JetBrains Opens Mellum2 to Cut Coding Agent Call Costs
JetBrains Mellum2 is a 12B MoE model that activates 2.5B parameters per token. It adds a private coding model option for IDE and agent workflows.

- What happened: JetBrains released Mellum2 as an Apache 2.0 open-weight model for software engineering workflows.
- As of the June 1, 2026 announcement, the MoE model has
12Btotal parameters and activates2.5Bparameters per token.
- As of the June 1, 2026 announcement, the MoE model has
- Where it fits: JetBrains positions Mellum2 for repeated agent steps such as routing, RAG summarization, validation, and sub-agents, not as a standalone frontier chatbot.
- The arXiv report describes
10.6Tpre-training tokens,128Kcontext extension, SFT, and RLVR post-training.
- The arXiv report describes
- Developer impact: Teams that cannot send repository context to external APIs now have another self-hosted coding model candidate.
- Watch: The benchmark table is self-reported by JetBrains, so adoption still depends on serving cost, tool-call accuracy, and local runtime support.
JetBrains published Mellum2 on June 1, 2026. A same-day Hugging Face launch post followed, and the technical report appeared as an arXiv v1 submission on May 29, 2026. The public numbers are 12B total parameters, 2.5B active parameters per token, and an Apache 2.0 license. JetBrains does not pitch the model as a giant general-purpose chatbot. It describes Mellum2 as a model for repeated software engineering steps inside larger AI systems: routing, summarization, validation, and sub-agents.
That makes this a coding-agent story because of where JetBrains sits. IntelliJ IDEA, PyCharm, WebStorm, and the Android Studio family are where developers open code, search symbols, run refactors, and inspect failed tests. Coding-agent competition has recently moved toward remote execution environments and GitHub issue-driven workflows, but JetBrains is reopening the question from inside the IDE: how much latency and data exposure should every agent step require? For teams that cannot freely send internal code to external APIs, Mellum2 reads less like a smarter frontier model and more like a way to process repeated calls inside a private boundary.
The first design number is the MoE shape. Mellum2 has 12B total parameters, but each token activates 2.5B. Hugging Face frames that structure around high-throughput, low-latency inference, while JetBrains says the model competes with similarly sized models and more than halves inference time. That performance claim is JetBrains' own, not an independent measurement. Still, the operational question for AI product teams is clear: should every routing turn, retrieval post-processing pass, and code-diff validation call go to a frontier API, or can some stages move to a self-hosted focal model?
The technical report describes the architecture in more detail. Mellum2 activates 8 of 64 experts, uses 4 KV heads in Grouped-Query Attention, and applies Sliding Window Attention in three out of every four layers. A single Multi-Token Prediction head acts both as an auxiliary pre-training objective and as a draft model for speculative decoding. JetBrains says these choices were tested through ablations under commodity GPU inference constraints. In production terms, the model was designed with serving speed and cost as first-class variables rather than as afterthoughts after quality.
JetBrains also disclosed the training recipe. The arXiv abstract cites about 10.6T pre-training tokens and a three-phase curriculum that moves from diverse web data toward curated code and mathematical content. The optimizer is Muon, precision is FP8 hybrid precision, and the schedule combines Warmup-Hold-Decay with a linear decay to zero. The base model is extended to a 128K context window with layer-selective YaRN, then post-trained with supervised fine-tuning and reinforcement learning with verifiable rewards. The public variants include direct-answer Instruct models and Thinking models that emit reasoning traces.
| Item | Mellum2 disclosed number | Validation question for engineering teams |
|---|---|---|
| Compute | 12B total, 2.5B active per token | Does it reduce router, validator, and summarizer call cost? |
| Context length | 131,072-token context | Does it remain stable with repository slices plus retrieval output? |
| Runtime path | vLLM, SGLang, and Docker Model Runner examples | Does it fit the team's GPUs, quantization path, and OpenAI-compatible gateway? |
| License | Apache 2.0 | Can the team support commercial use, internal fine-tuning, and artifact governance? |
The Hugging Face model card adds concrete configuration for the Thinking checkpoint. It lists 28 layers, hidden size 2304, intermediate size 7168, MoE intermediate size 896, vocabulary size 98,304, and BF16 tensors. The vLLM example uses --reasoning-parser qwen3. For tool calling, it adds --enable-auto-tool-choice and --tool-call-parser hermes. The card also includes SGLang and Docker Model Runner examples. That moves Mellum2 beyond a static weights release and toward a model that can be wired into coding-agent runtimes.
One caveat appears directly on the model page: at publication time, Hugging Face says the model is not deployed by any Inference Provider. This is not a click-to-run managed endpoint story. Teams need to download the weights and prepare the serving stack. That constraint matches JetBrains' positioning around private deployment and self-hosted software engineering workflows. It also means the real deployment plan includes GPU capacity, model caches, request routing, logging, eval harnesses, and a fallback model.
Mellum2 is not aimed only at code generation. The Hugging Face launch post groups its use cases into routing and orchestration, RAG pipelines, sub-agents, and private deployment. Routing examples include prompt classification, tool selection, and intermediate control-flow steps. RAG examples include context compression, summarization, and retrieval post-processing. Sub-agent examples include planning, validation, transformation, and context preparation. As coding agents become systems made of many small decisions rather than one giant model call, these middle-layer calls become visible in the cost model.
Mellum2 therefore makes a narrower claim than "small models are enough." JetBrains says it dropped multimodality and focused on text and code. Vision, speech, and image generation are out; software engineering natural language and code data are in. That choice fits JetBrains' product surface. An IDE already has structured context such as file trees, symbols, types, call hierarchies, diffs, and test output. A model does not need to solve everything from general world knowledge if the IDE can provide the right context and ask for fast scoped decisions.
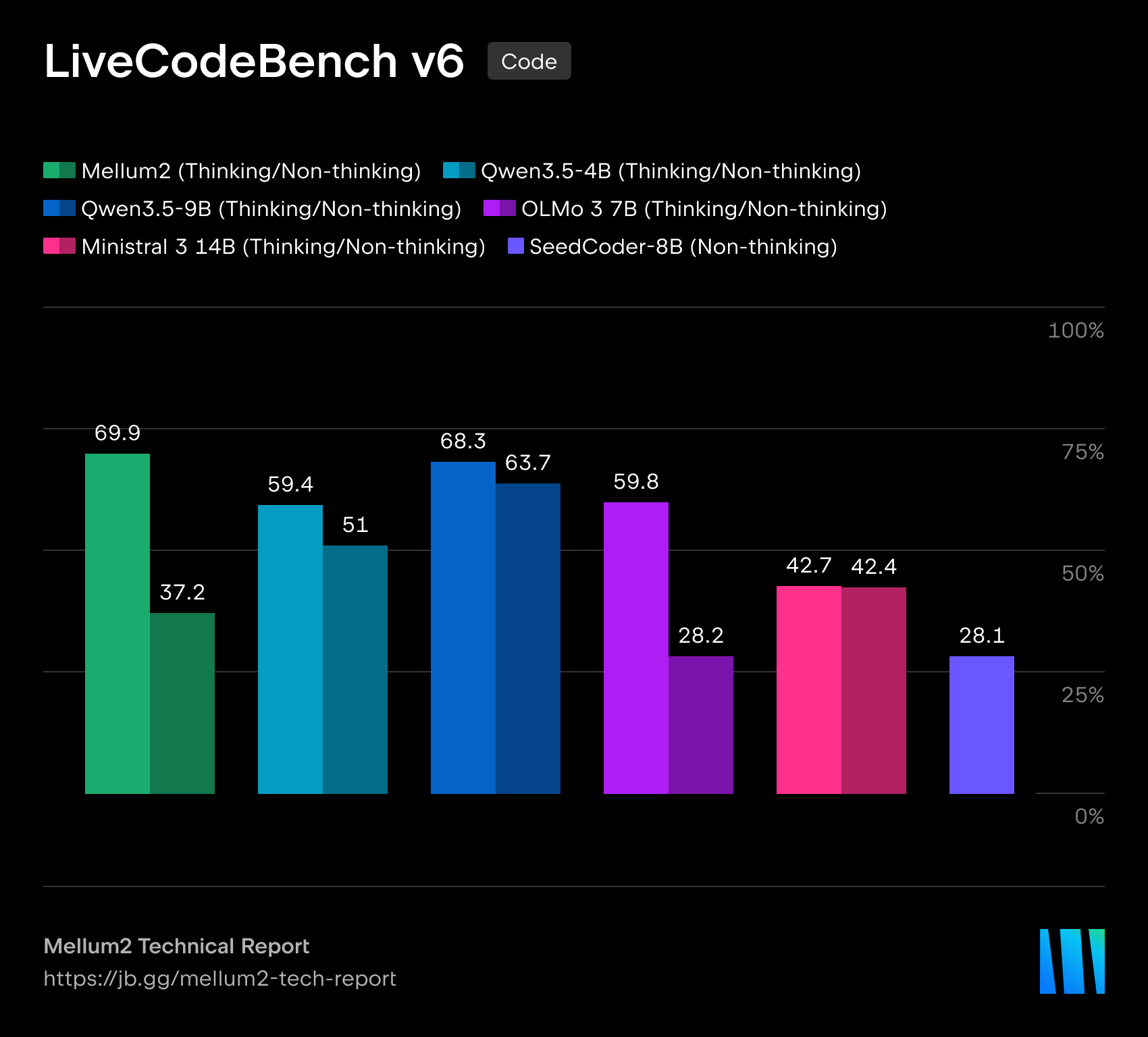
The reported performance numbers need careful reading. The evaluation section on the Hugging Face model card states that all values are self-reported by JetBrains. The Thinking RL variant scores 69.9 on LiveCodeBench v6, while Thinking SFT scores 75.1. BFCL v4 is 45.6 for Thinking RL, and BFCL v3 is 69.4. AIME is 58.4, GSM-Plus is 87.0, and MMLU-Redux is 86.2. The same table shows stronger numbers for other models on some non-coding metrics; Qwen3.5 9B, for example, is higher on AIME, GPQA Diamond, and IFEval. Mellum2 should be read as an efficiency candidate around coding and tool-use workflows, not as the winner of every benchmark row.
Early r/LocalLLaMA discussion reflects the same caution. One thread summarized Mellum2 as a coding-focused small MoE and compared it with Qwen-family models. Commenters quickly asked about llama.cpp support. Another thread focused on the 128K context window and the 12B-A2.5B size, with users asking whether a 16GB-class laptop could run it. Some expected JetBrains IDE telemetry and code-aware context to be a differentiator; others argued it still needs comparison against Qwen3.5 and Gemma-family models. The early community read sits between "useful internal assistant candidate" and "benchmarks alone are not enough."
JetBrains' release pattern differs from the strategies used by OpenAI, Anthropic, and Google for coding agents. Codex, Claude Code, and Gemini-family tools emphasize strong managed models and agent surfaces. Users hand over an issue, branch, terminal, browser, or pull request, while the provider owns model updates and compute. Mellum2 asks the opposite question: with model weights, an Apache 2.0 license, and vLLM/SGLang examples, can a company run some agent steps inside its own network? That answer belongs to security and platform teams as much as application developers.
For internal-code security, the option is meaningful but not free. A coding agent may read repository context, secret-adjacent configuration, incident logs, and proprietary API schemas. Once that happens, the data path belongs in procurement and security review. API-only models are governed through data-retention policies and enterprise agreements. Open-weight self-hosting can reduce external transmission, but it moves model artifacts and inference servers into internal responsibility. Mellum2's Apache 2.0 license lowers commercial-use friction, but deployment still requires review of weights provenance, acceptable use, export controls, access logging, and prompt storage policy.
The developer-experience change is less about a new button than a different call graph. Given a large task, a smaller model can classify the request, select candidate files from the repository, compress retrieval results, and prepare a plan before a frontier-model call. After execution, it can check whether the diff stayed inside scope, connect a test failure log to likely files, or compare a pull-request description against the actual change. These stages are more sensitive to latency and cost than to open-ended creativity. Mellum2's 2.5B active-parameter design targets that zone.
It would be overstated to say Mellum2 replaces Claude Code or Codex. JetBrains does not make that claim. The Hugging Face launch post describes Mellum2 as a fast, well-scoped model inside larger AI systems. In a real agent product, Mellum2 is more likely to act as a router or validator while harder reasoning and code synthesis go to a larger model. That architecture only works if wrong routing has a fallback, validators do not emit too many false positives, and cost savings exceed orchestration complexity.
Teams evaluating Mellum2 should start with trace replay rather than a benchmark race. Take the last month of coding-agent sessions and extract only small steps: prompt classification, tool selection, retrieval compression, diff review, and test-failure summarization. Send those steps to Mellum2 and the incumbent model, then record latency, token throughput, schema errors, hallucinated file paths, missed test failures, and false rejections. LiveCodeBench gives a starting signal; inside an agent, "did it read the wrong file?" and "did it misdescribe the PR diff?" often cost more.
Serving experiments are a separate track. vLLM and SGLang examples help, but opening a 128K context window changes memory pressure and throughput. Teams need to observe how the combination of a 1,024-token sliding window and periodic full-attention layers behaves with long repository context. The Thinking model can emit <think> blocks, so product teams must also decide whether reasoning traces are stored, hidden, or discarded in favor of the final answer. Adding a tool-calling parser and OpenAI-compatible gateway makes function-argument stability another metric.
The release signals that JetBrains does not view the AI coding market as only an IDE plugin feature race. It opened model weights, attached a technical report, and published multiple checkpoints in a Hugging Face collection. That package goes beyond an internal model for JetBrains AI Assistant. It is an attempt to make JetBrains' model usable as a small execution component in third-party AI workflows. That fits a market where permission boundaries, execution location, trace validation, and per-call cost are becoming as important as model brand.
For teams outside English-only environments, two checks matter. First, Mellum2 was not announced as a language-specific model for Korean or other local-language requirements. The model card carries an English tag, and the public evaluation focuses on code, math, reasoning, and tool use. Teams that feed it Korean requirements documents, customer tickets, or internal wiki pages need their own eval set. Second, teams already using the JetBrains IDE ecosystem should treat IDE-context integration as a larger variable than raw model quality. Symbol graphs, inspection results, test runners, and debugger output can change how useful a 2.5B-active model feels.
The practical conclusion is narrow. Mellum2 does not end the frontier coding-agent race. It gives teams an open-weight candidate for reducing cost and data exposure in repeated agent stages when coding workflows are split across multiple model and tool calls. Apache 2.0 licensing, 12B-A2.5B MoE compute, 128K context, and vLLM/SGLang examples make the model testable. The next decision should come from each team's trace replay, GPU utilization, tool-call error rate, and security review rather than from JetBrains' benchmark chart alone.