Xiaomi MiMo Code tests memory for 200-step coding agents
Xiaomi released MiMo Code, an MIT-licensed OpenCode-based coding agent that puts memory, checkpoints, and completion verification at the center of long-horizon development work.

- What happened: Xiaomi's MiMo team released
MiMo Codeunder the MIT license on June 10, 2026.- It is a terminal coding agent built on OpenCode, and the official write-up frames long-horizon work around
computation,memory, andevolution.
- It is a terminal coding agent built on OpenCode, and the official write-up frames long-horizon work around
- The numbers: Xiaomi reports an internal A/B study with 576 developers, 474 private repositories, and 1,213 comparison pairs.
- The company says MiMo Code was near 50% win rate against Claude Code on tasks under 200 steps, then moved above 65% on tasks beyond 200 steps.
- Developer impact: the release makes checkpoint writers, file-based memory, independent goal verification, and executable workflows first-class coding-agent features.
- Reality check: the benchmark and A/B claims come from Xiaomi's own publication, so outside reproduction on real repositories is still the test.
Xiaomi's MiMo Code is hard to read as just another AI coding CLI. The official blog post, published on June 10, 2026, introduces it as a terminal-based coding agent for "long-horizon automated programming tasks." The GitHub repository is open under the MIT license, and the README describes the project as a fork built on top of OpenCode. That makes the announcement closer to a runtime release than a model release. The most important part is not the model call itself, but how the agent remembers a goal after dozens or hundreds of tool calls.

The timing is useful context. In the same week, GitHub pushed Agentic Workflows toward natural-language Markdown that generates Actions YAML, and Cohere released North Mini Code as a small-active coding model for agentic software engineering. MiMo Code asks a different question. Instead of "which model is smarter?", it asks who stores state during a long task, when that state is re-injected, and who decides that the work is actually done. The comparison unit in coding agents is splitting into model, runtime, memory, verifier, workflow, and recovery policy.
Xiaomi starts with long-context dilution
MiMo's problem statement is simple. For a short edit, such as a fix that takes fewer than 10 turns, feeding the whole conversation history back into the model may be enough. After dozens of turns, tool outputs, code snippets, test logs, and failed attempts fill the context window. Some of that history must be summarized or dropped. A plain summary tends to preserve nearby information and weaken distant constraints. Xiaomi compares this to the dilemma of recurrent models such as Mamba: a state exists, but the model cannot arbitrarily revisit whatever it needs at the right moment.
The second failure mode is more operational. Even when the context window is large enough, a long input can dilute instruction following. The original user intent, repository rules, prior failures, security constraints, and test requirements get buried among tool logs. MiMo divides that bottleneck across three time scales. Computation governs the quality of a single turn. Memory governs continuity inside a session. Evolution governs what the agent learns across sessions.
That framing treats the coding agent as a stateful runtime, not as a CLI wrapper around a language model. The OpenCode base matters here. The README says MiMo Code keeps OpenCode's multiple providers, TUI, LSP support, MCP support, and plugin system. Xiaomi then adds persistent memory, intelligent context management, subagent orchestration, goal-driven autonomous loops, compose workflows, and dream/distill mechanisms. The company is not only publishing a benchmark table. It is attaching long-running behavior to an existing open-source agent surface.
Max Mode spends parallel compute before acting
The first computation feature is Max Mode. According to Xiaomi's blog, Max Mode creates N=5 candidate solutions for each turn by default. The candidates independently produce reasoning and tool-call plans, but they do not execute those actions. The same model then acts as a judge, compares the reasoning process and action plan, and selects the most robust candidate to run.
Xiaomi says Max Mode improves SWE-Bench Pro performance by 10-20% over single sampling, while consuming roughly 4-5x more tokens. That tradeoff is the product design in one sentence. In coding agents, one bad file edit can contaminate the next 20 tool calls. Spending extra test-time compute before executing a turn is a way to reduce cumulative error in longer tasks.
The feature is still an option, not a free default. Xiaomi says it must be enabled manually in configuration. Developers should read it as a risk-control mode for difficult work, not as the baseline cost of every issue. A migration, architecture rewrite, or production incident may justify 4-5x token usage if it prevents a failed trajectory. A routine typo fix probably does not.
Goal verification separates doing from judging
The second computation feature is Goal. Xiaomi describes early termination as a common long-task failure. An agent can look at partial progress and say it is done, or it can ask the user a question and stop in the middle of an autonomous run. With Goal, the user sets a natural-language stopping condition such as "all tests pass and the code has been committed." When the working agent tries to finish, an independent model call reviews the full conversation history and actual tool outputs against that condition.
The verifier does not participate in the work. That separation matters because the worker model is less able to soften the criteria after producing its own result. Xiaomi says false blocking is more common than false passing, usually because environment issues make already-satisfied conditions look unresolved. It also says the infinite-loop probability is below 0.5%, with automatic termination available at a limit.
The practical question is which goals leave evidence. Goal verification is strongest when it can inspect test output, commit state, diff state, or command logs. It is weaker when the condition is "the UI feels good" or "the quality is high enough." MiMo Code's useful contribution is that it names premature completion as a runtime-level failure mode and gives it a separate judging step.
The checkpoint writer is the center of the memory system
Memory is the main part of the announcement. Xiaomi separates the logical session from the physical context window. A task may continue logically, but the model window eventually fills. MiMo Code does not wait until the window is almost full and then ask the main agent to summarize everything. It creates checkpoints earlier, around 20%, 45%, and 70% of the configured context budget.
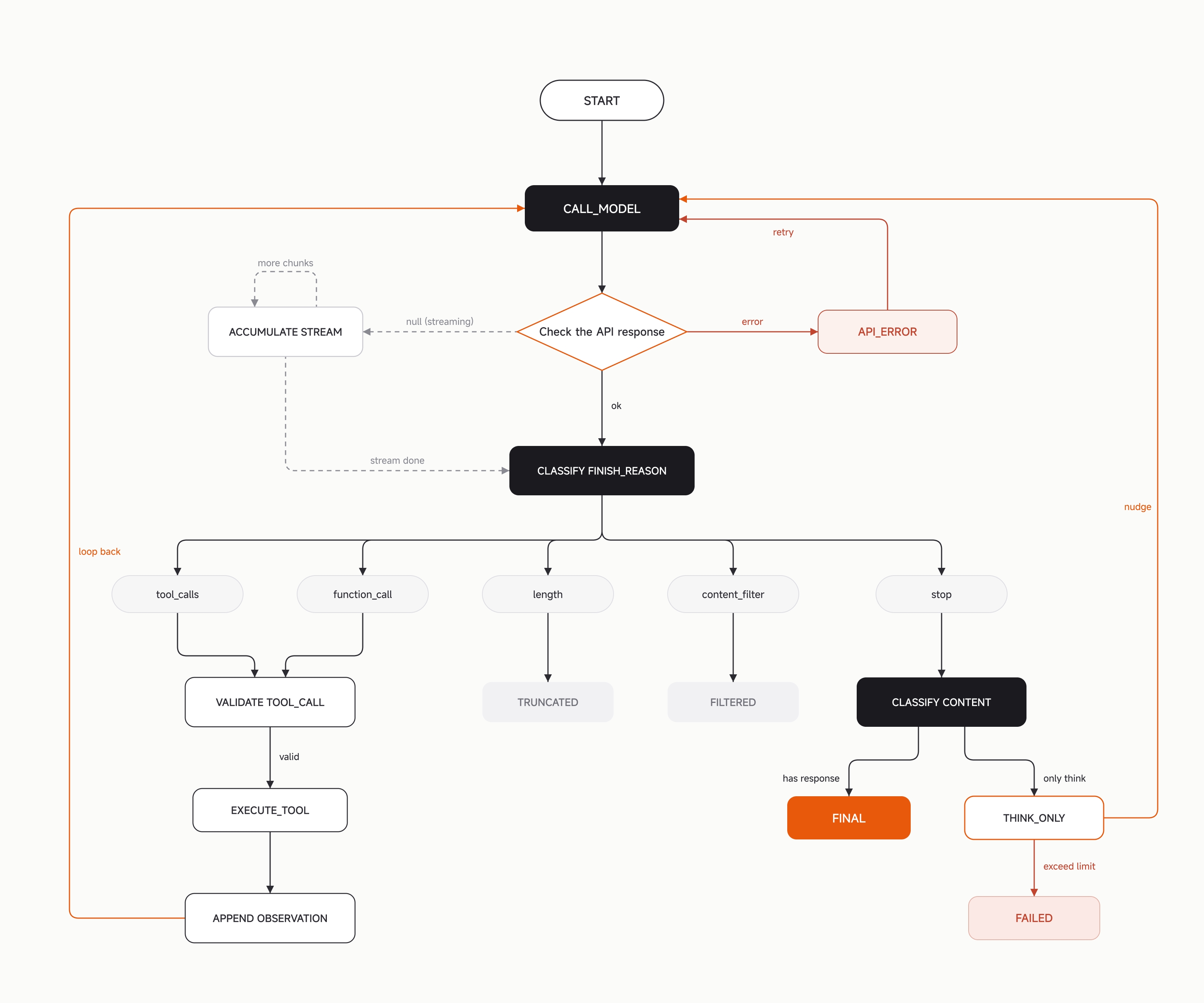
The main agent does not write that structured record itself. Xiaomi says forcing the model that is debugging code to also maintain a structured log degrades both jobs. The runtime launches an independent writer subagent. That writer records current intent, next action, working constraints, task tree, current work, involved files, errors and fixes, runtime state, design decisions, and other fields into a checkpoint file. Xiaomi says each structured file has exactly one actor with write permission, which reduces concurrent write inconsistency.
This is not the same as a generic conversation summary. Summaries are often created at the last moment, when the context is already degraded. MiMo's argument is that important extraction should happen while the model still has enough room to reason over the window. When the agent nears the limit, the runtime can rebuild the next window from already-persisted structure instead of asking a tired context to decide what mattered.
MEMORY.md and SQLite history solve different problems
MiMo Code's memory layer has four parts. checkpoint.md stores the complete working state for the current logical session. MEMORY.md stores project-level knowledge, such as architecture decisions, user rules, and repeatedly verified technical facts. Global memory stores user-level preferences across projects. SQLite history stores raw messages and tool calls without an index, so the system can trace back to original details when structured memory is not enough.
The upper layers are smaller and more curated. The lower layer is larger and more complete, but slower to use. The writer distills raw history into structured memory. The main agent's special write channel is notes.md. It can append scattered findings there, and at each checkpoint the writer reads those notes, moves them into the right structured fields, and clears the scratch file.
Xiaomi's reason for file-based memory is pragmatic. If memory affects agent behavior, users need to see what the agent remembered, delete bad entries, and update stale facts. Markdown files plus full-text search are easier to inspect than an opaque vector store. That direction will feel familiar to teams already using Codex memories, Claude Code memories, Cursor rules, or repository instruction files. If an agent says it remembers, the memory needs an audit surface.
Dynamic Workflow moves procedure out of prompt text
MiMo Code also treats orchestration as a separate runtime problem. Xiaomi argues that putting a procedure like "do A, then B, and if C happens do D" inside a SKILL.md-style natural-language prompt breaks down in complex workflows. Context compression can swallow steps. A model can skip a stage. Branching, retries, and barriers become preference judgments rather than control flow.
The alternative is Dynamic Workflow. The main agent generates a JavaScript script, and an isolated sandbox executes it. The script can call agent(), parallel(), and pipeline() to dispatch subagents and control concurrency. Xiaomi's point is that an if statement does not forget its branch, a for loop does not randomly stop, and a barrier does not lose a subagent. The language model still understands and writes the code, but code handles the workflow structure.
Xiaomi links this direction to Anthropic Dynamic Workflow. It says MiMo Code is compatible with the core semantics and adds a workflow() primitive so one script can call another. It also records every agent() result synchronously to disk, enabling recovery from the log after an interruption. For repeatable releases, migrations, and audits, executable workflow is easier to test than a long natural-language checklist.
Dream and Distill make memory cleanup a product feature
The third axis, evolution, covers what happens across sessions. MiMo Code exposes /dream and /distill in the README and blog. Dream runs every seven days. An independent agent reads historical conversation sessions and memory files, then performs merging, deduplication, path-validity verification, and compression. The goal is to converge scattered memory into a compact representation that matches the current repository.
Distill runs every 30 days. Instead of cleaning knowledge, it looks for repeated manual workflows and packages them into reusable artifacts such as skills, CLI commands, custom agents, and SOP documents. That targets teams that do the same release note, test-failure triage, deployment checklist, or repository audit every week. A long-term coding agent should not learn the same process from scratch every time.
These features also introduce risk. If Dream compresses a bad memory, the next session can begin from the wrong premise. If Distill turns a low-quality habit into a skill, the automation preserves a bad process. Xiaomi's file-based reviewability is therefore not a side feature. The central question in agent memory is not how much the system stores. It is where a human can inspect and correct the memory that changes future behavior.
Xiaomi reports a 576-developer A/B test
Xiaomi presents two forms of evidence. First, Figure 3 in the official blog compares MiMo Code and Claude Code across three benchmarks. Xiaomi says MiMo Code with MiMo-V2.5-Pro outperforms Claude Code with Claude Sonnet 4.6 in those evaluations. The blog also acknowledges that benchmark tasks are closer to one-shot repository-level issue solving. The value of multi-turn memory, background state maintenance, completion verification, and cross-session evolution is supposed to show up in real long-horizon work.

The more specific claim is the human double-blind A/B test. Xiaomi says the internal beta involved 576 developers, 474 real private repositories, and 1,213 A/B pairs. Under the same target model, MiMo Code and Claude Code were run anonymously, developers judged the results, and Xiaomi combined trajectory scoring with diff quantification. The reported result tilts toward MiMo Code as task complexity rises. Under 200 execution steps, the win rate is near 50%. Above 200 steps, Xiaomi says MiMo Code rises above 65%.
Those numbers are concrete enough to matter, but they are still self-reported. The repositories are private, and outsiders cannot inspect task selection, model settings, scoring rubric, or failure-case distribution. The stronger interpretation is not "MiMo Code beat Claude Code." It is that Xiaomi is pushing coding-agent evaluation toward long-running internal repository A/B tests and using 200 steps as a boundary where memory architecture becomes visible.
Installation is easy; operations are not
The usage path is short. Xiaomi lists curl -fsSL https://mimo.xiaomi.com/install | bash and npm install -g @mimo-ai/cli. On first run, users can choose MiMo Auto, Xiaomi MiMo Platform OAuth login, Claude Code configuration import, or a custom OpenAI-compatible API provider. MiMo Auto is described as a limited-time free channel, and the blog says it supports a MiMo-V2.5-based 1-million-token context.
The operational questions are heavier than the install command. First, teams need to know what code, secrets, command output, and terminal history get stored in memory files and SQLite history. The README mentions project memory, checkpoints, scratch notes, and task progress. The blog mentions raw history. Company repositories need clear storage location, retention, export, deletion, and secret-masking policies before this kind of agent runs broadly.
Second, a custom provider changes the data path. MiMo Code supports mainstream LLM provider APIs, but each provider has its own retention and enterprise policy. Reasoning traces, file snippets, and terminal logs may leave the machine depending on configuration. Third, Max Mode and Goal both add model calls. The independent judge and N=5 candidates can improve stability, but they also add latency and token cost. A team that does not measure success rate, wall time, and billable tokens together may end up with an agent that is more expensive without being more useful.
Xiaomi is describing an agent operating system
MiMo Code is surprising because the Xiaomi name is not usually attached to developer-agent infrastructure. Technically, however, it fits a broader pattern: Chinese AI teams are pushing open models and agent runtimes at the same time. Around the same Hacker News cycle, Moonshot's Kimi K2.7-Code also drew developer attention. Kimi emphasizes a coding-focused agentic model and token efficiency. MiMo Code emphasizes the runtime that keeps such models coherent through long work.
For devlery readers, the immediate lesson is about the product standard for long-running coding agents. SWE-Bench scores are no longer enough. Teams will need to compare when checkpoints are written, whether memory is visible as files, whether completion verification is independent, whether workflows execute as code, whether interrupted runs can recover, and whether repeated work can be distilled into reusable skills.
Xiaomi's claims may reproduce broadly, partially, or not at all. The release still makes the comparison table more concrete. On June 10, 2026, MiMo Code framed the coding agent as a development-work operating system: memory files, checkpoint writers, judges, workflow runtimes, and history stores wrapped around model calls. For tasks beyond 200 steps, the first question is not only whether the model is smart. It is whether the agent can reconstruct what it did, why it did it, what it should do next, and where the evidence says the work is finished.