Devlery - AI news for builders
Devlery blog
AI news for builders.

Finding issues without keywords, Copilot gets a triage index
GitHub Copilot Chat semantic issue search moves issue search from keyword matching toward a backlog-understanding layer for coding agents.
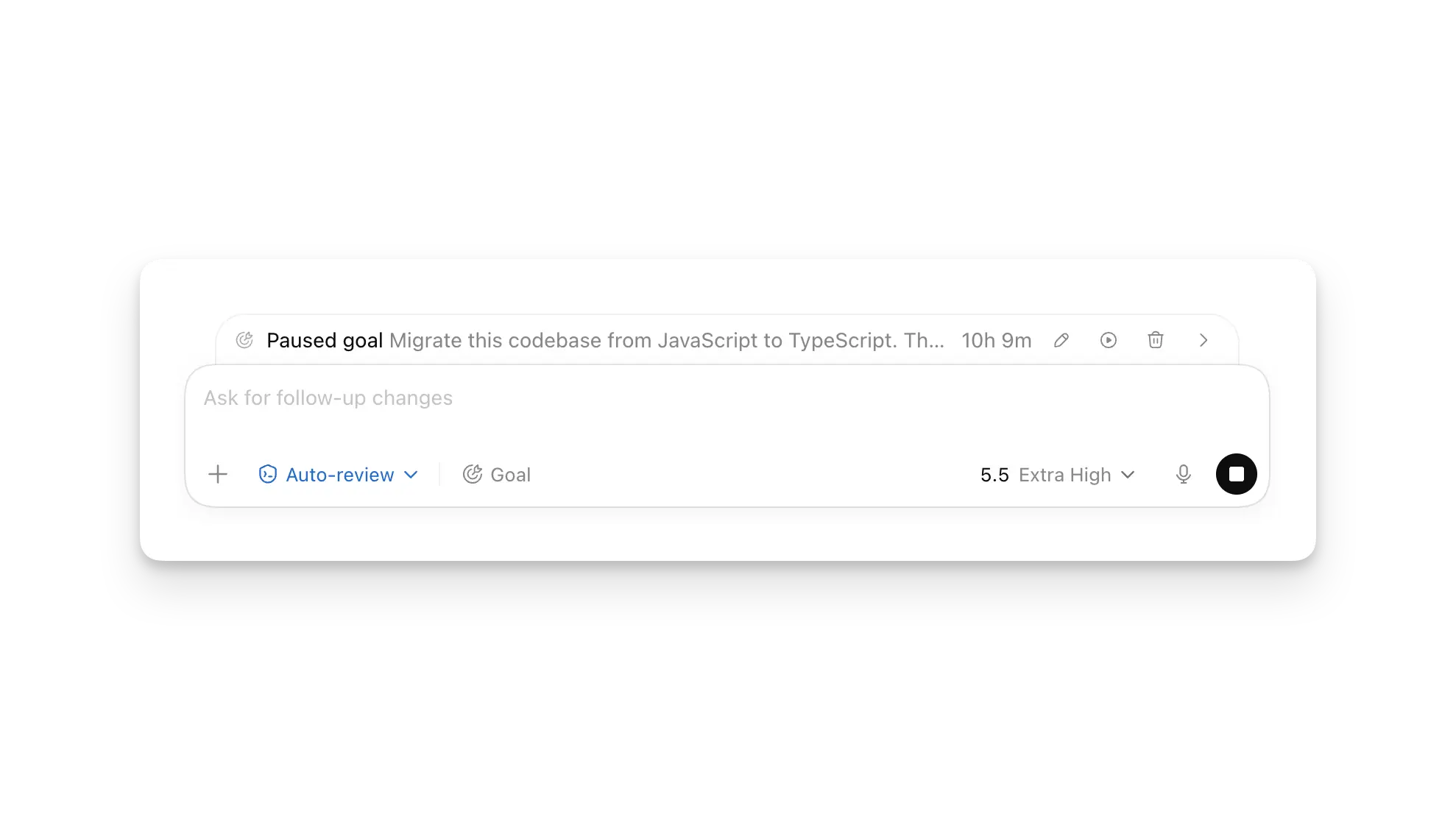
Codex now works on a locked Mac, and Goal mode redraws the agent boundary
OpenAI added Appshots, Goal mode GA, browser annotations, locked computer use, and admin analytics to Codex. The update shows coding agents becoming longer-running workers.

Preferred sources come to AI Search, and Google gives clicks a new button
Google is extending Preferred Sources and Highly Cited labels into AI Overviews and AI Mode. Here is what it means for AI search, publishers, and RAG product design.

React Doctor hits 11.1k stars as AI React audit layer
React Doctor adds a post-generation audit loop for React code written by coding agents, scanning state, effects, performance, security, and accessibility.

The same PR, a 12.5x bill: what coding agents really cost
Joule Index V0.1 adds dollars, joules, and public traces to coding-agent benchmarks, shifting the question beyond accuracy alone.

The 41-Commit Illusion: Claude Code and the Developer Frontier
A new arXiv paper finds broader language and repository activity after Claude Code adoption, but the causal story is still unresolved.

SRE agents stall at 47% on real Kubernetes incidents
Artificial Analysis ITBench-AA shows that even leading SRE agents remain below 50% on Kubernetes root-cause analysis, exposing the reliability gap in operational AI.

OpenAI Adds Live Vote Counts to Election Answers
OpenAI outlined its 2026 election safeguards, combining AP vote counts, voting information, Codex Security, SynthID, usage policy, and political bias evaluations.

620,000 attacks expose a 35-point safety gap in reasoning models
TELUS Digital tested 34 AI models with more than 620,000 adversarial attacks. The benchmark shows why enterprise AI safety is now an operating discipline.

90% of PRs are agent-built, Warp exposes the new bottleneck
OpenAI and Warp show that the coding-agent race is shifting from code generation to open-source verification, observability, and agent orchestration.

HTTP 402 is back, and AWS is drawing the guardrails for agent wallets
AWS AgentCore Payments preview turns AI agent payments into an infrastructure problem of x402, session budgets, credentials, and audit logs.

Furiosa and Broadcom are designing a 2nm token factory
FuriosaAI and Broadcom’s third-generation inference chip plan shows how agentic AI is shifting the bottleneck from raw GPU speed to token density, networking, and power.