Google SRE reveals AI Operator for production incident response
Google SRE has published its AI-Ops design for AI Operator, Actus, Detectr, and controlled autonomous production mitigation.

- What happened: Google SRE published a production-operations design that includes
AI Operator,Actus, and Gemini-based Detectr.- The paper connects AI coding velocity with incident response, deployment validation, permission boundaries, and production actuation.
- Numbers: Google reports a 10% MTTM reduction from Incident Hypothesis and about a 44% MTTM reduction for supported incidents using Investigation Dashboard.
- Developer impact: The production-agent problem is less about model branding and more about
dry_run, agent identity, circuit breakers, and emergency stop controls.- Google says AI Operator does not execute raw low-level scripts directly. Actuation Agent separates planning, risk evaluation, approvals, execution, and post-action guardians.
Google SRE has published a new article, AI in SRE: How Google is Engineering the Future of Reliable Operations. The subject is not a generic AI-Ops chatbot. Google lays out a production-agent architecture that ties together AI Operator, Actus, also called Actuation Agent, Gemini-based Detectr, AI Alert, Investigation Dashboard, Antigravity CLI, Production Agent MCP servers, and A2A. The article is a concrete description of where SRE teams can let AI investigate, where humans must approve, and where every machine action needs an emergency stop.
The starting point is development speed. Google writes that AI coding assistants are raising code-generation and deployment velocity, and that some organizations are targeting up to 4x productivity improvements. Manual review and manual incident response do not scale linearly with machine-generated code volume. That creates a second-order cost for SRE and platform teams: every faster pull request, rollout, and configuration change eventually becomes more operational state to validate.
Google's answer is not to hand production to a general-purpose chat interface. AI Operator is described as a first responder for production alerts. After receiving an alert signal, it can run multiple investigation modules in parallel, use examples from previous human-led incidents, attempt root cause analysis, then select deterministic signal boosters, mitigation skills, or text-proto few-shot investigation strategies. The current autonomy boundary is explicit: L2 autonomy requires human approval for critical operations, while L3 autonomy can perform bounded autonomous mitigation for minor incidents.
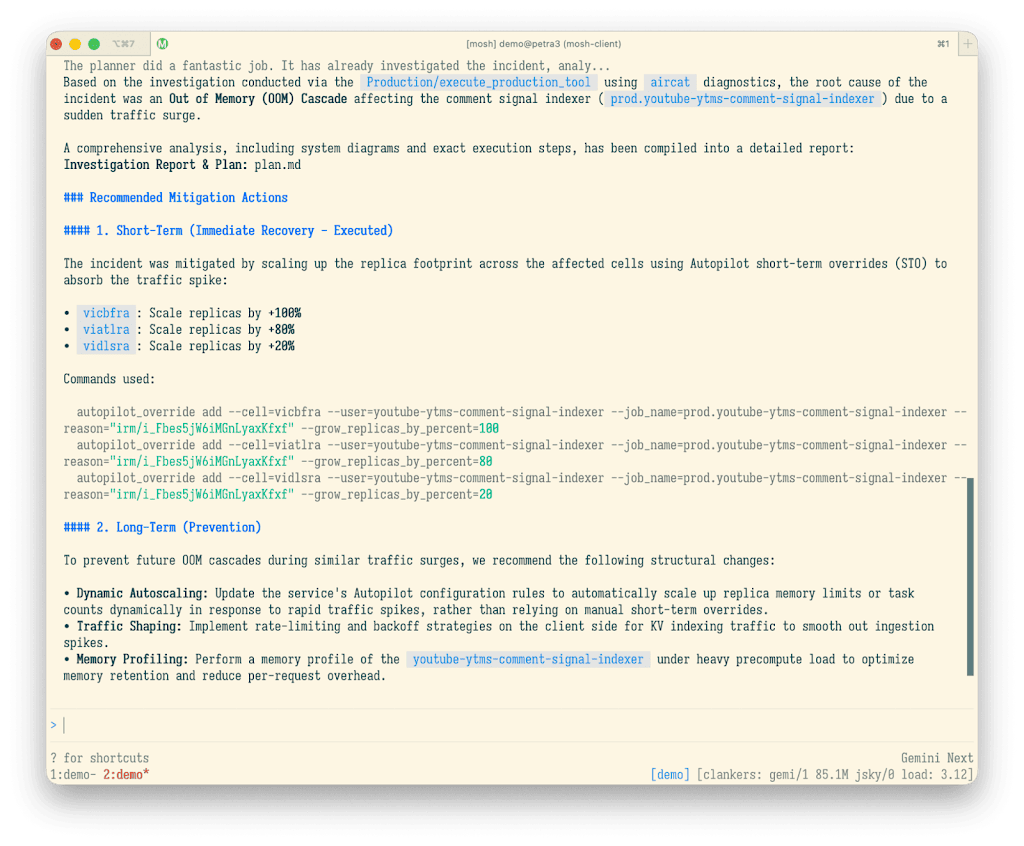
The image Google shows is useful because the interesting part is not that an agent "fixed" something. It is the execution path. The example analyzes an incident around a YouTube comment signal indexer, proposes increasing replica footprint by cell to absorb a traffic spike, and leaves both an investigation report and an action plan. Commands include concrete parameters such as grow_replicas_by_percent. For SRE readers, the artifact that matters is the trace an operator can audit later.
Google groups the control model under a "Safety Trifecta." The first element is transparency. An AI agent needs to show which signals it inspected, which hypotheses it considered, why it selected an action, and how confident it was. The second is real-time risk evaluation. The same cell-drain operation can be low risk during a normal window and high risk during a regional peak, active incident, or error-budget burn. The third is progressive authorization. Agents should begin under human approval and gain rights only as SRE autonomy levels and safety evidence justify them.
The actuation controls are more concrete than the autonomy labels. Google says agentic systems must not run under a developer's standing credentials. Agent identity should be distinct from a human user, strongly authenticated, and granted only the rights needed for the current action. Agent-specific rate limits and circuit breakers are also required, because a runaway loop can burn resources or keep mutating production state. APIs that change production need a declarative dry-run mode such as dry_run=true, so the agent, safety framework, and human reviewer can estimate blast radius before execution.
That requirement is why AI Operator does not execute low-level scripts directly. Google separates the reasoning engine from the execution engine. AI Operator proposes a mitigation strategy; Actuation Agent receives an EvaluateAction request, fills parameters, and converts LLM intent into a verifiable execution plan. Before execution, the path includes mandatory dry-run, justification verification, and concurrent action checks. Even when an agent requests L3 execution, Actuation Agent can downgrade the action to L2 and require human approval if risk is high or production state looks abnormal.
Actuation Agent also includes a post-action guardian. It tracks long-running operations, polls whether mitigation succeeded, and exposes a "red button" endpoint to human operators. That emergency control can stop in-flight agentic actions, block new actions, and revoke L3 autonomy across a fleet. The design is a useful reminder that stronger models do not remove the need for deterministic, human-controlled production boundaries.
Google's autonomy model splits monitoring, investigation, approval, actuation, and self-directed operation. L0 is fully manual. L1 automates monitoring and investigation but leaves approval and action to humans. L2 lets the system stage or execute actions after explicit approval. L3 automates monitoring, investigation, approval, and actuation for well-defined scenarios, while humans still handle novel multi-step resolution. L4 is the target state where a system can diagnose, mitigate, resolve, observe the result, and adjust strategy through a full incident lifecycle.
| Level | Approval | Execution | Boundary in Google's design |
|---|---|---|---|
| L1 Assisted | Human | Human | AI stays with alert investigation and hypothesis generation. |
| L2 Partial | Human | System can stage or execute | A plan and dry-run precede explicit approval. |
| L3 High | System | System | Restricted to minor incidents in well-defined scenarios that pass safety checks. |
| L4 Full | System | System | The target state manages a multi-step incident lifecycle end to end. |
The evaluation pipeline is a separate part of the design. Google says incident-era chat, notes, and command-line entries from human responders can be reconstructed as human trajectories. IRM-Analyzer orders key events, actions, tools, and hypotheses over time, then feeds that trajectory into agent learning and reinforcement loops. Data quality is tiered as Bronze, Silver, and Gold. Bronze comes from heuristic autolabeling, Silver is programmatic data calibrated with Gold examples, and Gold is verified by human experts.
Nightly Eval keeps that loop moving. Google connects automated nightly evaluation to the Everest evaluation platform and tests agent behavior on a rolling dataset of recent real-world Google incidents. The scoring mix is deliberate: LLM-as-a-Judge can evaluate intermediate reasoning, investigation trajectory, and tool-call quality, while final mitigation output is judged with stricter precision and recall. A vague suggestion such as "rollback" is not treated as correct. The binary and version parameters must match golden data.
Detectr shows how an operations agent can use signals beyond metrics, logs, and traces. Google says traditional telemetry is strong for known failure modes but can miss user intent and actual customer experience. Detectr collects unstructured user feedback from places such as social media, customer support, and product forums, then runs filtering, clustering, de-noising, and report generation to create outage notifications. Google says Cloud, Ads, YouTube, and Search teams have adopted Detectr and that earlier detection has reduced cumulative customer impact by hundreds of hours.
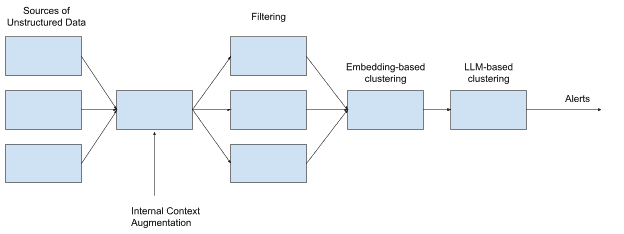
AI Alert uses a much shorter time budget. Google says the system has roughly two minutes before an alert reaches a human. In that window it performs high-volume parallel queries across monitoring, logging, production change logs, and dependency graphs. It then attaches relevant anomalies, recent rollouts, configuration changes, similar past incidents, and potential root causes to the incident management tool. Google keeps AI Alert read-only and emphasizes verifiable facts with source links over speculative conclusions.
Incident Hypothesis is where Google shares a measured L1 result. For declared incidents, it combines real-time monitoring anomalies, service playbooks, application logs, incident management data, RAG, and LLM reasoning. It also adds similar past incident patterns to provide credible leads and verification steps to the on-caller. Google says its A/B test reduced mean time to mitigation by 10%. The number is not dramatic in isolation, but it came from informational assistance in a read-only, human-driven mitigation path.
Investigation Dashboard produced a larger reported gain. Google describes it as an incident-specific single pane of glass that reduces the work of moving between static dashboards. Its analysis stack includes anomaly detection, alert-signal and change correlation, investigation-worthiness ranking, and root-cause identification. According to the article, ML-based anomaly detection increased overall findings by 195%, and supported incidents saw about a 44% reduction in MTTM. That result makes the near-term value clear: before AI mutates production, it can still reduce the time humans spend collecting and correlating evidence.
Antigravity CLI is the section many developer-tool readers will recognize. Google SRE notes that production operations often happen from a CLI even when dashboards exist. Antigravity CLI connects to a standard Production Agent interface. Through the Production Agent MCP server, Gemini can create issue-tracker action items, assign owners, and export postmortems to Google Docs. The same interface can expose real-time monitoring queries, log analysis, incident-detail fetches, dependency inspection, and policy-compliant traffic-drain initiation.
MCP and A2A appear as infrastructure plumbing rather than buzzwords. Google describes MCP as an AI-friendly tool interface that exposes observability, incident management, traffic control, and infrastructure tools through natural language. Production-state-changing tools are integrated with a Mitigation Safety Verification Agent to check policy compliance. A2A is framed as an inter-agent communication protocol that lets domain agents for monitoring, rollout, capacity, and related areas participate in a composite AI-Ops system.
The lesson for most companies is not "turn on L3 autonomy." Google's design assumes deep incident history, service topology, SLOs, error budgets, a production tool catalog, internal RAG infrastructure, tuned models, nightly evaluation, and stores such as Spanner for traces. Without those foundations, copying the autonomy labels is risky. Smaller teams can borrow narrower requirements first: read-only alert enrichment, dry-run runbooks, human-approved plans, separated agent identity, rate limits, and complete tool-call logs.
The article makes the connection to coding agents explicit later on. Google argues that at 4x to 10x code volume, line-by-line review risks reviewer fatigue and rubber-stamping. Humans need to move toward design, intent, and policy review. Code-generation agents and test or review agents should be separated into independent harnesses. If the same agent writes the code and defines the tests, bias can propagate into the evaluation and hide missing requirements.
Deployment strategy changes too. When changes accumulate quickly, a traditional rollback may not be simple. Google calls this the Intervening Pull Request Problem. Rolling back to the last known good version can also remove bug fixes or security patches that landed in between. That makes dynamic configuration, feature flags, continuous production validation, and AI-assisted fix-forward paths more important. If AI created code faster, incident response may need smaller patches that can be generated, validated, and applied faster.
GeekNews summarized the article on June 2 under the Korean title "SRE에서의 AI: Google은 어떻게 신뢰성 있는 운영의 미래를 설계하는가," emphasizing that AI coding assistants are making human-by-human SRE review less scalable. Around the same time, Hacker News front-page context included AI agent guidelines, OpenAI on AWS, NVIDIA RTX Spark, and Alphabet AI infrastructure investment. Production-agent operations are quieter than model launches, but their costs show up first in incident review, rollout guardrails, and agent permission models.
The most practical sentence in Google's SRE article is close to this: AI Operator does not directly execute raw scripts. Production automation quality depends less on the model name than on agent principals, dry_run, evidence links, deterministic scoring, Actuation Agent, autonomy downgrade, and the red button. As coding agents create more pull requests, SRE and platform teams need to write these controls as product requirements, not as after-the-fact safety notes.