Command A+ Brings an Open Agent Model to Two H100s
Cohere released Apache 2.0 Command A+, a 218B MoE model with 25B active parameters, private deployment, tool use, vision, and multilingual agent workloads in scope.

- What happened: Cohere released
Command A+under Apache 2.0 on May 20, 2026.- The model is a 218B total, 25B active sparse MoE that combines text, image input, reasoning, translation, and tool use.
- Deployment claim: Cohere lists W4A4 serving targets as 1 x B200 or 2 x H100.
- Hugging Face cards are available for BF16, FP8, and W4A4, with examples for
vLLM, SGLang, Transformers, and Docker Model Runner.
- Hugging Face cards are available for BF16, FP8, and W4A4, with examples for
- Why builders should care: the competition point is less chatbot ranking and more private deployment, Korean tokenizer efficiency, tool-use evaluation, and inference cost.
- Watch: official benchmarks mostly compare against earlier Command A models, so teams still need direct tests against Qwen, Gemma, DeepSeek, Llama, and hosted frontier APIs.
Cohere released Command A+ on May 20, 2026. In the official announcement, Command A+ is described as a sparse Mixture-of-Experts model with 218B total parameters and 25B active parameters. Cohere positions it as an enterprise workhorse for complex reasoning, multimodal document processing, multilingual RAG, tool use, and agentic workflows.
The most useful number in the release is not only model size. It is the serving footprint. Cohere says Command A+ can run, in W4A4 quantization, on 1 NVIDIA B200 or 2 NVIDIA H100 GPUs. The Hugging Face model cards split the release into BF16, FP8, and W4A4 variants, and the W4A4 card lists requirements such as vLLM >=0.21.0 and cohere_melody>=0.9.0. This is not presented as a hosted-only model. Cohere is putting private deployment and self-managed inference near the center of the product story.
Command A+ also consolidates Cohere's earlier Command A family. Cohere's docs changelog calls it the "last model in the Command A family" and says it combines vision inputs, reasoning, translation, and agentic tasks in one model. Earlier releases separated the surface across Command A, Command A Reasoning, Command A Vision, and Command A Translate. With Command A+, Cohere is making a simpler application-routing argument: one model can cover more of the enterprise workflow without forcing every product team to maintain separate model choices for documents, translation, reasoning, and tool use.
Apache 2.0 changes the deployment conversation
The phrase Cohere repeats around this launch is sovereign AI. The official blog says Command A+ is freely usable under the Apache 2.0 license and frames the release around transparency, control, security, and data sovereignty for governments and regulated industries. A separate Cohere post uses "sovereign critical infrastructure" in the headline.
That positioning targets a different buying process than hosted frontier APIs from OpenAI, Anthropic, and Google. Banks, public agencies, manufacturers, defense organizations, and healthcare teams do not decide on model quality alone. Procurement documents often ask where data remains, whether inference logs are stored by an outside vendor, who owns fine-tuned derivatives, which region a fallback endpoint uses, and how audit evidence is preserved. A downloadable Apache 2.0 model changes the starting point for legal and security review.
The W4A4 Hugging Face card lists the license as apache-2.0. Its model summary says Command A+ has 25B active and 218B total parameters, is optimized for agentic, multilingual, and reasoning-heavy tasks, and supports vision input. The BF16 card presents the same license and model scale. That distinguishes this release from open-weight models that still carry separate commercial or field-of-use restrictions.
Apache 2.0 does not remove the operational bill. According to Cohere's Hugging Face cards, BF16 requires 4 x B200 or 8 x H100. FP8 requires 2 x B200 or 4 x H100. W4A4 reduces that to 1 x B200 or 2 x H100. "Can run" on two H100s is still far from production serving with latency SLOs, batch concurrency, observability, autoscaling, and failover. Command A+ lowers the license barrier; GPU operations remain a serious part of the decision.
| Quantization | Minimum Blackwell example | Minimum Hopper example | Practical reading |
|---|---|---|---|
| BF16 | 4 x B200 | 8 x H100 | High-cost deployment that prioritizes quality preservation |
| FP8 | 2 x B200 | 4 x H100 | Middle path for lower memory pressure and faster serving |
| W4A4 | 1 x B200 | 2 x H100 | Smallest hardware footprint highlighted by Cohere |
Read the benchmarks as agent-workload claims
The performance table in the Command A+ announcement is closer to enterprise agent workloads than a generic chatbot leaderboard. Cohere says Tau2-Bench Telecom improves from 37% on Command A Reasoning to 85% on Command A+. Terminal-Bench Hard rises from 3% to 25%. IFBench moves from 36% to 74%, AIME 25 from 57% to 90%, and SciCode from 30% to 38%.
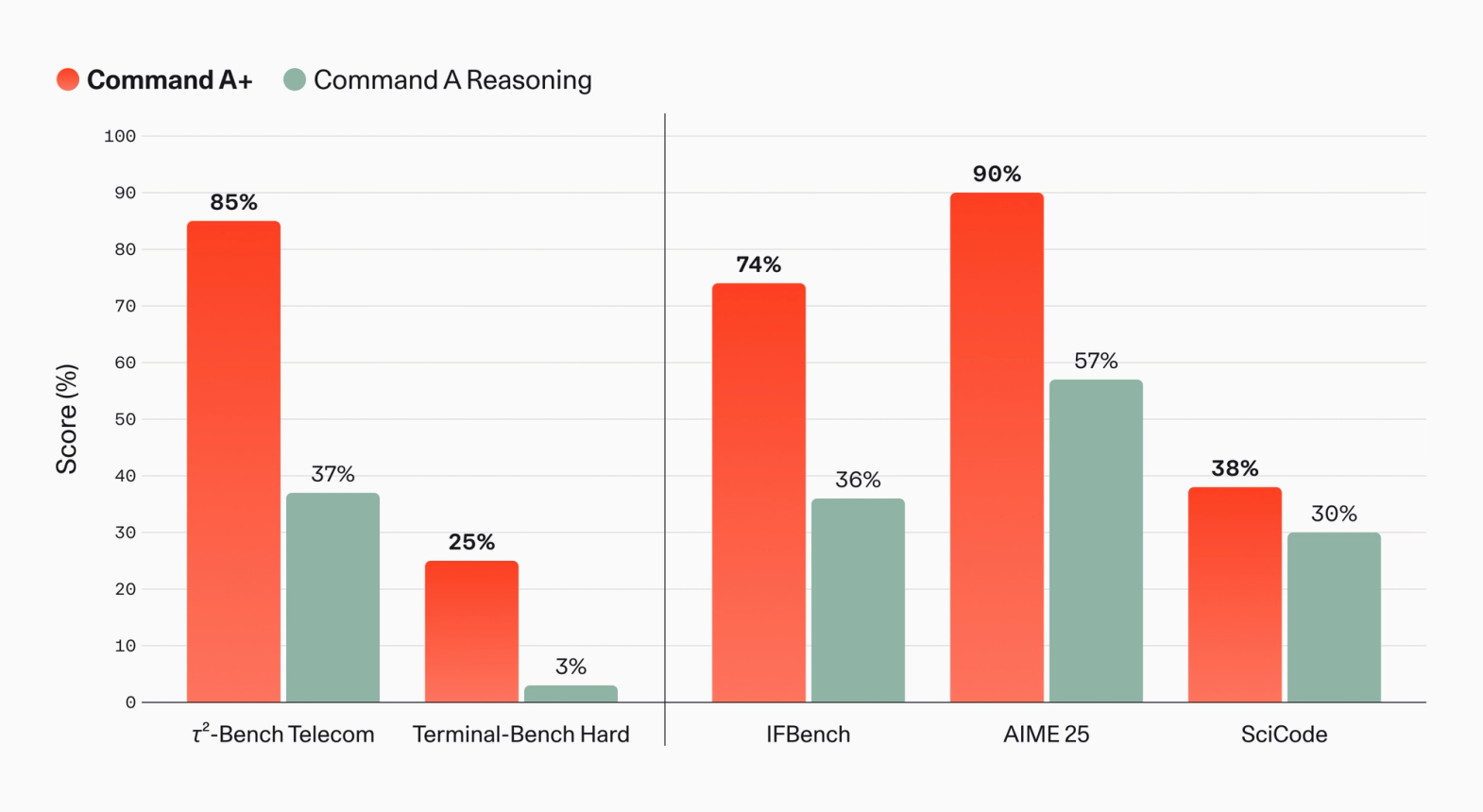
Tau2-Bench Telecom measures multi-step agentic tasks such as telecom customer-service workflows. Terminal-Bench Hard is closer to work performed in a shell or terminal environment. Their placement near the front of the launch material says a lot about the intended buyer. Command A+ is being sold less as a question-answering model and more as a model that can use tools to complete work.
The comparison set still needs caution. Cohere's chart mostly compares Command A+ against Command A Reasoning, not against every current open or hosted competitor. In the r/LocalLLaMA discussion of the Hugging Face card, several commenters asked for direct comparisons against Qwen-family models, noted the 25% Terminal-Bench Hard score, or argued that 128K context is no longer unusually long for open models.
That reaction does not make the release unimportant. It gives teams a sane validation sequence. First, acknowledge the improvement over previous Command A models. Then test Command A+ against Qwen, Gemma, Llama, DeepSeek, and hosted frontier APIs on internal workloads. Agent results are especially sensitive to tool schema design, permission boundaries, retry policy, external API latency, and prompt templates. A benchmark name alone rarely tells a product team whether the model will behave in its own agent loop.
The North signal
Cohere says Command A+ came partly from a year of deploying North to customers. North is Cohere's enterprise workspace, an agentic product that connects cloud file systems through MCP, works with spreadsheet analysis, and uses memory. The Command A+ blog says the model also improved on internal North application evaluations.
The numbers are specific. Cohere reports a 20% improvement in Agentic Question Answering accuracy over Command A Reasoning and a 32% improvement in spreadsheet analysis quality. Memory performance, measured as the ability to use stored data from previous sessions to answer follow-up questions, rises from 39% on Command A Reasoning to 54% on Command A+. Cohere describes this evaluation as LLM-as-a-judge.
Those internal metrics are more useful for application teams than a broad chat score. Agent products usually fail by picking the wrong file, missing a spreadsheet calculation, forgetting a previous constraint, or producing incorrect tool-call arguments. Cohere is claiming progress against those work-shaped failures. Because the numbers are judged by another LLM and come from Cohere's own product context, teams still need separate evals on their own accounting files, CRM exports, Jira backlogs, Korean reports, and permission models.
Korean tokenizer efficiency is an infrastructure detail
Command A+ supports 48 languages. Cohere's docs changelog lists Korean, Japanese, Chinese, Arabic, Hindi, Vietnamese, Thai, Turkish, Ukrainian, and Urdu, along with English and major European languages.
Cohere also introduced a new tokenizer for Command A+. The official announcement says the model requires fewer tokens to generate the same response and gives language-specific efficiency gains: Arabic 20%, Korean 16%, and Japanese 18%. For Korean-language engineering teams, that number is less about translation marketing and more about inference cost and context packing.
Korean business documents often mix particles, spacing variation, Sino-Korean terms, English product names, and internal abbreviations. Customer-support logs, legal files, meeting notes, financial reports, and product requirements all become expensive when placed into RAG context or agent memory. A 16% tokenizer-efficiency gain will not reproduce perfectly across every corpus. But if the same Korean paragraph consumes fewer tokens, teams can fit more retrieved chunks, tool results, audit context, or memory traces into the same budget.
Command A+ supports 128K input context and 64K max generation. Some long-context models exceed that input window, so tokenizer efficiency matters more rather than less. Agent products must pack tool descriptions, retrieved documents, previous decisions, and user constraints into one prompt. Every token affects latency and GPU memory pressure. A Korean service evaluating Command A+ should measure token count and answer quality on its own Korean corpus before relying on English benchmark tables.
Speed claims become a cost model
Cohere contrasts Command A+'s 218B total, 25B active MoE architecture with the 111B dense architecture of Command A Reasoning. Under the same quantization and concurrency conditions, Cohere says output tokens per second can be up to 63% higher and time to first token up to 17% lower. The company also says W4A4 quantization adds a 47% speed increase and 13% latency reduction.
Speculative decoding is part of the story. Cohere says its MoE-adapted speculative decoding delivers a 1.5-1.6x inference speedup across text and multimodal input. That has a direct cost implication for agentic workflows. Agents often produce a short reasoning step, call a tool, read the tool result, and call the next tool. If time to first token and small-batch throughput are poor, the user feels delay at every step.
The product cost model still depends on the full path. Cohere's TOPS claim measures tokens per second received after the first chunk during generation. Real services also pay for image preprocessing, tool execution, vector search, permission checks, network hops, logging, and retries. W4A4 can reduce model latency while the bottleneck remains an external SaaS API or an internal database. Teams should translate the serving benchmark into end-to-end traces before deciding whether the GPU bill improves.
Tool use and reasoning output need product boundaries
The Hugging Face model card tags Command A+ as Image-Text-to-Text, Transformers, Safetensors, cohere2_vision, conversational, and chat. Usage examples include Transformers pipeline, vLLM server, SGLang server, and Docker Model Runner. The vLLM and SGLang examples use OpenAI-compatible /v1/chat/completions calls.
That compatibility makes early experiments easier. Services already using OpenAI-compatible clients can often start by changing the endpoint and model id. Image input in the examples points toward enterprise workflows involving document screenshots, tables, slides, and product UIs. The model card also shows thinking generated between <|START_THINKING|> and <|END_THINKING|>.
For a product team, that thinking output is not just another text field. Teams need to decide whether reasoning text is shown to users, suppressed, excluded from storage, retained only in eval logs, or passed through PII scrubbing. Tool calls, final answers, reasoning traces, and audit events should not automatically share one log table. The more a model combines reasoning and tool use, the more the application layer needs explicit channel handling and retention policy.
Community reaction is closer to "verify it" than "believe it"
The r/LocalLLaMA thread on the Hugging Face model card was broadly positive about the release itself and more reserved about performance claims. Some commenters welcomed the Apache 2.0 license and the addition of another large sparse MoE to the open ecosystem. Others liked that the release looked more open than earlier licensing approaches and found a 218B total, 25B active multilingual model interesting.
The skeptical side focused on context length, missing direct competitor benchmarks, and how Terminal-Bench Hard compares with Qwen-family scores. That reaction reflects the current state of open-model users. They are no longer satisfied with official launch charts alone. They want to know which quantization works on their GPUs, how fast it serves, how stable tool calls are, and whether the model beats local alternatives on their own data.
That skepticism is healthy for development teams. Command A+ has a strong advantage as an Apache 2.0 model suitable for private deployment. It also carries the operating cost of a 218B MoE. Before putting it into a product, teams should separate three questions. First, is the quality gap between W4A4 and FP8 acceptable for the target workload? Second, how does the model handle Korean documents mixed with images, tables, and citations? Third, as tool schemas grow, how often does it omit required arguments or propose unsafe actions?
This is AI infrastructure news, not only a model release
Command A+ is a model launch, but the article-worthy part is infrastructure. License, quantization, vLLM and SGLang support, private deployment, tokenizer efficiency, and speculative decoding are all deployment decisions. The relevant question is not just which model name appears in an API call. It is where the model runs, which GPUs it needs, which data boundary it respects, and what latency it can sustain.
The question becomes sharper for agents. A customer-support agent that reads CRM and payment data may be easier to approve on a private endpoint than on a hosted API. A coding agent that reads internal repositories and tickets raises questions about whether code snippets and secret-scan results leave the organization. A public-sector RAG agent that processes sensitive documents must satisfy regional, contract, and audit requirements. Command A+ gives those teams another alternative to a frontier API.
It is not an automatic answer. Self-hosting brings patching, model-weight provenance, GPU quota, serving-runtime CVEs, prompt-log retention, abuse monitoring, and eval regression. Cohere's Model Vault and other managed private deployment paths can reduce that burden, but they also change the responsibility boundary. Teams need to decide what they actually want to own: the model weights, the serving runtime, the GPUs, the logs, or only the private endpoint contract.
A short checklist for engineering teams
Start with license and procurement. Apache 2.0 does not mean every company policy automatically allows open model weights. Legal and security teams may still ask for model provenance, training-data disclosure, acceptable-use terms, export-control considerations, and customer-data handling. Cohere's official announcement, Hugging Face cards, and the Apache 2.0 license should all be part of the review packet.
Next, inspect the serving runtime. W4A4 depends on vLLM >=0.21.0 and cohere_melody>=0.9.0 in the model-card example. If the existing inference stack is built around older vLLM, TensorRT-LLM, Ollama, or llama.cpp, support status matters. A model running once in a demo is different from production readiness with observability, autoscaling, graceful shutdown, and request cancellation.
Then design the eval. Cohere's official benchmarks include agentic QA, spreadsheet analysis, memory, Terminal-Bench Hard, and Tau2-Bench Telecom. Internal evals should mirror that shape. Test RAG answer accuracy, spreadsheet calculation, Korean document summarization, image-table extraction, function-calling argument accuracy, unsafe-tool refusal, and memory recall as separate metrics.
Finally, consider hybrid routing. Sending every request to Command A+ is not the only architecture. Workflows that contain private data, customer logs, regulated documents, or internal code can route to a private Command A+ endpoint. Lower-risk public knowledge or brainstorming requests can still be compared against hosted frontier APIs. A model router for agents should classify data boundary and cost, not only benchmark quality.
Open model competition now includes GPUs and permissions
Command A+ is more than "Cohere released another model." The package combines Apache 2.0 licensing, a 218B total and 25B active MoE, W4A4 deployment on 2 x H100, 48 supported languages, a claimed 16% Korean tokenizer-efficiency gain, and improved tool-use-oriented benchmarks. Cohere is targeting enterprise agents that need private deployment more than personal chatbot novelty.
Adoption still requires caution. The official benchmarks mostly compare against earlier Command A models. Community users want direct checks against Qwen, Gemma, DeepSeek, and other open competitors. W4A4 lowers the hardware footprint, but two H100s are still expensive for many teams. Thinking output and tool-call logs also become part of the product's security design.
For AI engineering teams, the launch raises a concrete question: will model selection include license, GPU footprint, tokenizer efficiency, tool reliability, and private deployment, or only leaderboard quality? Command A+ puts the broader question in front of developers. As agents touch more internal tools and documents, model competition will be decided as much by deployment location and permission boundaries as by benchmark rank.