Cohere Command A+ ships as an open-weight MoE for two H100s
Cohere Command A+ combines Apache 2.0 open weights, a 218B MoE design, 25B active parameters, 128K context, and enterprise deployment options.

- What happened: Cohere released Command A+ as Apache 2.0 open weights.
- The May 20, 2026 release lists
218Btotal parameters,25Bactive parameters, and a128Kcontext window.
- The May 20, 2026 release lists
- Deployment math: Cohere says the model can run on one B200 or two H100s.
- Hugging Face hosts
command-a-plus-05-2026-w4a4, while Cohere also points to API, VPC, cloud, and on-premises deployment paths.
- Hugging Face hosts
- Builder impact: Command A+ is aimed at agentic QA, data analysis, memory quality, multilingual work, tool use, and enterprise serving constraints.
- Watch: the charts are Cohere-run benchmarks, so latency, cost, and tool reliability still need workload-specific evaluation.
Cohere released Command A+ on May 20, 2026. The announcement calls it the company's fastest and most capable language model so far, but the more useful signal for builders is the operating footprint. Command A+ is a mixture-of-experts model with 218 billion total parameters and 25 billion active parameters per request. It supports a 128K context window, and the Hugging Face model card lists the license as Apache 2.0.
This is not only another open model release. Cohere put Command A+ behind the Cohere API, Amazon SageMaker, Azure AI Foundry, Oracle Cloud Infrastructure, Hugging Face, private VPC deployments, and on-premises deployments. The same launch says the model can be operated on one NVIDIA B200 or two NVIDIA H100 GPUs. In the open-weight LLM market, that hardware line can matter as much as a benchmark score because it turns model adoption into a procurement question: how many accelerators are needed before an enterprise agent can meet its latency budget?
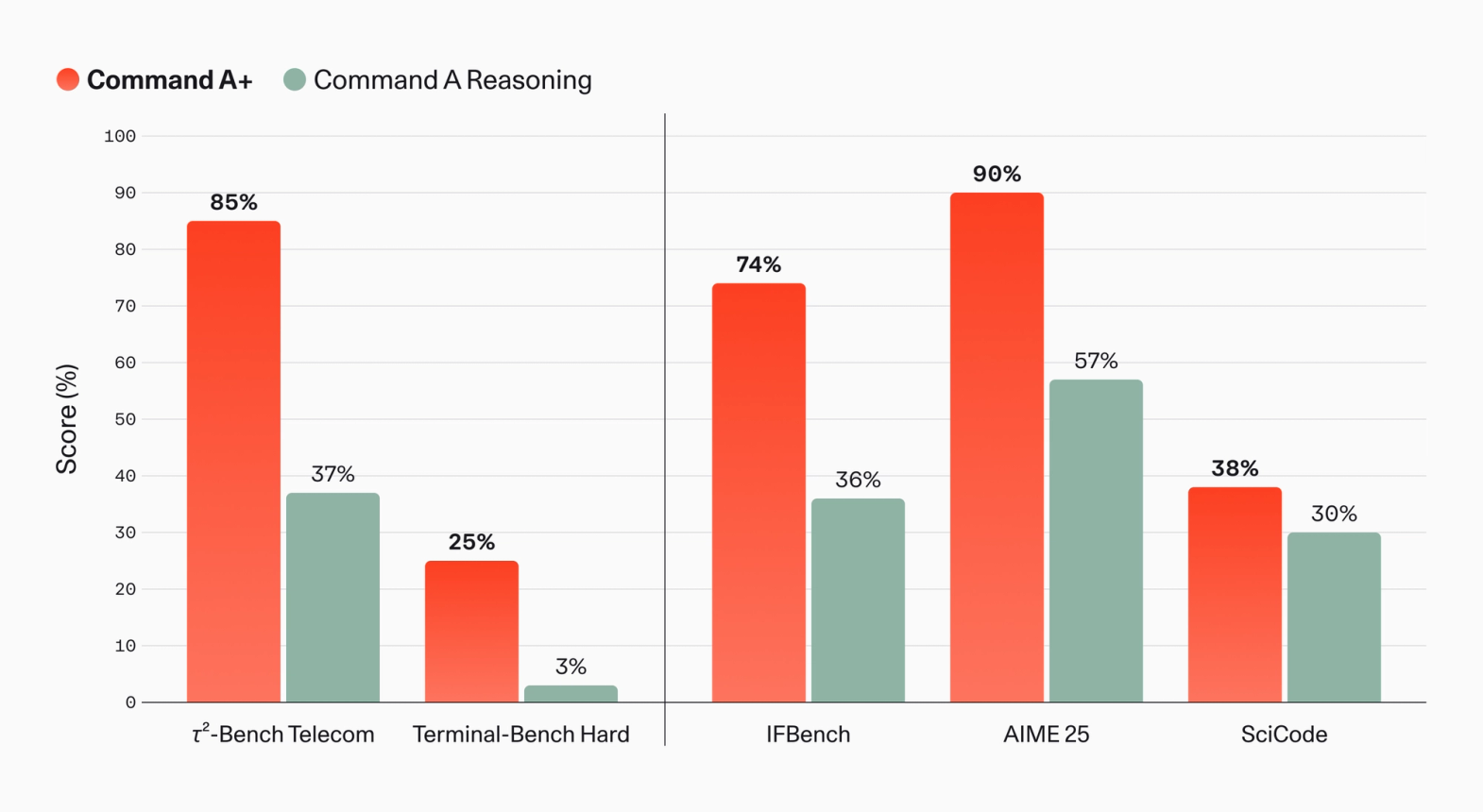
Command A+ is positioned closer to an enterprise agent model than a consumer chatbot model. Cohere groups tool use, agents, data analysis, memory usage quality, coding, vision, and translation in the launch material. Its agentic benchmark chart gives separate scores for agentic question answering, data analysis, and memory usage quality. In Cohere's chart, Command A+ beats Command A Reasoning on agentic QA by 65% to 45%, on data analysis by 45% to 13%, and on memory usage quality by 54% to 39%.
Those numbers should not be read as an independent leaderboard. They are Cohere-run benchmarks. They do show which buyer questions Cohere is trying to answer. Teams running enterprise agents do not only ask whether a model can reason in a clean chat prompt. They ask whether the model can retrieve the right internal document, keep tool results straight, handle a data-analysis task without drifting, and stay inside a latency budget. They also need to know whether the model can run in a VPC or on company-controlled hardware.
The MoE architecture is central to that pitch. The headline model size is 218 billion total parameters, but only 25 billion parameters are active for a request. Instead of running every weight as a dense model would, the model routes work through selected experts. Cohere's one-B200 or two-H100 claim follows from that deployment strategy. For a company operating inference internally, the question is less "how many billions of parameters are on the model card?" and more "how many GPUs are needed to hit the service-level objective?"
The Hugging Face model name also points in that direction: CohereLabs/command-a-plus-05-2026-w4a4. W4A4 indicates 4-bit weights and 4-bit activations. Cohere is not just saying the weights can be downloaded for research. It is packaging the model around quantized serving, Apache 2.0 licensing, private deployment, and enterprise channels. That makes Command A+ part of a broader contest over where inference should run: a managed API, a partner cloud endpoint, or infrastructure inside the customer's own boundary.
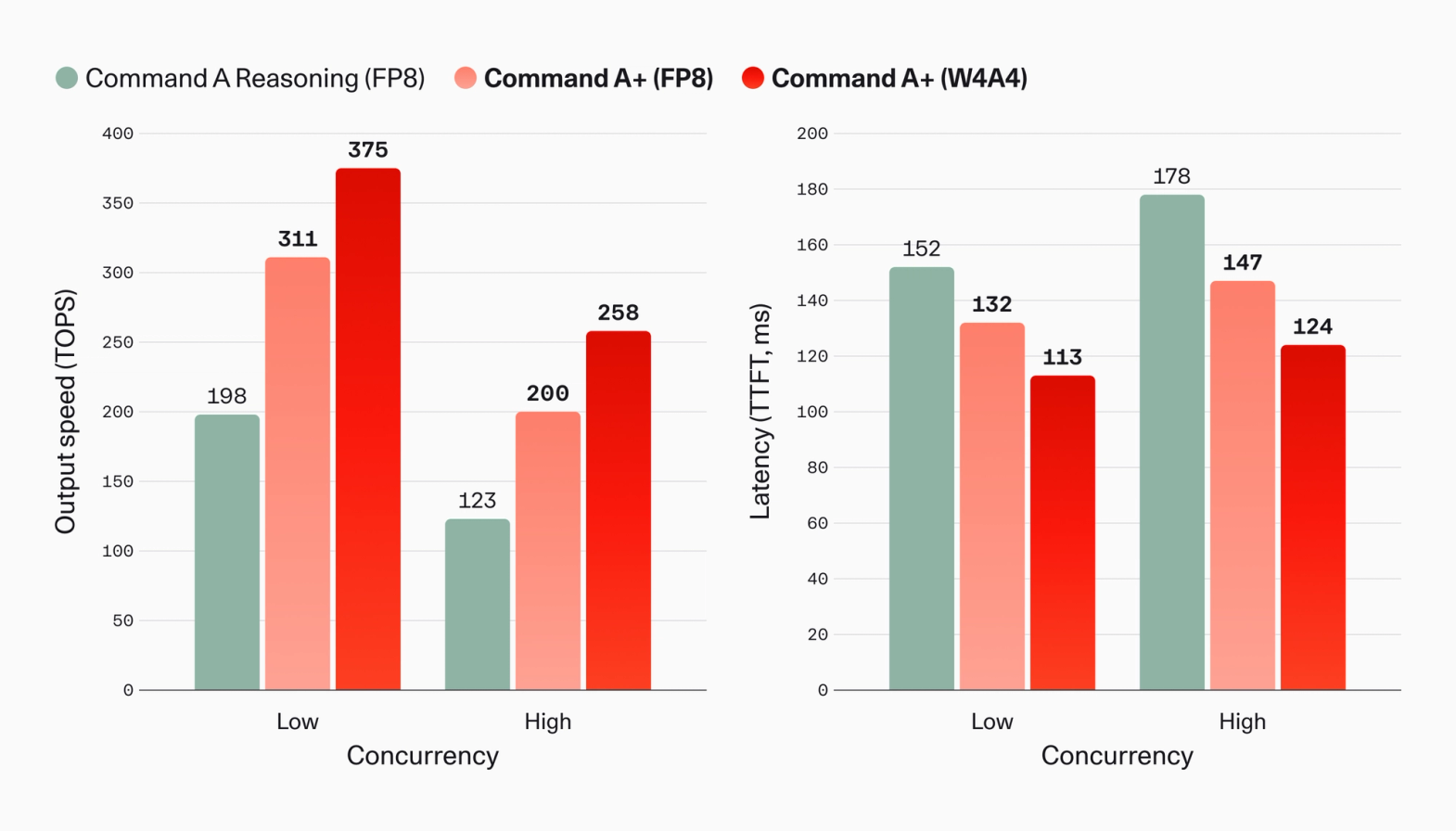
The speed chart makes the serving claim more concrete. Cohere compares Command A Reasoning FP8, Command A+ FP8, and Command A+ W4A4. At low concurrency, the chart lists output speed at 198, 311, and 375 TOPS. At high concurrency, it lists 123, 200, and 258 TOPS. Time to first token is shown as 152ms, 132ms, and 113ms at low concurrency, then 178ms, 147ms, and 124ms at high concurrency.
That frames Command A+ as a faster-to-serve enterprise model, not simply a larger model. A team evaluating open weights usually moves from "can we get the weights?" to "what serving stack will carry production traffic?" The answer may involve vLLM, TensorRT-LLM, SGLang, TGI, a cloud-managed endpoint, or an internal runtime. The team also has to choose whether FP8 or W4A4 is acceptable, and whether tool-calling bursts push time-to-first-token beyond the product's tolerance. Cohere moved those serving questions to the front of the launch.
Multilingual support is another part of the package. Cohere says Command A+ supports 48 languages and includes MT-AIME 2025 and WMT24++ charts in the announcement. Its graph reports Command A+ at 86% on MT-AIME 2025 versus 53% for Command A Reasoning, and 81% on WMT24++ versus 73%. For companies handling support tickets, contracts, policy documents, and internal knowledge bases across regions, multilingual quality can outrank English-only coding scores.
The 48-language claim still needs local evaluation. Cohere's announcement and model card do not break out detailed production benchmarks for every language. A team building Korean RAG, legal-document summarization, customer-support routing, or internal wiki agents should create its own eval set. Tool use adds another split: fluent answers in a language and accurate function arguments in that language are different measurements. An agent can sound natural while still filling the wrong schema field.
Vision is included as well. Cohere describes Command A+ as multimodal and publishes charts for MMMU, MathVista, CharXiv reasoning, and CharXiv descriptive tasks. In Cohere's chart, Command A+ scores higher than Command A Vision on MMMU by 75% to 65%, MathVista by 81% to 74%, CharXiv reasoning by 53% to 47%, and CharXiv descriptive by 88% to 82%. For enterprise agents, vision is less about captioning and more about invoices, tables, screenshots, product catalogs, and scanned documents that feed back-office workflows.
For developer tools, tool use and memory quality are more immediate. Cohere explicitly charts "Memory Usage Quality." That is a useful axis because production agents often fail after a tool call rather than inside the first answer. They reuse an old tool result, merge retrieved documents with user instructions, or treat stale context as authoritative. Each failure adds review work for the human operator. A model vendor highlighting memory quality is responding to a problem that agent buyers already encounter in traces.
Command A+ also blurs the line between API business and open-weight distribution. OpenAI, Anthropic, and Google lead with managed APIs and product surfaces. Meta, Mistral, Qwen, DeepSeek, MiniMax, and other families put more weight on open-weight deployment and self-hosting options. Cohere is trying to hold both positions. It offers the model through API and partner clouds, while also making open weights and private deployment part of the same story. For regulated industries, that combination can matter during procurement.
Compared with recent open-weight launches, Command A+'s differentiator is not maximum context length. MiniMax M3 led with 1M context and coding-agent benchmarks. Command A+ has a 128K context window. Cohere instead emphasizes two H100s, W4A4, 48 languages, enterprise deployment channels, and agentic benchmarks. That is closer to internal-document search plus tool-calling traffic than to loading an entire repository or archive into a single prompt.
The Apache 2.0 license is a practical adoption point. A permissive license lowers the barrier for commercial use compared with research-only releases. It does not remove the rest of enterprise review. Teams still need to examine the model card, acceptable use policy, weight provenance, dataset disclosure, export controls, and marketplace terms. If the deployment target is a private VPC or on-premises cluster, security review also needs artifact storage, access logging, signing, update process, and incident rollback details.
Community validation is still early. The research note for the Korean article found no strong standalone Hacker News or GeekNews thread around "Command A+" at writing time. The Hugging Face model page is available, but download and like counts are not enough to prove operational quality. Open-weight releases usually go through a sequence: launch charts circulate first, then serving recipes, quantization reports, tool-call regressions, and cost comparisons arrive over the following days or weeks. Command A+ still needs that second wave.
The first useful developer test is an agent trace, not a generic chat prompt. Run the same retrieval corpus, tool schemas, data-analysis task, and memory-heavy workflow against Command A+, the team's current Cohere model, Claude, Gemini, GPT, Qwen, Mistral, or another candidate. Record latency, output cost, refusal behavior, hallucination rate, function-call errors, and human intervention count separately. Cohere's numbers are a starting point; routing decisions should come from traces that resemble production traffic.
The second test is self-hosted serving. Try the W4A4 weights in the intended runtime and measure throughput under realistic concurrency. Check whether quantization changes answer quality, tool-call formatting, or multilingual behavior. Measure time to first token when an agent makes repeated calls rather than one isolated request. A model that looks fast in a benchmark chart can still miss an application's target if the serving stack, batch policy, or context shape is different.
The third test is governance. Decide where authority and cost move if Command A+ replaces a managed API. Managed APIs reduce operational burden but put model updates and parts of the data path under the provider. Self-hosting gives the team more control over data flow and release timing, but it requires serving engineers, GPU budget, monitoring, patching, and capacity planning. Cohere's one-B200 or two-H100 number is valuable because it translates that tradeoff into a purchasing and operations discussion.
Command A+'s clearest signal is packaging. Cohere combined Apache 2.0 open weights, a W4A4 model card, 128K context, 48 languages, agentic benchmarks, API access, cloud partners, VPC deployment, and on-premises deployment in one release. For companies moving AI agents into internal workflows, that creates a concrete option between fully managed frontier APIs and heavier self-hosted stacks. The next evidence should come from each team's traces, latency budget, security review, and GPU invoice rather than from the launch chart alone.