Blog
Notes and analysis on AI development.
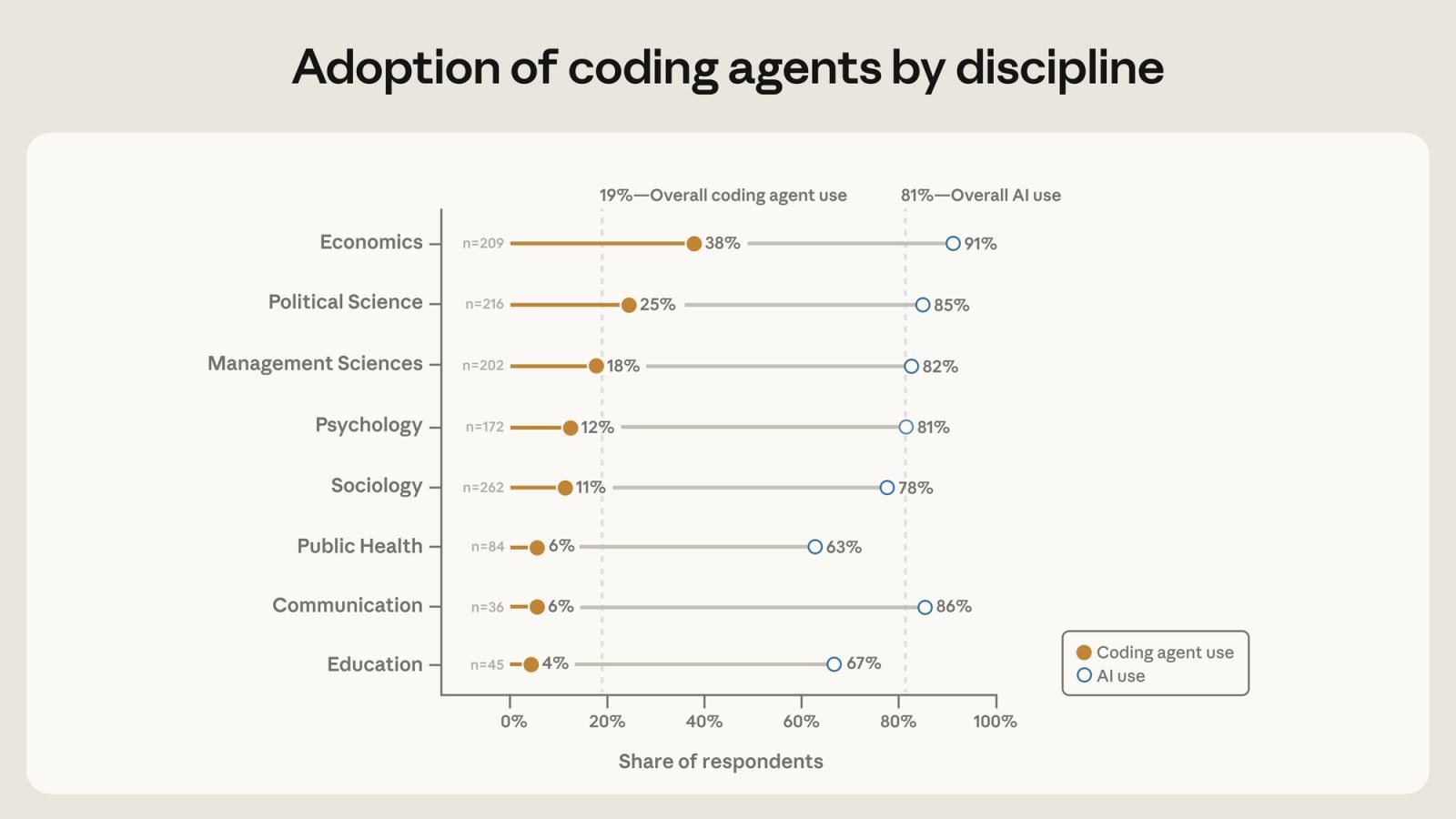
Only 20% of social scientists use coding agents, exposing a research productivity gap
Anthropic surveyed 1,260 quantitative social scientists: 81% have used AI for research, but only 20% regularly use coding agents.

Claude Code adds hundreds of subagents as Opus 4.8 keeps price pressure on
Anthropic released Claude Opus 4.8 and Claude Code dynamic workflows, tying model pricing, subagent orchestration, and agent API control into one developer story.

CoreWeave Puts Agent Improvement Loops in the Cloud With 40% Cost Claim
CoreWeave bundled Serverless RL, W&B Weave, Sandboxes, and MCP into a cloud stack for improving production AI agents.

Mistral Vibe now reaches PRs, physics AI, and its own inference site
Mistral AI Now Summit bundled Vibe agents, industrial physics AI, and a 10MW inference data center into one enterprise AI stack.
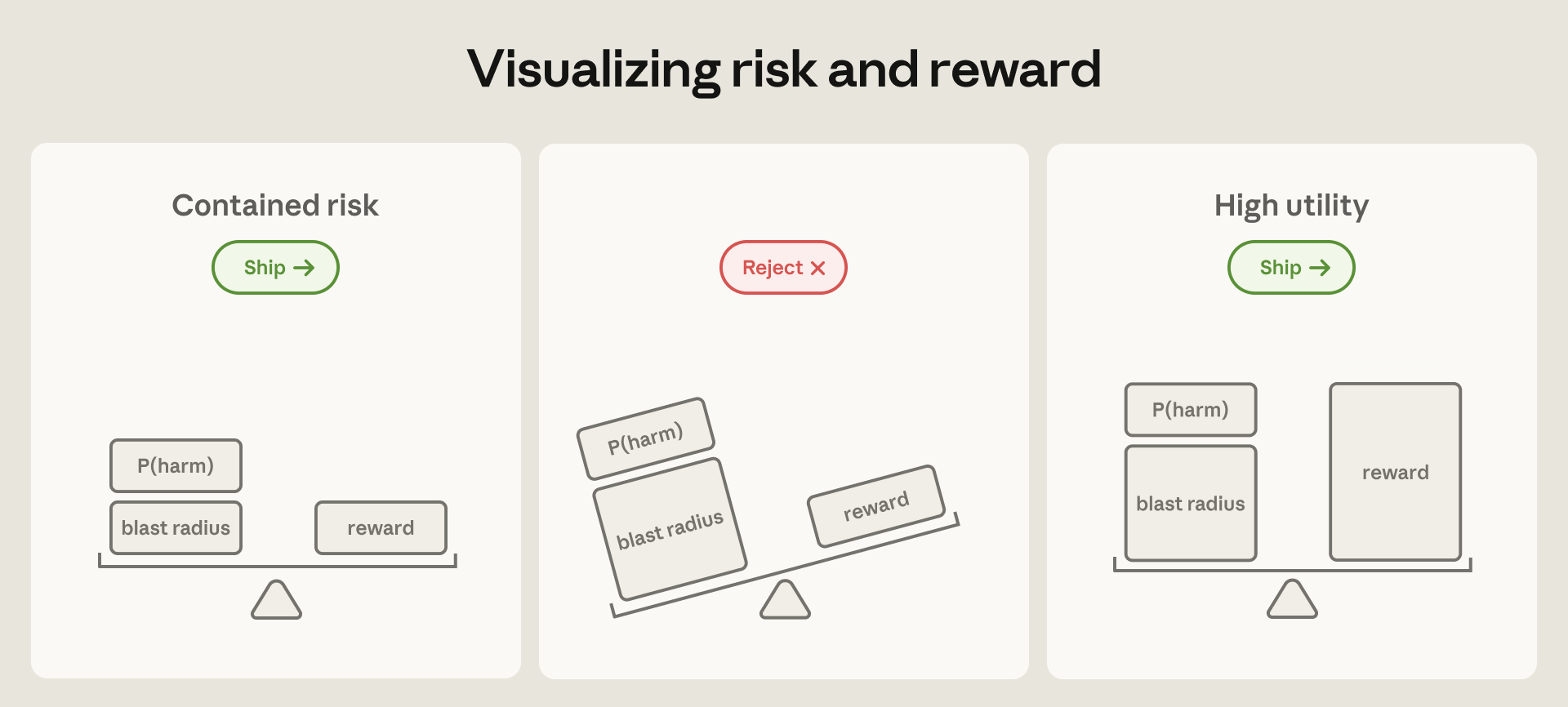
Anthropic published Claude containment details, and 24 AWS key thefts explain the risk
Anthropic detailed the isolation design behind Claude Code and Claude Cowork. The numbers turn agent security from approval prompts into sandbox, VM, and egress policy.
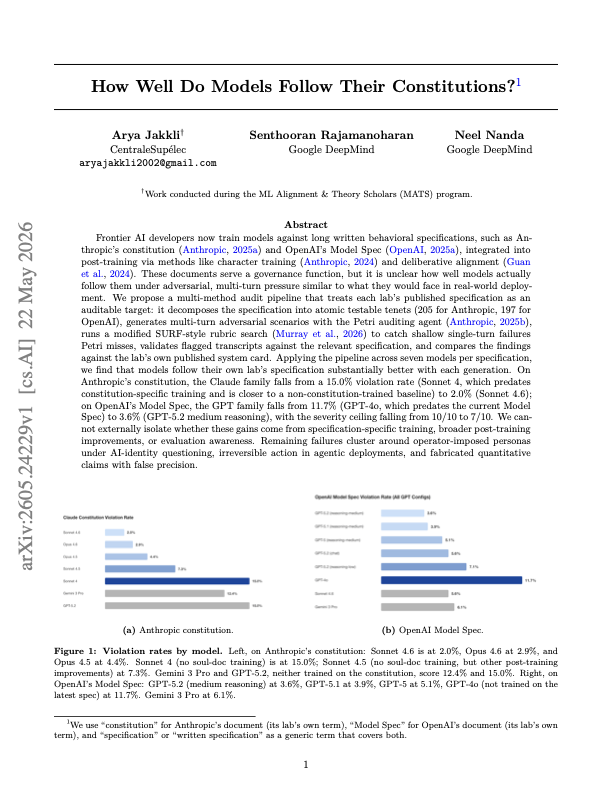
2.0% Violation Rate Turns AI Behavior Specs Into Auditable Contracts
A new paper turns Claude Constitution and OpenAI Model Spec into testable audit targets, showing how model policies are becoming benchmarks.

Copilot Memory now has an off switch, and agent memory becomes a permissions problem
GitHub added deletion guidance, repository-level off switches, CLI controls, and scope prompts to Copilot Memory. The update turns coding-agent memory into a governance surface.
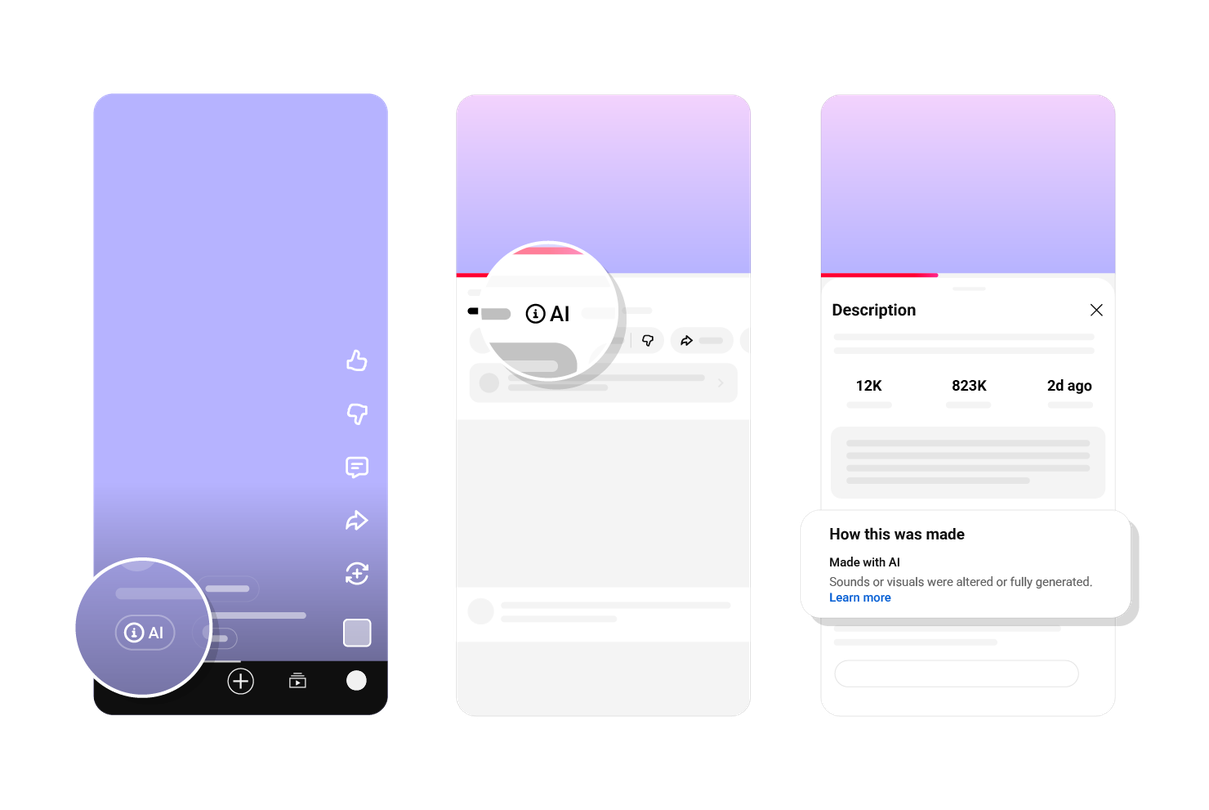
YouTube Will Auto-Label AI Videos as Detection Moves to the Platform
YouTube is moving AI-generated video labels onto the player surface and adding automatic detection for realistic AI media. Here is what changes for creators, viewers, and AI product teams.

Decepticon 1.1.3 Tests the Guardrails for Autonomous Red-Team Agents
Decepticon 1.1.3 shows that red-team agents are now competing on rules of engagement, sandboxing, graphs, release integrity, and auditability.

Takane gains 28 points as Fujitsu narrows safe self-evolving agents
Fujitsu self-evolving multi-AI agents show how enterprise LLMs may keep improving through verified feedback, design-search loops, and operating controls.

CopilotKit Puts $27M Behind the Agent UI Layer
CopilotKit’s $27M Series A turns AG-UI into a signal that agent competition is moving from models and tools into user-facing interface protocols.

Model Choice Becomes Org Policy Before Copilot AI Credits
GitHub Copilot targeted model rules arrive just before the June 1 AI Credits switch, turning model choice into an org-level cost and security control.