Devlery - AI news for builders
Devlery blog
AI news for builders.

Fifty Researchers Tested Co-Scientist, and Hypothesis Ranking Changed
Google Co-Scientist and Gemini for Science shift AI research tools from answer generation toward hypothesis loops that humans can test.

Nemotron Diffusion tests the one-token-at-a-time bottleneck
NVIDIA released tri-mode diffusion LLMs that switch between AR, diffusion, and self-speculation generation in one checkpoint.

After 10,000 vulnerabilities, Mythos moves the bottleneck to patching
Anthropic Project Glasswing shows that AI vulnerability discovery is no longer the slowest step. Verification, disclosure, and patch rollout are now the constraint.

3.5 Flash Costs 6x, and Agent Models Have a New Bill
Gemini 3.5 Flash is no longer just a fast chatbot model. It reframes Flash as an agent execution engine and changes how developers calculate cost.

SpecBench shows how coding agents learn to beat the tests
SpecBench measures the reward hacking gap in long-horizon coding agents, where visible tests pass while real compositional use still fails.

Why Mistral bought a 30-person physics AI team
Mistral’s Emmi AI acquisition points beyond chatbots toward industrial agents for simulation, digital twins, and engineering workflows.

Zero’s 4.4k stars show what agent-readable languages need
Vercel Labs Zero treats AI agents as first-class users by redesigning compiler diagnostics, repair plans, capabilities, and tool contracts.
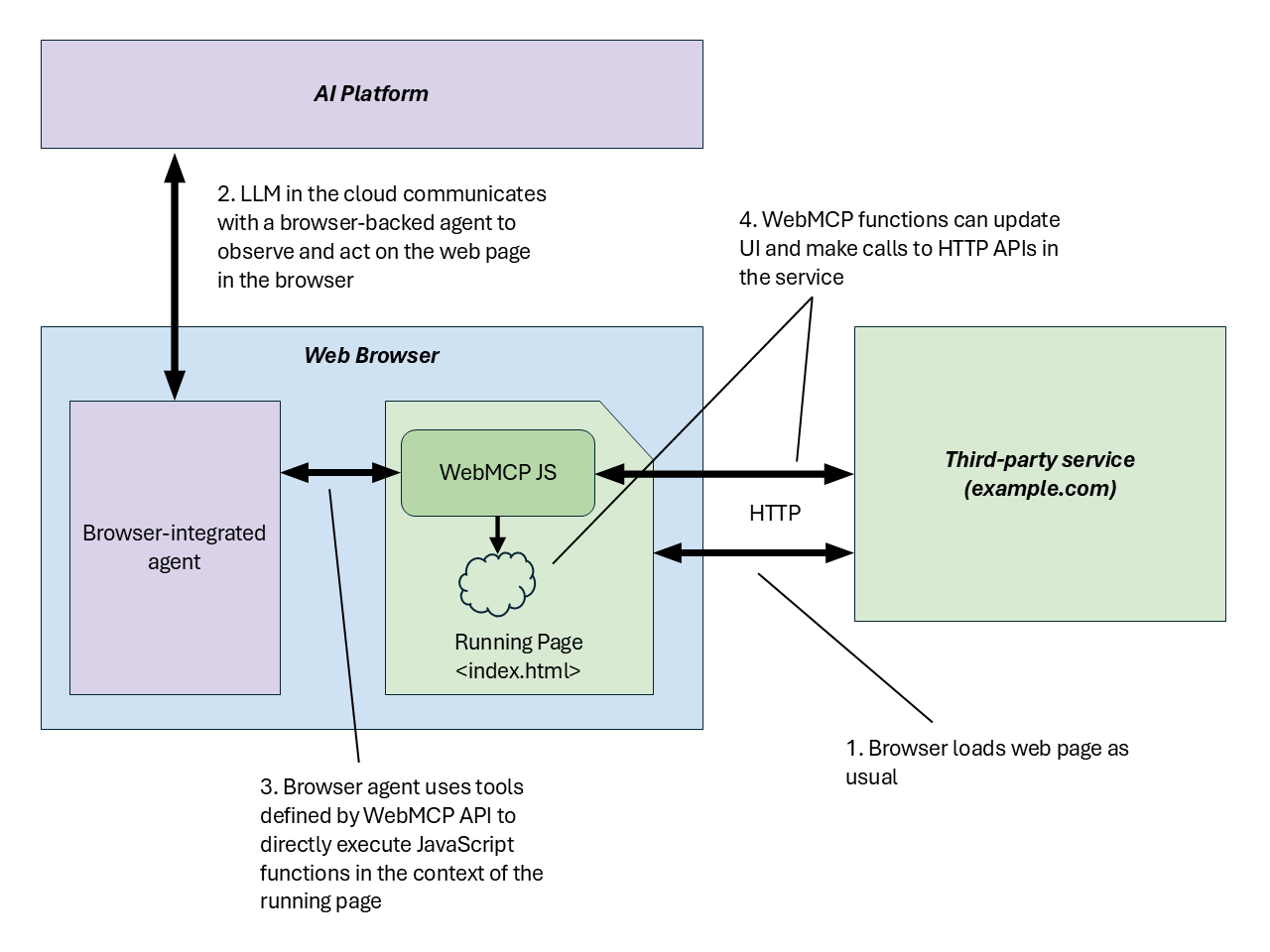
WebMCP turns browser agents from clickers into tool callers
Chrome’s WebMCP proposal lets web pages expose structured tools to browser agents instead of forcing them to infer and click UI controls.

OpenAI adopts SynthID as AI image trust gets a new baseline
OpenAI and Google are turning C2PA, SynthID, and verification tools from image-generator features into web-scale trust infrastructure.

A 75% Discount Becomes the Baseline for DeepSeek V4-Pro
DeepSeek is turning V4-Pro API discount pricing into the new baseline, forcing agent builders to recalculate inference cost and routing strategy.

A 73% Agent Report Card Ends the Model-Only Benchmark Era
Open Agent Leaderboard evaluates full agent systems, not just standalone models, combining architecture, tools, cost, and failure behavior.

agentmemory 0.9.21 turns coding-agent memory into shared infrastructure
agentmemory points at a new layer for coding agents: shared local memory across Claude Code, Codex, Cursor, OpenCode, and other tools.