teams looking for a way to reduce closed agent API costs rather than to users looking for another chat model. That audience reads launch pages, but it trusts notebooks, Docker images, license text, and workload traces more. M3's reputation will be shaped by those artifacts after the launch post.
What teams can test immediately
Teams evaluating M3 should divide their agent workloads into at least three groups: short coding questions, long repository exploration, and patch generation with tool execution. These workloads produce different failure modes. A model that answers short coding questions well may wander through irrelevant files in a large repository. A model that handles long context may still struggle when a shell command fails and the next patch requires disciplined diagnosis.
The second step is converting token pricing into task pricing. Input and output prices per million tokens do not describe the full bill. A pull-request repair has an average number of calls, a retry count, cache behavior, tool-output size, and failed-run tail cost. M3's 1M-token context can simplify that accounting if it reduces retrieval steps, or make it worse if teams pass the whole workspace into every loop.
The third step is evaluating deployment after the weights are released. Hosted API usage and self-hosted usage are different products. Self-hosting can improve data control and cost predictability, but it also makes the team responsible for long-context memory use, batching, KV cache behavior, GPU allocation, rate limiting, and observability. Open weights do not automatically create a free agent runtime.
The fourth step is preserving failure logs. Success rate alone hides the engineering work. Teams should label failures as retrieval errors, tool-selection errors, patch-validation failures, hallucinated API usage, or budget exhaustion. Open and closed models often differ more clearly in failure type than in average leaderboard score.
Open models are moving toward execution cost
MiniMax M3 is not a finished story at launch. The June 1 announcement bundles API access, product integration, official benchmarks, a 1M-token context window, and an open-weight promise. The weights and technical report are required before the open-model claim can be tested in the way developers actually need.
The direction is still clear. Open-weight model competition is moving from general chat leaderboards toward the execution cost of coding agents. If a model can handle long context, survive tool loops, reduce retries, and fit data-boundary requirements through self-hosting, it can pressure some closed frontier API use cases. If long context is too expensive, agent harnesses fail more often, or self-hosted serving costs are high, the launch charts lose force quickly.
For developers, MiniMax M3 is less an immediate replacement decision than a reason to reopen the agent cost sheet. Teams running Claude Code, Cursor, Cline, or internal agent platforms should test M3 API on the same task set they already use, then rerun the evaluation after weights are public. The visible headline is 1M tokens. The real competitive metric is the tokens, time, approvals, and failed logs required to produce one reviewed diff.