Copilot code review controls redraw the approval line for PR agents
GitHub added organization runner locks, content exclusion, and longer instructions to Copilot code review, turning PR review agents into governed automation.

- What happened: GitHub added three organization-level controls to Copilot code review on June 12, 2026.
- The update covers default runner type and locking, Copilot content exclusion, and removal of the 4,000-character read limit for
.githubinstructions files.
- The update covers default runner type and locking, Copilot content exclusion, and removal of the 4,000-character read limit for
- Why it matters: PR review automation now inherits more of the same policy surface as
GitHub Actions, repository settings, and organization governance. - Watch: Copilot code review still leaves a
Commentreview, not anApproveorRequest changesreview.- If a team wants Copilot cloud agent to implement a suggestion, both code review and cloud agent tools must be enabled.
GitHub's June 12 changelog added three controls to Copilot code review: organization-level runner type defaults and locks, support for Copilot content exclusion, and removal of the 4,000-character read limit on .github/copilot-instructions.md and .github/*.instructions.md. On the surface, this looks like a configuration release. For teams that have already put AI review into pull requests, it is more concrete: Copilot review is no longer just a commenter on a diff. It is an automated review job with an execution environment, a read boundary, and a policy document.
The timing matters because Copilot code review has been moving toward infrastructure rather than only language-model output. In March 2026, GitHub said Copilot code review had moved to an agentic architecture and runs on GitHub Actions. In April, GitHub made Copilot code review generally available. In May, GitHub's usage metrics API started exposing Copilot review comment types and metrics for pull requests reviewed by Copilot. Billing changes also made AI credits and Actions minutes more visible for private-repository use. The product is becoming something a platform team has to operate, not merely a reviewer that developers can invite when they want a second pass.
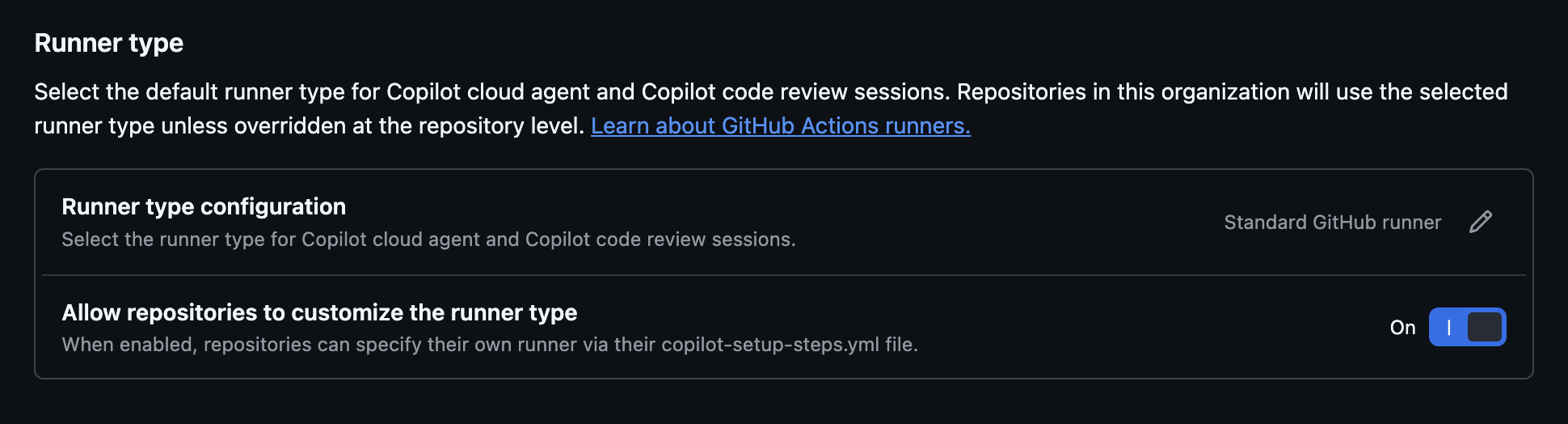
The first change is runner control. GitHub says Copilot code review uses a standard GitHub-hosted runner by default, but teams can configure self-hosted or larger runners. The new release moves that setting to the organization level. An organization administrator can set a default runner type for Copilot code review and lock it so individual repositories cannot override the policy. That gives a security or platform team a way to say that AI review must run only in an approved runner class.
The lock is the operational part. A self-hosted runner may be chosen for network isolation, regional compliance, dependency cache locality, access to private package mirrors, or cost control. A larger GitHub-hosted runner may be chosen for speed on large pull requests. Either way, the decision is no longer left to each repository's preference once an organization default is locked. Copilot code review becomes part of the same runner-capacity and trust discussion as CI jobs, release jobs, and other GitHub Actions automation.
GitHub also notes that the runner setting applies to both Copilot code review and Copilot cloud agent when both features are enabled. That short sentence has a large workflow implication. A Copilot review comment can include a suggestion. A developer may then choose to have Copilot cloud agent implement that suggestion in a separate pull request. Review and implementation are separate product surfaces, but they can sit under the same organization execution policy. A team that treats review automation and fix automation as unrelated tools will miss where runner cost, queue time, credentials, and network reachability actually meet.
The second change is content exclusion. GitHub says Copilot code review now honors Copilot content exclusion settings at the repository, organization, and enterprise levels. Repository administrators can use path-based rules to prevent Copilot from using specified files or directories as review context. That could include generated code, vendored dependencies, customer schema snapshots, test fixtures with production-like payloads, internal configuration, or any path a data owner does not want sent into a model-assisted review context.
This is not only a privacy toggle. Pull request review is not limited to the changed lines. A useful reviewer looks at surrounding files, conventions, instructions, and related code paths. That is exactly where sensitive context can appear even when the diff itself looks harmless. A team may be comfortable showing a model a patch to a serializer, but not the customer-specific schema snapshots that live beside it. Extending content exclusion into Copilot code review makes the read boundary a product feature, not an informal prompt discipline.
The third change is the removal of the 4,000-character limit for instructions files under .github. GitHub says Copilot code review previously stopped reading copilot-instructions.md and *.instructions.md files after the limit. That cap is now gone. For a small repository, this may not change much. For a large engineering organization, instructions files can easily include coding standards, security rules, framework-specific constraints, logging redaction policy, migration requirements, accessibility checks, and testing expectations.
Longer instructions are useful only if they become reviewable policy. A vague document full of words like "generally," "where possible," and "as appropriate" will not make AI review consistent. Copilot is not a legal department. The rules that help a PR reviewer are concrete and diff-checkable: every API handler must verify the tenant boundary, migration PRs must include rollback notes, logs must not include access tokens or customer secrets, file uploads must validate both MIME type and extension, and new endpoints must include an authorization test. Removing the read limit gives teams more room, but the discipline still comes from writing rules that can be applied to a changed file.
The three controls divide neatly. Runner settings define where the automation runs. Content exclusion defines what the automation may read. Instructions define how the automation should judge a change. That is why this release is more than a quality improvement for AI review. It gives organizations separate levers for execution, input context, and review criteria.
GitHub's Copilot code review documentation also keeps the approval boundary clear. Copilot code review always leaves a Comment review. It does not leave Approve or Request changes, and it cannot satisfy required approval rules. That matters because AI review can easily look more authoritative than it is. Copilot can flag a bug risk, a security concern, a performance issue, or a suggested change before a human reviewer arrives. It is not the actor that grants merge authority.
Suggested changes make the workflow more agentic without changing that approval line. GitHub Docs say Copilot review comments may include suggested changes that a developer can apply in a few clicks. The same documentation says a developer can use Implement suggestion on a review comment so Copilot cloud agent creates a new pull request with the proposed fix. That feature requires both Copilot code review and Copilot cloud agent tools to be enabled. The review comment can therefore become the starting point for a new agent-authored PR, but the branch protection and human review model still need to say who is allowed to accept that PR.
For teams rolling this out, it helps to separate three layers. The comment layer is where Copilot produces findings, suggestions, and discussion inside the pull request. The execution layer is where GitHub Actions runners, AI credits, Actions minutes, self-hosted runner maintenance, and cloud agent implementation jobs show up. The policy layer is where content exclusion, instructions files, model availability, repository rules, branch protection, and human approval requirements live. Treating all three as "Copilot review" makes the system hard to reason about. Naming the layers makes the failure modes easier to test.
This update also fits GitHub's wider June release pattern. On June 11, GitHub announced Agentic Workflows in public preview, Copilot CLI /settings, and removal of personal access tokens from agentic workflows. On June 10, Copilot Chat gained visibility into cloud agent sessions, and Copilot CLI received a dedicated security review command. On June 9, Claude Fable 5 became generally available in Copilot. Each release is separate, but the direction is consistent: Copilot is spreading from IDE completion into pull requests, CLI workflows, Actions, cloud agents, security review, usage metrics, and organization policy.
GitHub's advantage in this market is that it already owns the repository object. Cursor, Claude Code, OpenAI Codex, Devin, CodeRabbit, Qodo, and Graphite all approach code review or agentic coding from adjacent positions. GitHub can attach Copilot review to pull requests, Actions runners, branch protection, repository settings, organization policy, enterprise billing, and usage metrics inside one control plane. Runner locks and content exclusion are examples of that advantage. They also deepen the lock-in question. If one reviewer follows GitHub organization policy and another external agent follows a separate sandbox and context policy, teams need to document which finding came from which trust boundary.
Security teams should start with two checks. First, confirm that exclusion paths actually cover sensitive context. A rule for secrets/ is rarely enough. Fixtures may contain customer-shaped data, generated clients may expose internal endpoints, and snapshots may preserve payloads from production-like systems. Content exclusion should be reviewed with data owners, not only repository owners. Second, state why a self-hosted runner is being used. Network isolation, dependency caching, compliance region, cost control, and credential scope are different reasons. Switching runner type without naming the goal can create a false sense of safety.
Platform teams have a different set of concerns. If Copilot code review runs on GitHub Actions infrastructure, review frequency and pull request size can affect runner queues and Actions minutes. Larger runners may reduce latency but change cost. Self-hosted runners give more control over network and cache behavior, but they require patching, scale-out, monitoring, and secret-exposure management. Organization defaults and locks move those choices out of repository-level convenience and into central operations.
Developer teams can make the release useful with a short checklist. Inventory the repositories where Copilot code review is enabled. Confirm whether runner type is inherited from the organization or set per repository. Create a test pull request that touches an excluded path and verify that Copilot review behaves as expected. Split .github/copilot-instructions.md into short, enforceable rules and longer explanatory context, with review-critical rules near the top. Document that Copilot's Comment review does not replace required human approval. Decide who reviews PRs opened by Implement suggestion.
Community reaction to this exact changelog was still limited immediately after launch. The broader conversation around Copilot code review has been active since May because usage metrics, AI credits, model rules, and review cost are easier for developers to notice. The sensitive question is no longer only whether Copilot finds good review comments. It is who pays for the review, which model or runner is used, what repository content entered the model context, and whether the comments change merge speed or defect rate.
There is no need to overstate the release. GitHub has not automated final code approval, and Copilot has not become a replacement for human reviewers. The meaningful change is narrower and more durable: PR review agents are inheriting organization controls. Runner policy sets the execution boundary. Content exclusion sets the read boundary. Instructions set the judgment boundary. If a team does not define those boundaries, AI review becomes a new CI job with unclear cost, unclear authority, and unclear input access.