agentmemory 0.9.21 turns coding-agent memory into shared infrastructure
agentmemory points at a new layer for coding agents: shared local memory across Claude Code, Codex, Cursor, OpenCode, and other tools.

- What happened:
agentmemoryadded an OpenCode plugin and 22 auto-capture hooks inv0.9.21on May 19.- GitHub API data checked for the Korean report showed the repository last pushed on May 22, with 16.7k stars and an Apache-2.0 license.
- Why it matters: Coding-agent memory is moving beyond static files such as
CLAUDE.mdtoward a shared local runtime. - Key number: In the public coding-agent-life benchmark, hybrid retrieval reached a 100% top-5 hit rate across 15 queries, with
P@5of 0.578.- The grep baseline had similar recall but lower precision, which matters because noisy memory can mislead an agent.
- Watch: Persistent memory can improve continuity, but it also creates new governance questions around stale decisions, secrets, and cross-agent access.
As coding agents become real development tools, one of the most persistent bottlenecks is not just whether the model can write code. It is that every new session begins with amnesia. Yesterday's project structure has to be explained again. A failed approach from the last run gets tried again. Team rules about tests, deployment, runtime constraints, or review style have to be copied into the prompt one more time. The more responsibility coding agents take on, the more expensive that discontinuity becomes.
agentmemory is an open-source project aimed directly at that gap. At the surface level, it is persistent memory for AI coding agents. The more interesting part is the shape of the system. The README describes a shared local memory server that can be used by Claude Code, Codex CLI, Cursor, Gemini CLI, OpenCode, Cline, Goose, Aider, and other tools through MCP, hooks, or REST. In other words, the session trail left by one agent can become searchable context for another.
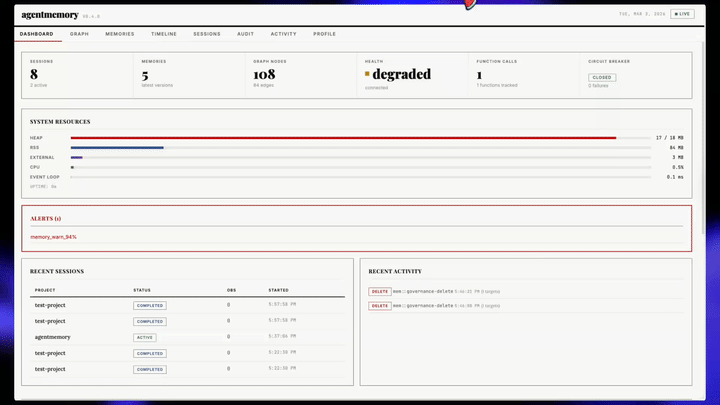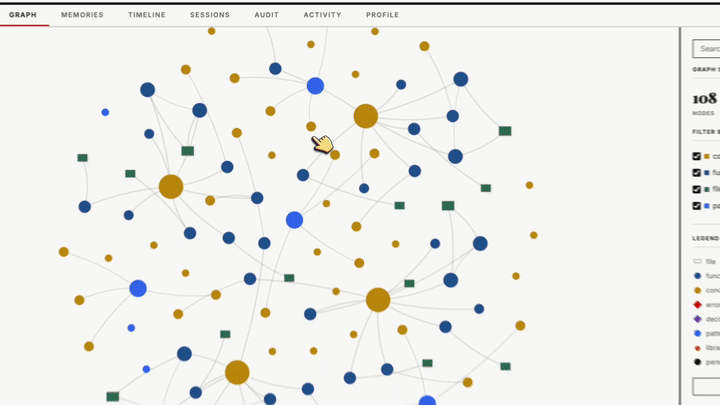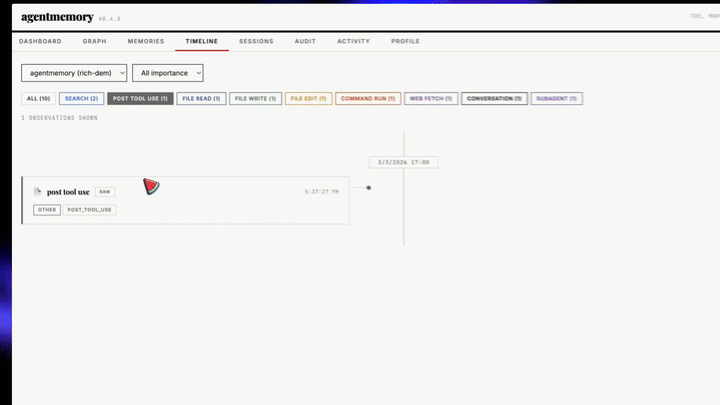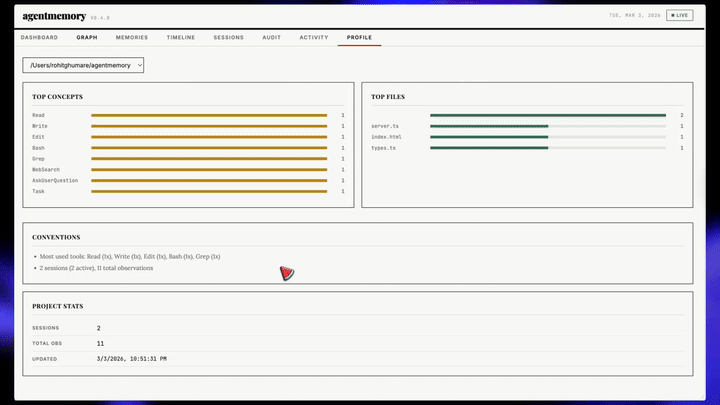
The news hook is the v0.9.21 changelog, published on May 19, 2026. That release added an OpenCode plugin and 22 auto-capture hooks across session lifecycle, messages, tool lifecycle, permissions, and task tracking. It also fixed practical problems around MCP memory_recall parameter forwarding, CJK IME search input in the viewer, large-session chunking, and background index rebuilds for larger corpora. Those are not headline-grabbing features. They are the kind of rough edges that appear when "agent memory" starts becoming a product surface instead of a demo.
Why session memory became a product problem again
In early coding assistants, memory was not the main issue. If the task was to rewrite a function or patch one file, the prompt usually had enough context. When the assistant got something wrong, a human was still sitting beside it and could correct the next turn. There was not much long-running state to preserve.
That assumption no longer fits the current generation of coding agents. An agent may scan a repository, run tests, edit several files, open a branch, write a pull-request summary, and then resume hours later. The agent's ability to continue work depends on more than model intelligence. It depends on whether the system remembers which files were touched, which tests failed, what decisions were made, and which constraints the team already established.
The existing answer has mostly been file-based memory. Claude Code has project instructions and memory files. Cursor has rules and notes. Cline-style workflows have memory banks. These are useful because they are simple and reviewable. A human can open the file, inspect the policy, and edit it. But static files also go stale, fragment by tool, and do not automatically capture the small operational facts that emerge during a session. Someone still has to decide what is worth writing down.
agentmemory takes the opposite direction. Its README describes hooks that capture lifecycle events such as prompts, tool use, and stops, compress the resulting work trail into searchable memory, and inject relevant context when the next session starts. The important shift is from "notes a human curated" to "operational memory extracted from agent work." That memory can include what the agent attempted, which files it modified, which commands failed, and which decisions keep recurring.
v0.9.21 is less about OpenCode than hook parity
The headline feature in v0.9.21 is OpenCode support. The broader signal is that agentmemory is trying to normalize different agent lifecycle surfaces. Claude Code, Codex, and OpenCode all have sessions and tool calls, but they do not expose identical event names, stop semantics, plugin dispatch behavior, or task boundaries. The changelog even mentions a Codex Desktop issue where plugin-local hooks were not dispatched, with a workaround that mirrors hooks into global ~/.codex/hooks.json.
That detail is important. A memory layer cannot just call a model API and declare victory. It has to know when a session starts, when a user prompt arrives, what the tool payload contains before and after execution, and whether a stop event means the whole session ended or only one assistant turn completed. In v0.9.20, agentmemory reverted a change that treated Codex Stop hooks as session-end events because Codex can emit multiple Stop hooks before a conversation is really over. The memory system was closing the session too early.
This is exactly the kind of failure mode that shows the agent ecosystem has not yet settled into a stable operating-system API. Vendors are adding hooks, plugins, skills, rules, and MCP integrations quickly, but concepts such as "session," "pause," "task complete," and "tool failure" still differ across products. Persistent memory therefore becomes integration engineering, not just vector search. The quality of the memory depends on how accurately the system reads each agent's lifecycle.
The benchmark is small, but it asks the right question
agentmemory's public coding-agent-life-v1 scorecard is intentionally small. It uses 15 fictional Claude Code sessions, 15 hand-graded queries, and a Rust CLI project. The project documentation says the corpus is small for fast iteration and notes future hardening such as paraphrased queries and longer multi-session chains. That means the numbers should not be generalized into broad production performance claims.
Even so, the benchmark is useful because the questions look like real agent-memory questions. Where was the N+1 query fix? What shipped on April 8? What was the multi-session decision that came up in review? Those are not generic knowledge-retrieval prompts. They are the kinds of facts an agent needs if it is going to resume work without asking a human to reconstruct the past.
In the published scorecard, agentmemory-hybrid reached a 15/15 top-5 hit rate, R@5 of 0.967, P@5 of 0.578, and 14ms p50 latency. On the same corpus, the grep baseline had the same R@5 of 0.967 but only 0.267 P@5. That distinction matters. Grep can often find an answer somewhere. But if the top results are half noise, an agent may read the wrong context, build the wrong connection, and confidently continue down a bad path. For coding-agent memory, precision is not cosmetic. It changes the quality of the next action.
Memory is not just context-window compression
agentmemory's README also emphasizes token savings. It compares the cost of repeatedly injecting full context, using LLM summaries, and retrieving smaller memory snippets. The intuition is sound. A team cannot keep every past agent conversation in the context window. A chain of summaries can preserve old mistakes like sediment. Retrieval-based memory tries to bring back only the relevant fragments.
But the value of coding-agent memory is broader than token efficiency. First, it can reduce repeated failure. A memory such as "this project uses jose instead of jsonwebtoken because of runtime constraints" is not background trivia. It prevents a bad pull request. Second, memory preserves local team preferences. Test naming, migration policy, lint constraints, release checklists, and review habits are not things a model can infer from general training data. Third, memory creates accountability. If an agent-generated change later breaks something, the team wants to know which session, prompt, observation, or failed test led to that commit.
The changelog's session-to-commit linking points in that direction. agentmemory creates commit link records keyed by full SHA and supports lookup from session to commit and from commit back to session. That is closer to an audit log than to a note-taking app. Once agents write code that matters, the memory layer becomes a forensic surface: what did the agent see, what did it believe, and how did that become a diff?
Local-first design is a strong default, not a complete policy
agentmemory emphasizes local execution and no external database by default. The server runs locally, the viewer shows memory builds on a separate port, and the storage stack is based around SQLite and iii-engine. The README also describes LLM-backed compression and summarization as configurable rather than an unavoidable external API call. For coding-agent logs, that local-first posture is sensible. Session data may include source code, file paths, internal architecture, command output, and context near secrets.
Local-first, however, does not automatically mean safe. Once one memory server is shared by several agents, permission boundaries appear. Should Cursor be able to read memory captured from Claude Code? Should personal project memory and company repository memory live in the same store? If remote deployment is enabled, what authentication and audit guarantees exist? The README discusses governance delete, audit, and secret-related controls, but the actual safety posture depends on how teams configure and operate the system.
There is also a more subtle trap: more memory is not always better. Old architectural decisions, temporary workarounds, one-off experiments, and wrong intermediate conclusions can keep resurfacing after they are no longer valid. That is why decay, auto-forget, and governance are not optional polish. Persistent memory quality includes the ability to forget, correct, and scope information, not merely store more of it.
The competitive line sits between memory API and agent harness
agentmemory's competitive position is not cleanly one category. On one side are general memory layers such as mem0, Letta/MemGPT, and Khoj, which approach memory as an API or runtime capability for agents. On the other side are built-in memory features inside Claude Code, Cursor, Cline, Codex, and related coding-agent products. agentmemory sits between those worlds. It looks like a general memory engine, but its practical value comes from deep hooks into coding-agent lifecycle events.
That position is attractive because it offers tool independence. A team using Claude Code, Cursor, and Codex on the same repository could maintain some continuity through a shared memory server. If one agent leaves useful traces, another agent can retrieve them through MCP or REST. That is the core promise.
The same position also creates risk. Every agent vendor is moving fast. If tool providers build their own cloud memory, change hook semantics, or standardize different MCP surfaces, an external memory runtime has to keep chasing adapters. This is why the changelog details are more revealing than the marketing numbers. They show the ongoing integration cost of trying to be the memory layer across several agent products.
For engineering teams, the immediate question is less "should we adopt agentmemory today?" and more "where does our agent memory live, and who governs it?" Some teams may be fine with static repository instructions. Some may need to prohibit automatic capture for security reasons. Others, especially teams running several agents across the same codebase, long onboarding context, and repeated operational work, now have a reason to evaluate a dedicated memory runtime.
Four checks before using persistent agent memory
The first check is capture scope. Teams need to know which prompts, tool payloads, command outputs, file paths, and logs are stored. Secret masking, .env handling, production logs, and customer data all matter. Automatic capture is useful because it is automatic. It is risky for the same reason.
The second check is retrieval quality. A memory system should not be evaluated only on whether it can find something. It should be evaluated on whether the right memory appears with low noise for the task at hand. The public benchmark's P@5, R@5, and hit-rate framing is a good starting point, but teams should test against their own agent logs and recurring tasks.
The third check is forgetting and governance. Who can delete a wrong memory? How does a stale decision decay? Does deletion leave an audit trail? Can sensitive captures be purged? Agent memory is part of the work state, not a sacred knowledge base, so correction has to be built in.
The fourth check is cross-agent boundaries. A shared memory server needs namespaces and permissions when it spans multiple agents and projects. The risk profile is different for one developer using it locally and for a team treating it as shared infrastructure. "It runs locally" is not enough once team sharing or remote access enters the picture.
Shared memory makes agents feel more like teammates
agentmemory 0.9.21 is not a giant platform launch. It is a fast-moving 0.x open-source project with a small benchmark and integration surfaces that are still shifting. The right reading is not that agentmemory has already become the standard. The more useful reading is that coding-agent products are all converging on the same need: memory is becoming infrastructure.
That infrastructure is not just vector search. It needs reliable hooks, session boundaries, commit links, audit logs, forget policies, local-first storage, MCP surfaces, a viewer, and benchmarks. agentmemory is interesting because those pieces are already colliding in one repository. The big README claims are worth checking carefully, but the small changelog fixes may be even more persuasive. They reveal the practical edges of operating a real memory system for coding agents.
The next stage of coding-agent competition will not be decided only by model scores or IDE polish. It will also depend on who remembers the right context, who safely forgets outdated context, and who can carry the same work memory across multiple agent surfaces without leaking too much or preserving the wrong thing. agentmemory 0.9.21 is a small but useful snapshot of that shift. As coding agents move from disposable assistants toward long-running workers, memory stops being a convenience feature and becomes part of the operating layer.