Only 20% of social scientists use coding agents, exposing a research productivity gap
Anthropic surveyed 1,260 quantitative social scientists: 81% have used AI for research, but only 20% regularly use coding agents.
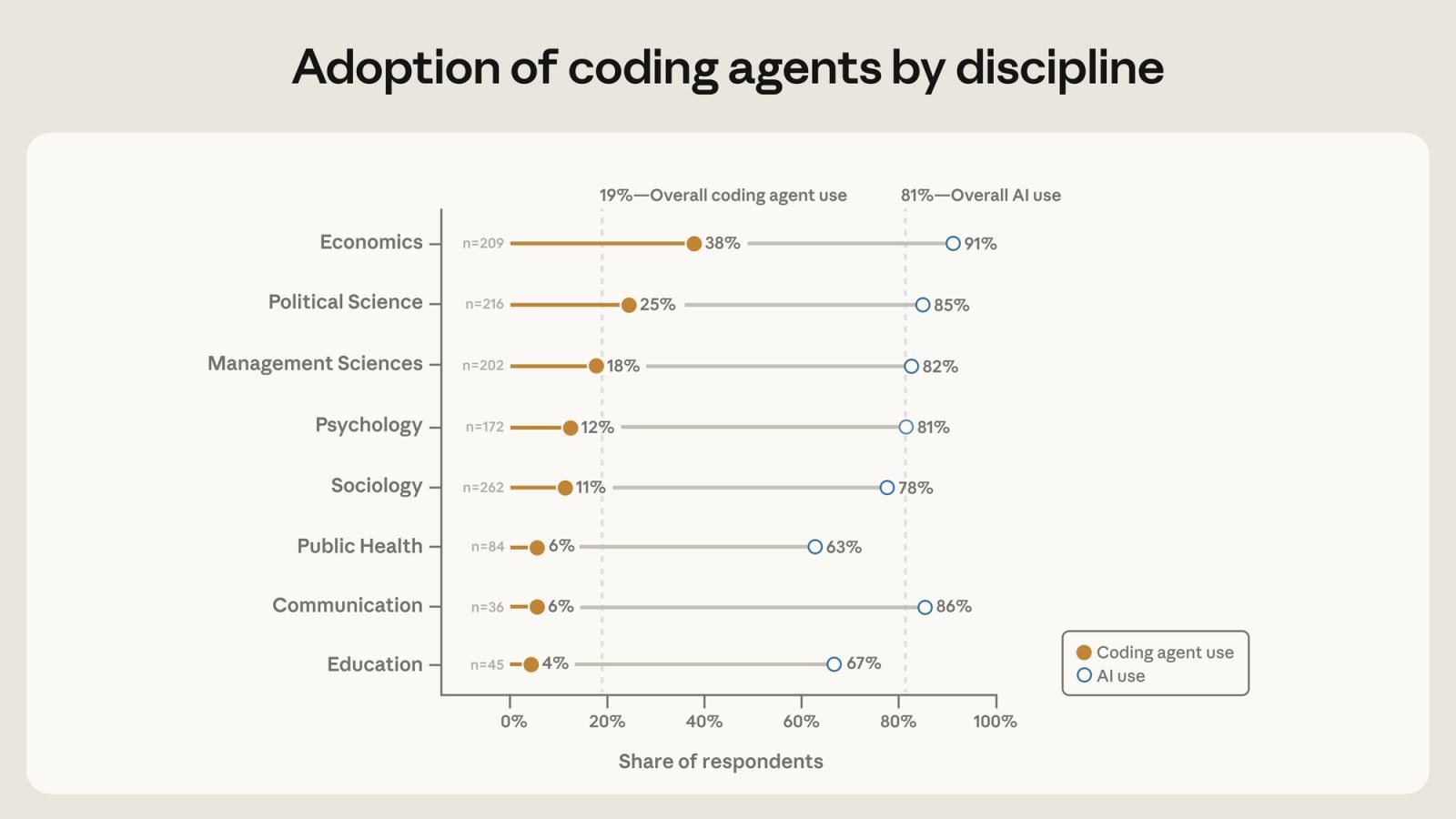
- What happened: Anthropic published a survey of 1,260 quantitative social scientists on AI and coding-agent use.
- 81% had used generative AI for research, while 20% reported using CLI-integrated coding agents such as Claude Code, Codex, Cursor, or Google Antigravity at least weekly.
- Adoption gap: Economics reached 38-39% coding-agent use, PhD students reached 27%, and respondents classified with male-associated names reached 22%, compared with 9% for female-associated names.
- Productivity signal: Coding-agent users reported more working papers and grant proposals, but Anthropic frames the comparison as descriptive rather than causal.
- The survey did not find evidence of more new journal submissions or resubmissions, and quality evaluation is left for follow-up work.
- Developer impact: Coding agents are moving beyond software teams into data-heavy knowledge work, where verification, access control, and reproducibility become product requirements.
Anthropic's May 27, 2026 research note, "Coding agents in the social sciences", reads less like a Claude Code marketing post and more like a baseline survey of how research work is changing. The sample covers 1,260 quantitative social scientists in the United States and Canada who responded between February 20 and March 24, 2026. Among them, 81% had used generative AI in their research process. Only 20% said they regularly used command-line-integrated coding agents such as Claude Code, Codex, Cursor, or Google Antigravity at least once a week.
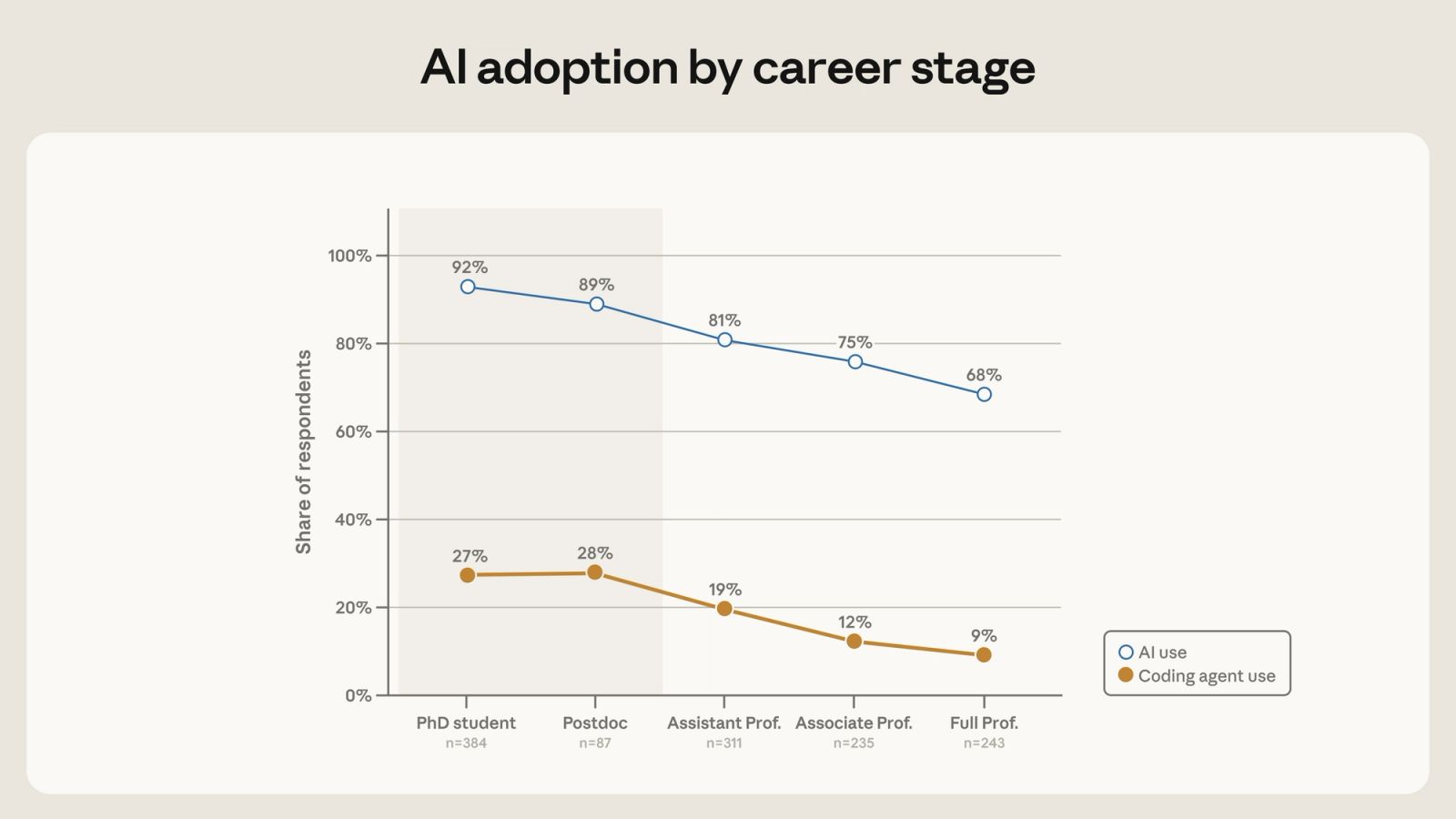
That split matters because the developer-tool market is no longer confined to software engineers. Anthropic's chart reports coding-agent use at 38-39% in economics, 25% in political science, 18% in business science, 12% in psychology, 11% in sociology, 6% in public health, 6% in communication, and 4% in education. PhD students and postdocs were at 27% and 28%, while full professors were at 9%. Respondents whose self-reported first names were classified as usually male reached 22%; respondents whose names were classified as usually female reached 9%.
Chatbots are broad, agents are narrow
Anthropic separated general AI use from coding-agent adoption. The first survey question asked whether respondents had used generative AI models in the research process. That captured the now-common behavior of asking ChatGPT, Claude, or a similar model for coding help, editing, methods advice, or literature background. The second question asked whether they regularly used a command-line-integrated AI coding assistant such as Codex, Cursor, or Claude Code at least weekly, and then checked for actual use of those tools or Google Antigravity.
The distinction maps cleanly to how software teams already think about agents. Asking a chatbot for a code snippet is not the same operational unit as giving an agent a dataset, letting it write analysis code, running the code, reading the error log, modifying local files, and iterating until the output is usable. In social-science research, that loop touches research design, regression code, robustness checks, visualization, replication packages, and manuscript drafts.
Anthropic describes coding agents as systems that can receive research ideas and datasets, write analysis code, execute it, interpret results, and iterate autonomously. That is not an abstract future scenario for quantitative researchers. Many daily research tasks already live in R, Python, Stata, notebooks, scripts, tables, and chart pipelines. A coding agent has a large surface area because the work is already code-adjacent, even when the user is not a professional software engineer.
The 1,260-person sample is probably AI-friendly
The survey should not be read as a clean estimate for every social scientist. The appendix says researchers were recruited through R1 and major Canadian university department websites, OpenAlex, conference programs, graduate directors, and academic mailing lists. Anthropic emailed 44,700 people directly. The final analysis sample was restricted to U.S. and Canada-based social scientists doing quantitative or empirical work, with PhD students included only when they had completed at least two years of training and planned to enter academia.
The second caveat is more important for interpretation: the survey was attached to recruitment for a randomized experiment that would provide access to Claude Max accounts. Anthropic notes that respondents may therefore be more interested in AI tools and more optimistic about them than the broader population of social scientists. The 20% coding-agent figure should not be treated as a conservative lower bound for the entire field. It is safer to read it this way: even in a sample interested enough to join an AI experiment, regular coding-agent use was still limited to about one in five respondents.
The question wording also aimed at a particular agent category. The appendix notes that the survey was fielded after Claude Cowork launched and before OpenAI released the Codex app. Researchers who used only a desktop agent may not have been fully captured by a CLI-centered definition. At the same time, the weekly-use threshold filters out one-off experimentation. The design is not measuring curiosity about AI. It is trying to identify coding agents that have entered a real research workflow.
Field and career gaps say more about work structure than model quality
The field-level spread is large. Economics led with 38-39% coding-agent adoption, followed by political science at 25%. Education was at 4%, while public health and communication were each at 6%. Economics and political science have strong quantitative-data cultures, working-paper circulation, replication packages, and preprint-based feedback loops. Public health and education also contain substantial quantitative work, but Anthropic's sample sizes for those fields were smaller, and the work can carry stronger institutional, ethics, and data-access constraints.
Career stage shows a direct path for diffusion. PhD students and postdocs were more likely to use coding agents than assistant, associate, or full professors. Anthropic interprets early adopters as more technically inclined, closer to the code and data, and under stronger pressure to produce research output. That explanation will sound familiar inside engineering organizations. New tools often attach first to the people who touch the files, tests, logs, and scripts every day, not to the people with the most formal authority.
For research teams, a coding agent is not just another productivity app. It can change how a PhD student prepares a replication package, how a postdoc produces preliminary analysis for a grant proposal, or how an assistant professor runs robustness checks across several projects. A researcher who can use agents effectively may start more projects or shorten more analysis loops. A researcher without access, training, or confidence may remain in a slower workflow. If that gap compounds, it can affect topic choice, collaboration opportunities, and publication timing.
The 22% versus 9% name-classification gap is hard to ignore
Anthropic classified respondents' self-reported first names with the Python package gender_guesser, producing categories for names usually associated with men and women. Unknown and androgynous names were excluded from that part of the analysis. The method does not directly measure gender identity, and it can misclassify names across countries and cultures. Those limits make it inappropriate to describe the result as the exact adoption rate for men and women.
Even with that caveat, the adoption gap is large. Respondents classified with usually male names reported 22% coding-agent use. Respondents classified with usually female names reported 9%. General AI use was much closer, at 81% and 78%. The gap therefore appears less in "has tried AI" and more in "has brought a CLI-integrated coding agent into research work." Anthropic also says the gap persists when comparing within the same field and career stage.
Institutional status points in the same direction. Respondents at Nature Index 2025 Top 25 institutions reported 24% coding-agent use, compared with 17% elsewhere. Private universities were at 23%, public universities at 17%. The coding-agent gap was larger than the chatbot-use gap. If coding agents raise research productivity even modestly, early access and training differences may amplify existing inequalities rather than flatten them.

Source: Anthropic.
Researchers use AI for code more than prose
Public debates about AI in academia often focus on generated prose, hallucinated literature reviews, peer-review overload, or low-quality automated manuscripts. Anthropic's survey points to a different center of gravity. Among coding-agent users, 97% reported using AI to generate quantitative data-analysis code. Among other AI users, 77% reported the same use case. By contrast, about one third of all AI users said they had used AI to draft prose.
That result changes the product question. For many quantitative researchers, the bottleneck is not a blank document. It is loading the dataset, handling missing values, changing a regression specification, regenerating a table, updating appendix charts, or rerunning a robustness check after a reviewer comment. A coding agent does not make those loops disappear, but it can read failures, edit files, and continue through the next run in a way a plain chatbot cannot.
For AI builders, the next customer for coding agents may be a social scientist, financial analyst, policy researcher, operations team, or marketing scientist. In that market, "coding" does not necessarily mean shipping an app. It means converting domain knowledge into executable scripts, notebooks, tables, and figures. That makes the agent's handling of local files, package managers, data permissions, notebooks, and reproducibility as important as its benchmark score.
Productivity signals are not causal evidence
Anthropic reports that coding-agent users started more projects, posted more working papers, and submitted more grant proposals than otherwise similar researchers in the same fields and career stages. The research note says coding-agent users looked roughly 10% more productive on empirical project starts and roughly 75% more productive on working papers posted, after controlling for career stage, field, and survey completion week.
That finding should not be translated into "coding agents increased productivity by 75%." Anthropic explicitly frames the comparison as descriptive. Coding-agent users may already be more productive, more experimental, better resourced, or more likely to have data access and collaborators. The survey is a baseline wave for a randomized experiment that gives Claude Code access to some researchers; the experimental results have not been published yet.
The more conservative findings are just as useful. Anthropic did not find evidence of increased new journal submissions or journal resubmissions. One explanation is that agents help researchers move from project idea to working paper more than they help with the final quality bar before journal submission. Another is that adoption is too recent for the effect to show up in journal cycles. A third is that more working papers may not translate into better publishable papers.
Quantity is easier to increase than quality
The largest missing variable is quality. The appendix says outputs were self-reported, and the research note focuses on counts of projects, papers, and proposals. More working papers do not automatically mean better identification strategies, cleaner data processing, more faithful statistical assumptions, or more reproducible analysis. Anthropic says follow-up work will evaluate the content and quality of coding-agent-augmented research.
The risk resembles a software team's risk when agents generate large volumes of code. Faster code generation can reduce time to first run. It can also hide a wrong statistical assumption, omit a sample restriction, apply the wrong clustering level, or turn robustness checks into superficial variations. In software, a flood of untested pull requests creates a review bottleneck. In research, a flood of weak working papers can create peer-review and replication bottlenecks.
Anthropic makes a similar point in its discussion. More papers can intensify competition for attention and crowd the scholarly record, while selective reporting and risk-averse incremental work may worsen. That is not primarily an AI-safety slogan. It is an operating problem for research systems. Agents can execute analysis faster, but they do not automatically decide which comparisons are valid, which null results should remain visible, or which findings should be reported.
Research labs preview the non-developer agent market
Social-science research labs are a useful preview of coding agents outside software engineering. The users are not primarily professional developers, but they rely on data and code. The output is not a deployed product; it is a paper, grant proposal, conference submission, replication archive, table, or chart. The failure mode is also different. A bug may not create an outage, but a flawed analysis can enter a research conclusion or policy debate.
That environment creates product requirements that also matter inside engineering teams. First, agents need provenance. A reviewer should be able to see which data files were read, which cleaning steps were applied, which model was run, and which output informed a claim. Second, execution output and narrative explanation need separate verification paths. A sentence interpreting a p-value is not the same artifact as the numeric result in the log.
Third, changes should be reviewable in small units. Data cleaning, model specification, plotting, and manuscript editing become hard to audit when one agent mixes them into a single large change. Fourth, data access and reproducibility need to be handled together. Research data can involve personal information, licenses, IRB constraints, and institutional servers. Those constraints mirror customer-data and production-access problems in companies.
The enterprise roadmap for coding agents therefore cannot stop at seats and model selection. It needs logs, permissions, sandboxes, reproducibility records, policy controls, and clear handoffs to human reviewers. The more useful the agent becomes with local files and data access, the more important it becomes to audit what it touched and why.
Individual productivity optimism is stronger than field-level optimism
Anthropic also asked respondents about expectations. One question focused on whether AI would increase productivity for writing publishable papers. Another asked whether AI would improve social science as a whole. On a 1-10 scale, 88% gave the paper-productivity question a score above 5, and half gave it 8 or higher. Researchers with more AI use cases and coding-agent users were more optimistic.
The same respondents were more cautious about the field-level effect. Anthropic says 70% were less optimistic about AI's effect on social science overall than about its effect on paper productivity. That gap is a useful warning for every agent-adoption discussion. One researcher may write faster. The whole field may still face more drafts, more submissions, more replication work, more review burden, and more variation in method quality.
Software teams face the same accounting problem. A developer can create a pull request faster with an agent. The organization may still lose time if reviews pile up, tests slow down, release risk rises, or security review becomes harder. Social scientists' answers captured that tension numerically: they were more willing to believe AI helps them write papers than to believe the resulting system becomes better.
What this news actually means
This survey does not show that AI is replacing social scientists. It shows that coding agents are entering the code-heavy parts of research work first, and that early adoption varies sharply by field, career stage, name-based gender classification, and institutional status. There is a productivity signal at the working-paper and grant-proposal stage, but the causal effect and quality effect remain unproven.
For AI product teams, three questions follow. First, what guardrails are required when non-developer knowledge workers hand code execution to an agent? Second, does agent adoption reduce existing gaps, or does it give a larger advantage to people already comfortable with CLIs, local environments, and data access? Third, when the quantity of output rises, does verification capacity rise with it?
Anthropic's next experimental results matter because the baseline survey can identify who already uses agents, while randomized Claude Code access can provide cleaner evidence about productivity, quality, and research choices. The current result is still concrete enough for builders: chatbot use is already widespread in social-science research, while coding-agent use is narrower and more uneven. The people who pass through that narrow entrance are reporting more working papers and grant proposals. Whether that becomes better research is still an open empirical question.
For developers, this is not a story happening outside their world. Coding agents are moving from IDE tools into data analysis and knowledge production. That move creates more users and more responsibility. Evaluating an agent product now requires more than asking which model writes the best code. Teams need to ask who can access it, which work it automates, what verification logs it leaves behind, and how it distinguishes output quantity from output quality.