OpenAI adopts SynthID as AI image trust gets a new baseline
OpenAI and Google are turning C2PA, SynthID, and verification tools from image-generator features into web-scale trust infrastructure.

- What happened: OpenAI announced a combined provenance stack:
C2PAsignatures, GoogleSynthIDwatermarking, and a public verification tool preview.- At I/O, Google said SynthID verification is expanding into Search and Chrome, while OpenAI, Kakao, and ElevenLabs are adopting it for more AI-generated media.
- Why it matters: Trust in AI images is no longer just a model feature. It is becoming infrastructure across browsers, search, APIs, metadata standards, and moderation workflows.
- For builders, provenance now touches CDN transforms, image editing, content review, audit logs, and user-facing uncertainty language.
- Watch: Absence of a signal does not prove an image is human-made. Metadata can disappear, and watermark detection is evidence rather than a final verdict.
OpenAI is making the provenance layer around AI-generated images thicker. On May 19, 2026, OpenAI announced a package of Content Credentials based on C2PA, Google DeepMind's SynthID watermarking, and a preview of a public verification tool. From a distance, this can sound like the familiar story of "putting a watermark on AI images." The more important change is that OpenAI's label is starting to sit inside a wider trust layer that also includes Google Search, Chrome, the Gemini app, the C2PA standard, and external adopters such as Kakao and ElevenLabs.
When AI image generation was just a product feature, provenance could be treated as an accessory. A visible mark under an image, or a line of metadata in a downloaded file, looked good enough. That no longer matches how images move. An image can be saved, screenshotted, resized, sent through messaging apps and social networks, embedded in articles, reused in ads, and copied into commerce pages. If the signal attached at generation time does not survive to the final viewer, the trust chain breaks.
That is why OpenAI's most important move is not a single marker. It is the combination: signed metadata, an invisible watermark, and a verification surface that ordinary users and operators can reach.
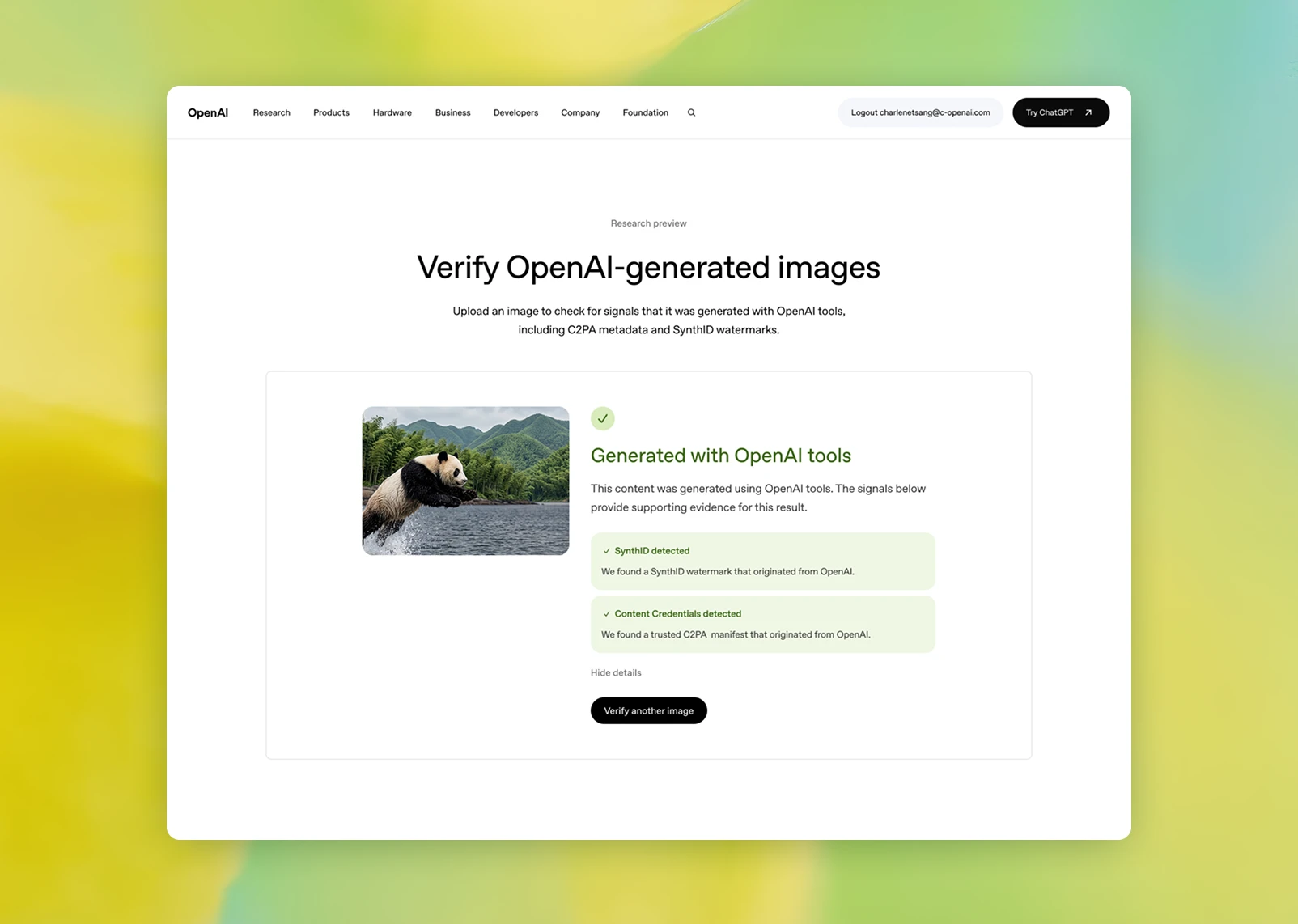
The two signals OpenAI is layering
The first pillar in OpenAI's announcement is C2PA, short for Coalition for Content Provenance and Authenticity. C2PA is a standard for carrying information about where content came from and which tools created or edited it, using file metadata and cryptographic signatures. OpenAI says it began adding Content Credentials to DALL-E 3 images in 2024 and later extended that support to ImageGen and Sora. This announcement emphasizes that OpenAI is now a C2PA Conforming Generator Product. In practical terms, that means platforms have a more standardized way to read, preserve, and pass along provenance information attached by OpenAI systems.
The second pillar is Google DeepMind's SynthID. OpenAI says it is applying SynthID first to images generated through ChatGPT, Codex, and the OpenAI API. If C2PA is closer to a signed description of the file's origin, SynthID is closer to a hidden signal inside the image itself. People are not meant to see it, but a detector can look for it.
The reason to use both is straightforward. Metadata can carry richer context, but it can be stripped during upload, download, format conversion, resizing, or screenshotting. A watermark carries less explanatory detail, but it has a better chance of surviving some transformations. They fail in different ways, so combining them is more useful than treating either one as the answer.
The third pillar is verification. OpenAI says it is previewing a public tool that lets users upload an image and check whether it appears to have been generated by ChatGPT, the OpenAI API, or Codex. The tool checks both Content Credentials and SynthID signals. The caveat matters: OpenAI does not say that a missing signal proves the image was not generated by OpenAI. Signals can disappear, and the initial tool scope is limited to OpenAI-generated images. That restraint is the real story. Provenance is not a magic truth machine. It is an evidence system that increases confidence by combining signals.
| Signal | Strength | Failure mode | Developer implication |
|---|---|---|---|
| C2PA | Can describe tools, publishers, and edit history in detail. | Metadata can be removed during platform upload or image transformation. | Original-file storage, signature validation, and provenance logs become important. |
| SynthID | Aims to leave a detectable signal after transformations such as resizing or capture. | The signal alone does not explain the full generation context. | Detection results need to feed moderation, review, and audit flows. |
| Verification UI | Gives users and operators an entry point for reading provenance signals. | Early tools are limited by generator, media type, and supported signal formats. | UX should avoid treating "not detected" as "safe" or "human-made." |
Google's announcement makes the story bigger
A day later, Google's I/O 2026 announcement roundup gave SynthID its own place in the broader product story. Google said SynthID began three years ago, and that verification inside the Gemini app has already been used more than 50 million times globally for images, video, and audio. Google also said the capability is expanding to Search immediately and to Chrome in the coming weeks. Users will be able to ask about image origins from surfaces such as Lens, AI Mode, Circle to Search, and Gemini in Chrome.
That is the larger shift: provenance is moving outside the generation app. Until now, AI image labels mostly lived inside the tool that created the image. If you stayed inside ChatGPT, Gemini, or a design tool, there was at least some chance that the origin information remained visible. The real web does not work that way. Images appear in search results, open in browser tabs, move through messengers, show up in marketplace listings, and land inside news articles. By making Search and Chrome verification surfaces, Google is treating provenance less as a generation feature and more as a web-browsing feature.
Google also said C2PA Content Credentials verification is starting in the Gemini app and expanding to Search and Chrome. It named OpenAI, Kakao, and ElevenLabs as organizations applying SynthID to more AI-generated content. That matters competitively. OpenAI and Google are direct rivals in model and product markets. But for media provenance, they are moving toward a shared watermark technology and overlapping verification surfaces. Competition continues at the model layer, while minimal provenance signals start to look more like interoperable public infrastructure.
Why Kakao's adoption matters
Kakao announced on May 20, 2026 that it is working with Google DeepMind to apply SynthID to its Kanana AI models. According to Kakao, SynthID will be applied to the Kanana-Kollage image model and Kanana-Kinema video model from the second half of the year, with earlier application to the Kanana Template feature in KakaoTalk. Kakao described itself as the first SynthID integration case in Asia.
For Korean readers, this is more than overseas technology adoption. Korea is preparing for enforcement of its basic AI law and an AI-generated content labeling regime in 2026. Kakao explicitly connected its SynthID work to that context, saying it wants to go beyond legal obligations by applying invisible watermarking to improve transparency and trust. In other words, SynthID is becoming both a global big-tech policy tool and a regional platform compliance tool.
For product teams, Kakao's move raises a practical question: in a regulatory environment where AI-generated content must be labeled, is a visible "created with AI" badge enough? Once a user saves, edits, and reuploads an image, that UI badge is gone. If file metadata, watermarking, generation logs, and verification APIs are designed together, later audit and dispute handling become possible. Kakao's case shows why AI content labeling is not just a frontend badge problem. It is product infrastructure.
What changes for developers
First, products that use image-generation APIs need to separate "generation" from "publication" in their records. An image may leave the model with provenance signals attached. After that, the service might resize it, upload it to a CDN, convert its format, create thumbnails, or allow users to edit it again. Whether the signal survives depends on that pipeline. C2PA is especially sensitive to this path. Teams need to know whether their image-processing stack removes metadata, what their CDN does during optimization, and how originals and derivatives are linked.
Second, moderation cannot collapse into a single "is this AI?" flag. Some AI-generated images should be allowed. Some real photos can be used with deceptive context. Provenance is one feature among many. Output review, user reports, perceptual hashing, EXIF data, C2PA validation, SynthID detection, account reputation, and publication context all belong in the same risk model. OpenAI's caution around missing signals points in the same direction.
Third, "not detected" UX needs care. Suppose a user uploads an image and the system finds neither C2PA nor SynthID. If the interface says "not AI-generated," it is overclaiming. The signal may never have existed, it may have been removed by a platform, or it may come from a generator the tool does not support. A better message is closer to "no supported provenance signal was found." That distinction can look minor in consumer UI. It is not minor for legal teams, marketplaces, newsrooms, election content moderation, or enterprise compliance.
Fourth, API design should preserve original evidence. When a user uploads an image, a serious system should store the original file, verification time, verifier version, detected C2PA manifests, SynthID result, file hash, and transformation history. For enterprise customers, the question "was this image AI-generated?" rarely ends at a real-time verdict. It can become an audit, an appeal, a legal preservation issue, or a partner API record.
The uncomfortable argument against C2PA
This announcement should not be read as "image authenticity is solved." In late April 2026, arXiv papers drew attention to provenance limits. GPT-Image-2 in the Wild analyzed 10,217 self-reported AI images collected from Twitter/X during the first week after GPT-image-2 launched. One important negative result was that the Twitter/X CDN upload process systematically removed C2PA Content Credentials, making cryptographic provenance verification of those social-media images effectively impossible.
Another paper, Verifying Provenance of Digital Media: Why the C2PA Specifications Fall Short, argues that C2PA is promising but should not be prematurely relied on as evidence in high-risk contexts. It warns that overconfidence in C2PA for financial disclosures, journalism, or legal evidence could mislead users, platforms, and policymakers. Whether one accepts the full argument or only part of it, the lesson for builders is clear: provenance standards are necessary, but not sufficient.
OpenAI's layered approach is best understood as a practical response to that critique. Metadata alone is not enough, so watermarking is added. Watermarking alone is not enough, so a verification UI is added. A verification UI alone is not enough, so missing signals are not treated as definitive proof. There is no perfect truth machine. There are only signals with different failure modes, combined into a more resilient evidence chain.
Who operates AI media trust?
The most interesting part of this news is not only the technology. It is the operating model. Trust for AI-generated media is hard for any single company to solve alone. The generator can attach a signal. Search engines and browsers can read it. Social platforms can preserve or strip it during upload. Newsrooms and enterprises can place verification results into their workflows. Regulators can define what counts as adequate labeling and logging. If any link breaks, the end user is alone again in front of an image.
That is why the OpenAI and Google overlap matters. OpenAI is one of the most widely used generation surfaces. Google controls major discovery surfaces through Search and Chrome. Kakao connects to messaging, content, and everyday platform usage in Korea and Asia. ElevenLabs represents the audio-generation side of the same provenance question. If these companies share watermarking and verification direction, at least some AI-generated media can carry a provenance path from creation to discovery.
This is still a baseline, not a complete solution. Bad actors can use tools that attach no signals. Open or local models can produce images through other paths. If a platform strips metadata, C2PA breaks. Watermark detectors need to manage false positives and false negatives. Camera-side provenance still has to connect signing at capture time with later AI edits. Mixed images, where real photography and generated elements sit together, require more granular ways to explain which parts were captured and which parts were synthesized.
The practical reason this announcement matters is that media trust requirements are moving down into product requirements. Teams adding image generation should now ask more than "which model API should we use?" They need to ask where the media was generated, which signals are attached, whether those signals survive resizing, how they are explained to users, and how outside surfaces such as Search and Chrome might read them. Content platforms need to revisit whether their upload optimization path casually removes metadata that future trust systems may need.
The next standard to watch
Three things are worth watching over the next few months.
The first is how quickly OpenAI's verification tool expands beyond OpenAI-generated media. A public tool that only handles one generator is useful, but limited. A general user-facing verification entry point becomes more valuable when it can handle multiple generators, watermark types, and C2PA issuers.
The second is how Search and Chrome phrase uncertainty. Showing "AI-generated" is not only an accuracy problem. It is a UX problem. If the warning is too strong, it may create false certainty. If it is too weak, users may ignore it. Provenance UX resembles security-warning UX: the explanation matters almost as much as the detection.
The third is platform preservation policy. The real effect depends on whether C2PA survives as images move, which transformations SynthID detection can tolerate, and how CDNs, editing tools, browsers, operating systems, cameras, and newsroom CMSes handle provenance information. Generator announcements alone cannot solve that chain.
The exaggerated version of this story is "AI image detection is solved." The more accurate version is that AI image trust has a new baseline. OpenAI, Google, and Kakao are not creating a perfect judge of authenticity. They are starting to define the minimum evidence AI-generated media should carry, and the basic surfaces that should be able to read it. In a web where AI-generated images appear everywhere, that baseline matters. Trust is not a feature the model creates by itself. It is an operating system that spans generation, distribution, search, verification, and preservation.