Takane gains 28 points as Fujitsu narrows safe self-evolving agents
Fujitsu self-evolving multi-AI agents show how enterprise LLMs may keep improving through verified feedback, design-search loops, and operating controls.

- What happened: Fujitsu announced self-evolving multi-AI agent technology on May 25, 2026.
- The system feeds task results, human feedback, regulatory changes, and specification changes into a verified improvement loop.
- Key number: Fujitsu says domain-specific tuning of
Takaneimproved average accuracy by28 pointsacross manufacturing, healthcare, finance, and public administration tasks. - Why it matters: The agent race is moving from task execution toward verified operational self-improvement.
- Watch: The 28-point figure is Fujitsu's own evaluation claim, so adoption still depends on audit logs, rollback, data boundaries, and regulated-environment validation.
Fujitsu announced self-evolving multi-AI agent technology on May 25, 2026. The headline language sounds familiar: multiple AI agents work as a team, inspect task results, incorporate human feedback, and improve their next actions. The useful part is where Fujitsu placed that loop. This is not a general chatbot memory feature. The announced applications are the business-specific LLM Takane, a large hospital electronic medical record system, and design-specification search for local-government business systems.
Fujitsu also put a number on the claim. The company says its agents automatically strengthened Takane and kept improving it during operation, producing an average accuracy gain of 28 points over the pre-specialized model across manufacturing, healthcare, finance, and public administration domains. In the healthcare example, the task is to extract diagnostic names, stages, and treatment policies from unstructured medical records and test results into a structured format for a specific business process. That number is not an independent benchmark. It is Fujitsu's official evaluation result. Still, the operating model is worth attention: the company is not describing a one-time tuning pass, but a loop that turns production results into the next set of improvement signals.
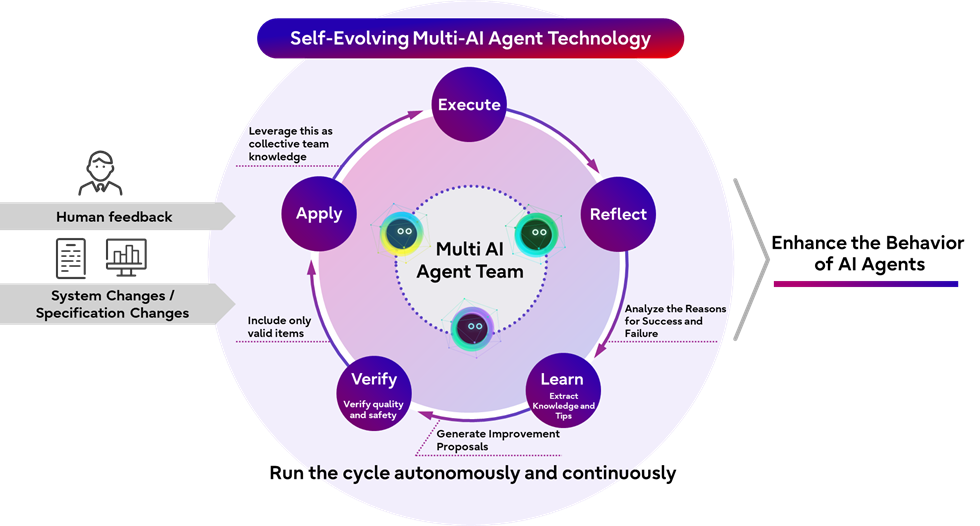
Source: Fujitsu official announcement, May 25, 2026.
Fujitsu defines the technology as a system in which multiple agents split work and continuously improve follow-up behavior based on task outcomes, human feedback, policy updates, and specification changes. The announcement says existing AI agents can process instructions, but struggle to independently analyze failure causes and safely turn those lessons into future operating rules. Fujitsu is therefore moving part of the work usually handled by experts, including prompts, search methods, evaluation criteria, and operating rules, into an agent-managed improvement process.
The target is not just a prompt
Self-improvement is often used loosely in agent products. A system remembers a conversation, retries a failed tool call, or avoids an answer a user disliked, and the product copy calls it learning. Fujitsu's announcement is more specific. The improvement loop covers data selection, learning-condition adjustment, evaluation, improvement proposal generation, verification, and application to business-specific LLM development. Agents propose changes, and only changes whose effects are verified are incorporated.
That phrase, "only verified changes," carries most of the engineering weight. A poorly designed self-improvement loop can learn from failure in the wrong direction. The model can invent a plausible cause, adopt an unsupported change, and contaminate the next generation of prompts, retrieval rules, or datasets. Fujitsu says generated improvement proposals are not simply stored and reused. They are filtered through business execution results and evaluation outcomes. Without that filter, a self-evolving agent is less an operations system than an automated drift machine.
The related research context points in the same direction. Fujitsu's announcement links to the arXiv paper Evidence-Verifiable Self-Evolving Agents, submitted on May 21, 2026. The paper argues that a self-evolving search agent should not only generate its own questions and answers for learning, but also keep verifiable evidence spans for those answers. One of its central claims is that agents should not train on examples they cannot justify. The product announcement and the paper should not be treated as the same system. The shared design pressure is clear, though: self-improvement needs evidence and verification, not just more memory.
Where the 28-point Takane claim comes from
Fujitsu applied the technology to automated enhancement of Takane, the LLM co-developed by Fujitsu and Cohere. In the announced loop, multiple agents select data, adjust learning conditions, evaluate outputs, and generate improvement proposals. Instead of asking humans to repeatedly choose domain data, rewrite prompts, and adjust scoring criteria, Fujitsu wants an agent team to perform that iteration under verification.
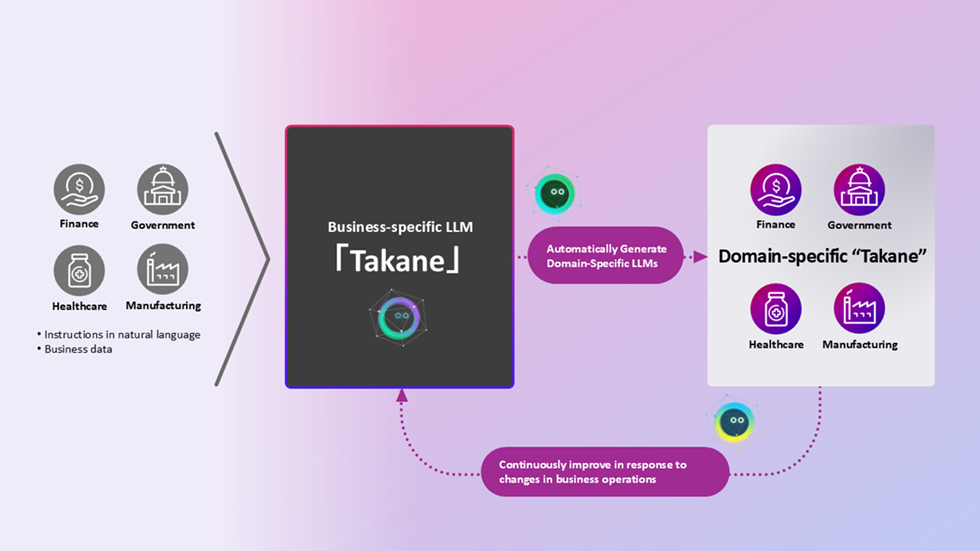
The practical target is tuning cost. For enterprise LLMs, the bottleneck is rarely only the base model call. The harder work is making the model handle local rules, exceptions, document formats, and business thresholds. Healthcare billing, municipal administration, financial screening, and manufacturing quality control all have dense rulebooks, and those rules change. Even after a model is specialized, laws, internal policies, forms, and system specifications can alter the answer standard. Fujitsu is aiming at that ongoing adjustment cost.
The 28-point accuracy improvement should be read carefully. Fujitsu says average accuracy improved across several domains, but the public announcement gives limited detail about the benchmark set, task distribution, baseline, and scoring method. The defensible reading is that Fujitsu saw a large gain in its own business-specific evaluations. It should not be read like an open leaderboard result comparing frontier models. For enterprise buyers, however, this distinction may be acceptable. Procurement teams often care less about the model name and more about measured accuracy on their own workflows and the cost of maintaining that accuracy as rules change.
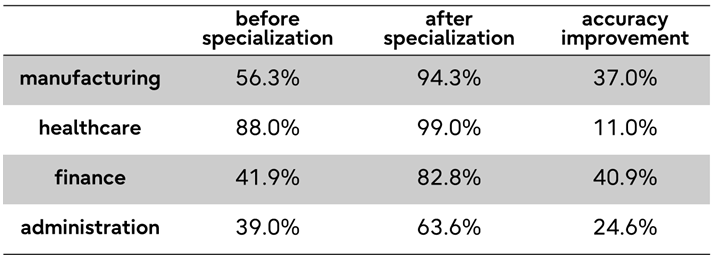
The healthcare example shows why that matters. The model is not being asked to explain general medical knowledge. It is being asked to extract diagnostic names, progression stages, and treatment policies from hospital records and laboratory results in the exact structure required by a business process. It has to respect the hospital's forms, extraction criteria, allowed omissions, and auditable output format. If agents can learn from task results and corrections while staying inside a verified update path, LLM operations starts to look less like prompt engineering and more like business quality management.
Design-spec search is a real enterprise bottleneck
Fujitsu's second application is design-specification search in large business systems. The company says it applied the technology to a medium-to-large hospital electronic medical record system and to local-government business solutions. When a law or policy changes, teams need to find which functions, screens, calculation rules, and data fields are affected. Traditionally, experienced people who understand regulation, business process, and system structure search related documents and judge the impact.
This work is less glamorous than a coding-agent benchmark, but it is common in enterprise IT. Older business systems scatter documents across many formats. Design documents and actual implementation may not fully match. The same rule can appear in screen descriptions, database definitions, batch-design documents, and test documents. Keyword search misses relevant files when the wording differs. Broad search returns too many documents for a practical review.
Fujitsu's announcement says the agents learned search habits from experienced specialists. For example, prior search results, failure cases, and human corrections can improve how the agents expand the search range and extract documents. The announcement describes techniques such as checking related surrounding documents and avoiding premature exclusion of documents that look unrelated but belong to the same business domain. This is not a problem where the model should jump directly to an answer. It is an operations problem around recall, precision, and search strategy adjustment.
The same theme connects to Fujitsu's AI software-development platform. On February 17, 2026, Fujitsu announced an AI-Driven Software Development Platform meant to automate requirements definition, design, implementation, and integration testing. The company said it would apply the platform to modifications across 67 healthcare and government software products by the end of fiscal 2026, and claimed that a proof of concept for Japan's 2024 medical-fee revision reduced roughly three person-months of work to four hours. The May self-evolution announcement can be read as a lower-level loop for keeping impact analysis and design search quality improving inside that broader platform.
The safety line has to be explicit
When self-improving agents enter enterprise work, the risk changes shape. A normal agent can make a mistake in one task. A self-improving agent can carry that mistake into the next operating rule. A wrong search range, biased evaluation criterion, incomplete business rule, or outdated legal interpretation can become an accepted improvement and raise the failure rate of later tasks. For that reason, automatic incorporation has to be discussed together with audit, approval, and rollback.
Fujitsu puts safe self-evolution near the center of the announcement, but the public details leave important operating controls open. External readers cannot yet see which proposals are applied automatically, which require human approval, how a failed improvement is rolled back, how each business evaluation set is maintained, or what logs are retained when agents are deployed in customer environments. Those questions are not peripheral. They are the first checks enterprise teams should make before allowing an agent to modify its own prompts, retrieval rules, evaluation criteria, or tool policies.
The implementation questions are concrete. Can an agent-generated improvement be reviewed like a code diff? Does the system version the exact change to a prompt, retriever, evaluation rule, or tool policy? When overall accuracy rises, did recall fall on a smaller but regulated subtask? If regulatory documents or medical records become improvement data, do they leave the customer environment? After a bad proposal is applied, can the team trace how many tasks it affected?
| Control point | Signal in Fujitsu's announcement | Question for adoption teams |
|---|---|---|
| Proposal adoption | Only proposals with verified effects are applied. | Are validation criteria and approval owners documented? |
| Business data | Agents adapt to customer environments and individual rules. | Does learning or evaluation data move outside the customer environment? |
| Search strategy | Failure cases and human corrections improve retrieval behavior. | Does higher recall also create unacceptable review noise? |
| Recovery | The announcement emphasizes safe continuous improvement. | Are versioning, rollback, and impact tracing available? |
This is not only Fujitsu's problem. Anthropic, OpenAI, Google, Microsoft, IBM, and AWS are all selling enterprise agents and workflow automation. As execution authority expands, the competitive measure shifts from model scores toward operating control. Better answers still matter. The longer-lasting differentiator is whether the improvement loop lives inside evidence, logs, approval, and recovery procedures.
Why on-premises and edge matter here
Fujitsu says it plans to integrate the technology into its proprietary AI platform and Fujitsu Kozuchi AI platform. The company also mentions joint research with Carnegie Mellon University's Graham Neubig and Tim Dettmers, and says it will combine the work with Fujitsu's generative AI reconstruction technology to reduce memory and power use for self-evolving multi-AI agent systems. The target environments include cloud as well as highly confidential on-premises and edge deployments.
That matches Fujitsu's likely customer base. Hospitals, public agencies, financial institutions, and manufacturers cannot always move their data and systems into a public cloud. Business records, patient information, design assets, and regulated documents may be subject to external-transfer restrictions. A self-improving agent that learns from operational failures and human corrections handles even more sensitive logs. On-premises and edge operation is therefore not just a deployment option. It is often a sales condition.
There is a tradeoff. Keeping the learning loop inside the customer environment helps with data sovereignty and confidentiality. It also makes central model and evaluation updates harder. As customer-specific environments diverge, support costs rise. If each customer's self-improvement loop evolves differently, the vendor must track which version is operating under which rules. Fujitsu's references to its OneFujitsu initiative and global standard processes connect to this problem. Standardized processes make agent improvements more comparable.
What builders should take from it
This announcement is not an SDK release that developers can install today. It still gives AI product teams several useful signals. Agent value is expanding from task execution into task-quality improvement. Enterprise AI needs more than a strong RAG pipeline or well-designed tool calls; it needs a way to update search strategies and evaluation criteria during operation. Any self-improvement feature has to be tied to evidence, evaluation, human correction, and versioning.
Teams building coding agents or internal workflow agents should design for what remains after failure. If the failure log is only an error message, the next task will not improve. If the failure log is fed into prompts or policies without verification, the system drifts. The practical lesson from Fujitsu's approach is to treat failure as a learning signal while requiring a validation step before that learning changes operating behavior. That principle applies beyond hospital specification search. It applies to code review, security triage, customer support, and financial-analysis agents.
Community reaction appears limited so far. The Korean source research found no deep discussion of the Fujitsu announcement itself on Hacker News or major Reddit AI communities; most search results were reposts, short regional news summaries, or Fujitsu material. That does not make the announcement irrelevant. It means the news has not moved developer discourse the way an OpenAI or Anthropic model release might. A large Japanese systems integrator's healthcare and government automation work is still a useful signal because it shows which problems appear when agents meet legacy business systems.
Fujitsu's self-evolving agents now need answers beyond the 28-point number. Which tasks, datasets, and scoring rules produced the gain? How long did the improvement hold? How were bad proposals rejected? How are customer-specific rules versioned? Where does human approval remain mandatory? Self-evolving agents become operable systems only when those questions have concrete answers.
The agent market is pushing toward more tool calls, longer autonomous runs, and broader permissions. Fujitsu's announcement asks the next question: if an agent learns from its own work, who verifies what it learned and why? Takane's 28-point claim is notable because it puts that question near the center. The narrow safe path for self-improving agents starts where an improvement becomes an operating rule only after it passes evidence and evaluation.