Nemotron Diffusion tests the one-token-at-a-time bottleneck
NVIDIA released tri-mode diffusion LLMs that switch between AR, diffusion, and self-speculation generation in one checkpoint.

- What happened: NVIDIA published the
Nemotron-Labs-Diffusionmodel family on Hugging Face.- It is a tri-mode LLM family that can switch between autoregressive, diffusion, and self-speculation generation from the same checkpoint.
- Key numbers: For the 8B model, NVIDIA claims
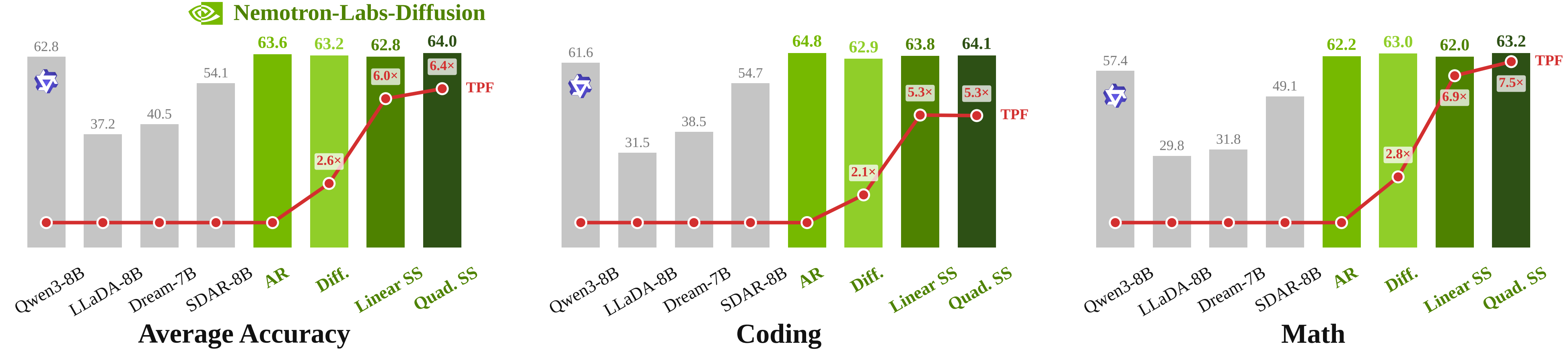
2.6xtokens per forward in diffusion mode and up to6.4xin self-speculation. - Why builders should care: This is less about another benchmark race and more about changing serving latency and GPU utilization.
- Watch: SGLang integration and real inference-provider availability are still in progress.
Most developers using LLMs run into the same bottleneck. As models get more capable, answers get longer. As agents take more steps, the time spent "thinking" stretches out. Users see tokens streaming onto the screen, but the serving system pays for a model pass again and again, one token at a time. NVIDIA's Nemotron-Labs-Diffusion, published on Hugging Face on May 23, 2026, goes straight at that assumption. The question is simple: does an LLM always have to write left to right, one token after another?
NVIDIA's answer is close to "not necessarily." Nemotron-Labs-Diffusion is not a declaration that autoregressive generation is over. It keeps conventional AR decoding, while adding diffusion-style parallel generation and self-speculation in the same model family. That is why the important news is not merely that another 8B or 14B model appeared. The important part is that NVIDIA is proposing one checkpoint with three serving modes as the operational unit.

The release includes 3B, 8B, and 14B text models, plus an 8B vision-language model. The text models use the NVIDIA Nemotron Open Model License, while the VLM uses the NVIDIA Source Code License. NVIDIA's Hugging Face model collection includes base and instruction-tuned chat variants, and the training recipes are available in the Megatron-Bridge repository. This is therefore not just a paper idea. It is at least a public model-and-code release that developers can download and test.
The reason this matters becomes clear when you look at ordinary LLM serving. A typical autoregressive LLM predicts the next token, appends that token to the context, and then predicts the next one. The approach is stable, well understood, and deeply aligned with today's decoder-only transformer ecosystem. The problem is latency. To produce one long response, the model moves sequentially, while the GPU often spends more time reading weights from memory than doing dense compute. The bottleneck is especially visible with small batch sizes or interactive single-user requests. Coding agents, document agents, and long tool-using chat flows all hit this wall.
Nemotron-Labs-Diffusion tries to route around that wall with a diffusion language model. The user experience is not identical to image diffusion, but the idea is related. Instead of committing to one token and moving on, the model drafts multiple tokens as a block and refines that block over several steps. This lets the model generate and revise candidate tokens in parallel rather than treating every token as a fully sequential dependency. NVIDIA argues that this better matches modern GPU compute and lets operators adjust inference budget by changing the number of refinement steps.
The more interesting piece is self-speculation. Classic speculative decoding often pairs a small draft model with a larger verifier model. The small model proposes tokens quickly, and the larger model accepts or rejects them. That can work well, but two-model deployment increases operational complexity, cache handling, memory planning, and observability work. Nemotron-Labs-Diffusion's self-speculation keeps the draft and verify paths inside the same model: diffusion drafts candidate tokens, and autoregressive decoding verifies them. In NVIDIA's framing, it combines the speed potential of diffusion-style drafting with the reliability of AR verification.
| Mode | How it works | Operational meaning |
|---|---|---|
| Autoregressive | Generates one token at a time from left to right. | The compatibility baseline for existing LLM serving. |
| Diffusion | Creates block-level token drafts in parallel and refines them iteratively. | Can improve GPU utilization for low concurrency or long outputs. |
| Self-speculation | Uses the same model for diffusion drafting and AR verification. | Targets speed without operating a separate draft model. |
NVIDIA's performance claims point in that direction. According to the announcement, Nemotron-Labs-Diffusion 8B is 1.2 percentage points higher than Qwen3 8B on average accuracy, while diffusion mode delivers 2.6 times more tokens per forward than the AR model. Self-speculation rises to 6 times in the linear setting and 6.4 times in the quadratic setting. It is important to separate this from raw tokens per second. Tokens per forward is a hardware-agnostic decoding-efficiency measure, not a production SLA. Still, the message for builders is clear. If model quality remains in the same band, the next competition is not only parameter count. It is how much less sequential token generation can become.
The model card makes even stronger runtime claims. The 14B model card says the 8B model reaches 112 tok/s on DGX Spark at concurrency 1, compared with 41.8 tok/s for AR generation, or 2.7x faster. On GB200, it reports 850 tok/s, ahead of AR at 253 tok/s and Eagle3 at 360 tok/s. With a custom CUDA kernel, NVIDIA claims 1015 tok/s, roughly 4x the AR baseline. These numbers are tied to specific hardware, precision, decoding settings, and benchmark conditions. They should not be copied into a product plan as guaranteed latency. But for agent services where single-user latency matters, they are significant enough to investigate.
This is where the release connects to agent infrastructure. Agents are more sensitive to decoding latency than ordinary chatbots. A user does not just ask one question and receive one answer. A planner writes a plan, creates a tool call, reads the observation, revises the next step, and continues. Each output may be short, but the whole loop contains many sequentially generated tokens. When model-call count and token wait time multiply, the user experiences it as an agent that appears to pause or stall. If diffusion drafting and self-speculation work reliably, agent latency becomes not just a model-selection problem but a decoding-policy problem.
That is also where the release should not be overread. Diffusion language models are not the default deployment path for mainstream LLMs yet. NVIDIA itself points to an SGLang integration that is still in progress. The message at launch is closer to "runtimes such as SGLang are beginning to support this mode" than "every inference provider can turn this on today." Diffusion mode will not be better for every task either. Math proofs, long code edits, strict JSON generation, and workflows where intermediate token order matters may still need the conservative AR path. That is exactly why self-speculation is interesting. It does not force an entirely different generation style. It drafts in parallel and then keeps a familiar causal verification path.
The training path is also designed to be practical. NVIDIA's announcement refers to the Efficient-DLM research direction, where pretrained AR models are continued and attention is changed toward block-wise behavior to add diffusion capabilities. Nemotron-Labs-Diffusion was trained with a joint AR and diffusion objective, using 1.3T tokens from Nemotron pretraining datasets and 45B tokens of post-training data. The strategy is not to throw away an AR model's learned knowledge and build a diffusion LM from scratch. It is to preserve the AR model's capability while adding a parallel drafting behavior.
Community response is still early. Hugging Face collection activity is moving, and conversions and forks are already appearing, but this has not yet become the kind of broad argument that follows the largest frontier-model launches. A Reddit thread in r/LovingOpenSourceAI framed parallel token generation as potentially useful for code scaffolding, agent planning, and latency-sensitive workloads. Skeptical comments raised the right question: even if fast chunk generation works, does coherence hold when the task requires step-by-step reasoning? That balance matters. Diffusion LMs are not a magical quality upgrade. They are a serving-structure experiment aimed at latency and cost.
The competitive map mixes model research and runtime research. Qwen3, LLaDA, Dream, and SDAR are useful reference points for model quality and diffusion-versus-AR design. Eagle3 and related speculative decoding systems are direct comparisons for self-speculation. SGLang, vLLM, TensorRT-LLM, and TGI will determine whether the idea becomes a serviceable production path. Hugging Face and MLX-style community conversions will shape the speed of local experimentation. So the larger event is not simply "NVIDIA beat Qwen." It is that the LLM serving stack is starting to treat generation mode as a tunable setting.
The practical next step for development teams is clear. First, treat Nemotron-Labs-Diffusion as a latency experiment, not a default production replacement. Second, evaluate quality by workload rather than one aggregate benchmark. Code generation, summarization, short chat, long agent plans, and structured output have different failure modes. Third, measure end-to-end task latency, not only tokens per second. For agents, the full tool loop matters more than a single fast response. Fourth, verify runtime stability. SGLang support has to land, and either providers or internal serving stacks need to handle the attention-pattern switching and cache behavior reliably before the cost savings become real.
Internal platform teams may find it useful to treat this as a routing-policy issue rather than a model-swap issue. A single service may contain many output types. A short user reply, a fast draft, an editable code scaffold, a long analytical response, and a JSON schema call do not necessarily need the same decoding policy. AR mode can remain the conservative fallback. Diffusion mode can be tested for rapid drafts and editable outputs. Self-speculation can be tried for interactive generation where the team does not want to give up too much quality. For that to work, model APIs may need to expose lower-level operational controls such as generation mode, block length, confidence threshold, and verification settings. The abstraction of an LLM platform moves one layer closer to inference.
There is a cost angle as well. Until now, teams have often attacked latency by routing to a smaller model, adding a separate draft model for speculative decoding, or buying more expensive GPUs. Each option has tradeoffs. A smaller model can move the quality boundary. A separate draft model adds deployment and monitoring surfaces. More hardware raises the bill directly. Nemotron-Labs-Diffusion's claim is that one model can move across three modes and make those tradeoffs more adjustable. It will not erase cost problems. More diffusion refinement steps add compute, and failed verification reduces the expected speedup. Still, weakening the assumption that "fast model" and "accurate model" must always be separate systems is important.
Security and verification are worth including in the story. When agents generate tool calls or edit code, speed is not the only concern. Reproducibility and auditability matter. Self-speculation puts the draft and verification boundary inside one model. That can simplify operations, but it also raises observability questions. Teams may need to know which candidates were rejected, how a confidence threshold affected output quality, and which decoding mode was used for a specific tool call. Future agent observability may track not only prompts, responses, and tools, but also decoding mode and accepted-token paths. Once fast decoding becomes a platform feature, "which model did we use?" may not be enough to explain an incident.
The hidden meaning of this release is not "a bigger model." It is "a different decoder." Over the last two years, LLM competition has usually been described through parameters, data, context length, and reasoning benchmarks. As agents and realtime applications grow, however, intelligence is not the only bottleneck. The operational question is how to draw more useful tokens from the same GPU, with lower latency and without unacceptable quality loss. Nemotron-Labs-Diffusion suggests that this competition will happen between model architecture and inference runtime, not in either layer alone.
So the news does not end with "NVIDIA released a new LLM." The assumption that language models must generate one token at a time is beginning to move. The release is still experimental, and production systems have real validation work to do. But when an agent feels slow, the answer cannot always be a larger model. The next bottleneck is likely to be solved by some combination of decoding mode, runtime, cache behavior, and verification policy. Nemotron-Labs-Diffusion makes that direction unusually visible.