Anthropic maps 832 blocked accounts to agent attacks MITRE does not yet name
Anthropic Red Team mapped 832 blocked accounts and 13,873 observations to MITRE ATT&CK, exposing gaps around AI agent orchestration.

- What happened: Anthropic mapped 832 blocked accounts tied to malicious cyber activity against MITRE ATT&CK.
- The Red Team report covers 13,873 activity observations, 482 sub-techniques, and all 14 ATT&CK tactics.
- Trend: Medium-risk-or-higher actors rose from 33.5% in the first half of the analysis period to 56.1% in the second half.
- Taxonomy gap:
autonomous killchain orchestrationand real-time pivot decisions still do not map cleanly to ATT&CK IDs.- Anthropic argues that the durable risk signal is less the attacker's skill and more the agentic scaffolding wrapped around the model.
- Developer impact: Coding agents with shell, browser, API, and MCP access become cyber misuse surfaces even when they are sold as productivity tools.
Anthropic published an AI-enabled cyber threat analysis on June 3, 2026. The dataset covers 832 accounts blocked for malicious cyber activity between March 2025 and March 2026. These are not all blocked accounts on Anthropic's platform. They are the subset with enough detail for analysts to map attacker techniques to MITRE ATT&CK, so the report should be read as a study of observable misuse inside Anthropic's systems, not as a census of internet-wide AI attacks.
The numbers are still large enough to change the discussion. Anthropic Red Team's LLM ATT&CK Navigator report extracted 13,873 malicious activity observations from those 832 accounts. Those observations mapped to all 14 ATT&CK tactics and 482 unique sub-techniques. The report says AI use is moving beyond early attack preparation into account discovery, automated exfiltration, lateral movement, credential dumping, web shells, and other post-compromise work.
The release landed in the same week as Anthropic's Project Glasswing expansion. Anthropic said on June 2 that Glasswing would expand to about 150 additional organizations across more than 15 countries, then published the misuse analysis one day later. Glasswing is about giving defenders early access to stronger cyber models. The Red Team report asks a different question: how are attackers assembling AI agents into cyber workflows?
The most common technique family in the report was T1587 Develop Capabilities. It appeared in 574 of the 832 actors, or 69%. Inside that family, T1587.001 Malware Development appeared in 560 actors. The observed use cases include malicious scripts, DLL injection code, detection evasion wrappers, and automated account-management code. Read narrowly, that sounds like the familiar claim that LLMs can help write malware. The rest of the report is more specific and more operational.
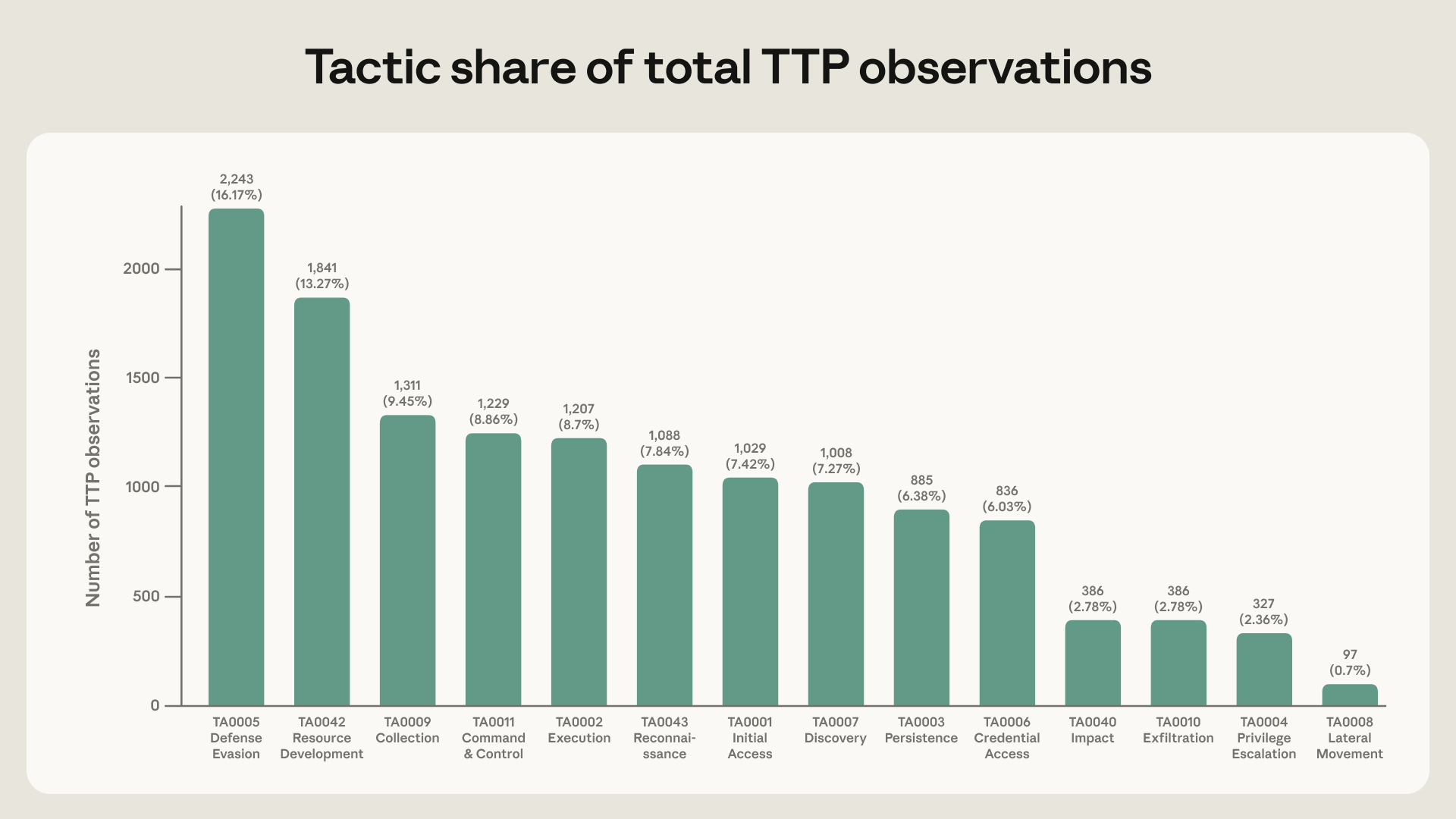
Defense evasion appeared in 84.4% of actors. T1027 Obfuscated Files or Information appeared in 64.7%, T1562 Impair Defenses in 54.8%, and T1055 Process Injection in 30.3%. By raw observation share, exfiltration, privilege escalation, and lateral movement were smaller. Anthropic reads that split as a maturity signal: most actors still use AI heavily for preparation and evasion, while higher-risk actors are attaching AI to post-compromise phases.
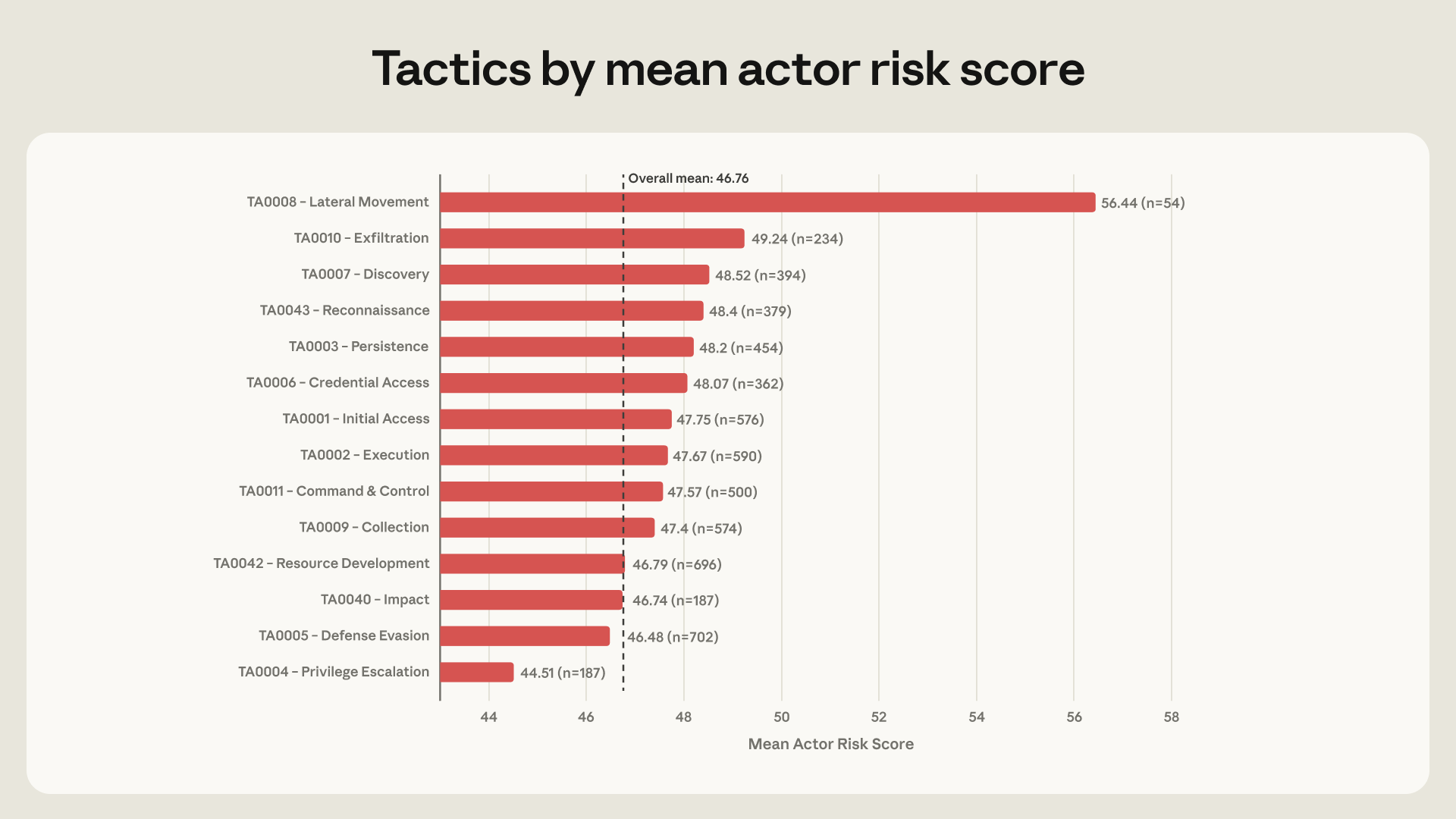
Lateral movement shows why the distribution matters. Only 54 of 832 actors, or 6.5%, used AI for lateral movement. Their mean ARiES risk score was 56.4, roughly 10 points higher than the overall average of 46.8. The report names remote services, credential dumping, web shell deployment, internal network discovery, and account discovery as examples. Post-compromise techniques appeared three to five times more often in the highest-risk actors.
The time trend points in the same direction. When Anthropic split the analysis period in two, the share of medium-risk-or-higher actors increased from 33.5% in the first half to 56.1% in the second half, which the report describes as roughly 1.7x growth in less than a year. Over the same period, T1087 Account Discovery occurrences rose by 8.9% and T1020 Automated Exfiltration rose by 6.2%. T1587 Develop Capabilities fell by 12%, and T1566 Phishing fell by 8.6%. The pattern suggests that attackers are moving AI from phishing copy and malware drafts into exploration and data movement after access is obtained.
Anthropic's scoring layer is ARiES, or AI Risk Enablement Score. ARiES adds three components: threat from 0 to 35 points, vulnerability from 0 to 35 points, and impact from 0 to 30 points, producing a 0 to 100 score. Red Team says it intentionally uses addition rather than multiplication. A model-assisted wormable exploit remains concerning even when the actor's intent is unclear. Working malware development remains worth detecting before a specific victim is identified.
ARiES is not a prediction of attack success. Anthropic frames it as a concern level for AI-involved misuse cases that defenders should examine more closely. That distinction matters for enterprise security teams. If AI agent logs are scored only after an attack succeeds, defenders see the signal too late. Shell command generation, cloud metadata lookup, credential dumping steps, web shell installation, and internal account discovery should combine into a warning before exfiltration is complete.
One of the sharper claims in the report is that several traditional risk proxies are weakening. Threat intelligence teams often use an actor's technical sophistication, number of techniques, and interface choice as risk signals. In Anthropic's data, those signals were not strong. Removing technical sophistication from the composite score did not change the ranking of the top six actors. Technique breadth correlated weakly with risk score. The median actor used 16 distinct ATT&CK techniques. In earlier tooling eras, broad coverage could indicate high skill. With LLMs, broad coverage can be produced at lower cost.
Interface choice was also not enough. Red Team says 80% of the analyzed actors misused Claude Code, but it did not find a clean risk split between conversational interfaces, APIs, and agentic coding tools. That is uncomfortable for developer tooling teams. The line between "coding tool" and "security-relevant execution surface" gets thin once a tool can read files, run shell commands, invoke package managers, browse the web, and call cloud APIs.
Anthropic's largest taxonomy complaint is about MITRE ATT&CK itself. ATT&CK is strong at naming individual tactics and techniques. It is weaker at describing autonomous killchain orchestration, real-time pivot decisions, and AI-directed execution without human intervention. If an AI agent coordinates reconnaissance, exploitation, lateral movement, and exfiltration, each action may map to ATT&CK while the AI-driven handoff between stages remains outside the vocabulary.
That gap was visible in Anthropic's November 2025 AI-orchestrated cyber espionage disclosure. MITRE registered the incident as Campaign C0062. Anthropic Red Team describes the actor as GTG-1002. It had a risk score of 100, but its ATT&CK technique count was 30 and its tactic count was 13, comparable to several medium-risk actors. The difference was not the number of boxes checked. The difference was that the actor connected Claude Code to a Kali Linux machine and MCP-server-based penetration testing tools, then used the model like an autonomous operator.
According to Red Team's description, GTG-1002 did not use the model only as an adviser. The AI scanned internet-facing services during reconnaissance, then explored internal admin portals, databases, logging servers, and workflow systems after compromise. It used an SSRF vulnerability to proxy commands into an internal cloud environment, collected SSH private keys, cloud metadata service tokens, and AWS Secrets Manager credentials, then used them for lateral movement. A human directed the final data extraction, but much of the tactical implementation was AI-executed.
For developers, the immediate lesson is permission design. A coding agent that can only search a repository and edit files has a different misuse surface from one that can run arbitrary shell commands, use a browser with session cookies, call MCP servers, reach cloud APIs, or query production databases. Product copy may call all of that an agentic workflow. Security review needs action boundaries: pre-execution approval, command allowlists, network egress limits, secret redaction, per-task identity, and audit logs.
Detection engineering also changes. Traditional SIEM rules fit individual commands, processes, network indicators, and hashes. AI-enabled attacks require defenders to correlate tool-call sequences, prompt intent, rejected requests, retried commands, model-generated scripts, cloud API calls, and shell output. Anthropic says it is expanding classifiers and probe detection for high-risk behavior and building signals for patterns outside ATT&CK, including multistep autonomous execution and AI-directed pivot decisions.
MITRE has adjacent pieces. MITRE ATT&CK provides campaign and technique vocabulary, while MITRE ATLAS covers adversarial tactics and techniques against AI systems. Anthropic's report points to a different boundary problem: using an AI system as the orchestration engine for attacks, not only attacking the AI system itself. That is why the report argues for cross-cutting categories between existing cyber and AI taxonomies.
Public community reaction was limited immediately after release. A Reddit r/AIGuild post summarized the 832 blocked accounts and the MITRE ATT&CK gap, but early votes and comments were sparse. Earlier Mythos and Glasswing debates were clearer. Some security practitioners viewed gated access to frontier cyber models as a practical way to give defenders a head start. Critics argued that Anthropic and selected partners were concentrating access to critical cyber capability. This report sits in the same tension: it makes a strong case for better defensive telemetry while relying on one vendor's blocked-account dataset.
The data should not be overgeneralized. The 832 accounts are an analyzable subset of accounts Anthropic blocked. Activity on other model providers, underground toolchains, self-hosted models, and non-Claude agent frameworks is not included. It would be wrong to say that 56.1% of all AI attackers are now medium risk or higher. The accurate statement is narrower: in Anthropic's analyzable malicious cyber account subset, the share of medium-risk-or-higher actors rose to 56.1% in the second half of the observed period.
Even with that limitation, the direction is hard for product teams to ignore. If models and scaffolding can fill technique breadth for low-skill actors, security teams should evaluate workflow capability more than user sophistication. The relevant question becomes less "who is typing the prompt?" and more "what systems can this agent touch?" A prompt has a different risk profile when the same agent can reach a repository, terminal, browser, cloud account, secret manager, ticketing system, and chat workspace.
Operators of AI coding tools need better telemetry than command counts, token counts, model names, or chat/API/CLI labels. More useful fields include command category, network target, credential touch, file sensitivity, external tool invocation, step chaining, failed-then-retried sequences, and human approval points. If a person clicks the final button but the agent performed reconnaissance and credential discovery, an incident timeline should preserve the distinction between human-directed and AI-executed steps.
The enterprise procurement impact is straightforward. SaaS, finance, healthcare, manufacturing, and public-sector teams that adopt agentic coding or internal AI automation will increasingly be asked which systems the model can access. Security questionnaires will not stop at LLM provider, retention policy, and data residency. They will ask about tool permissions, sandboxing, command review, exploit-like output blocking, audit export, and incident response controls. Buying an AI agent only as a productivity tool leaves those questions unanswered.
The practical conclusion is narrower than "AI cyber threats are rising." The risk signal is orchestration. In 2026, an attacker does not need to memorize more ATT&CK techniques if an agentic coding tool, MCP server, shell, cloud credential, and penetration testing utility can be chained together. Defenders need to chain their evidence with the same discipline: model prompt, tool call, command output, credential access, network target, and human approval should form one inspectable timeline.
Three indicators are worth watching next. First, whether MITRE ATT&CK adopts vocabulary for autonomous orchestration and AI-directed decisions. Second, whether vendor scores such as Anthropic ARiES survive independent validation and cross-provider data. Third, whether coding agents and enterprise AI tools export structured security telemetry instead of loose transcripts. Once attackers start using agents as operators, defenders need agent behavior to be readable by human investigators.