DiffusionGemma makes 256-token parallel generation a local LLM speed test
Google released DiffusionGemma as an Apache 2.0 open model, pairing a 256-token diffusion canvas with vLLM support and an 18GB VRAM deployment target.

- What happened: Google released DiffusionGemma on June 10, 2026 as an Apache 2.0 open model for text diffusion.
- It is a Gemma 4-based 26B MoE model that activates 3.8B parameters at inference time.
- How it works: instead of writing one token at a time, the model refines a
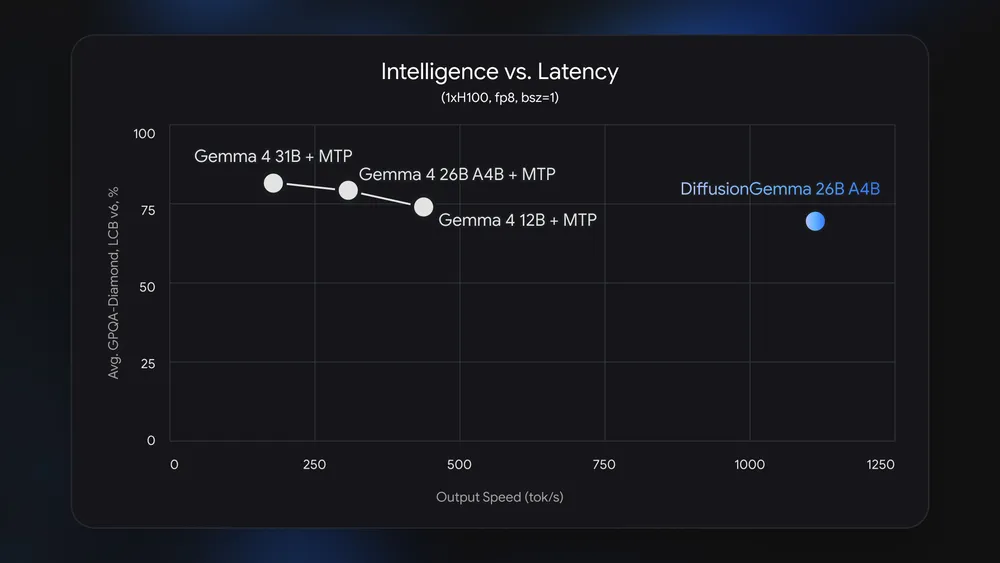
256-token canvasin parallel. - Speed claim: Google cites 1000+ tokens/s on H100 and 700+ tokens/s on RTX 5090.
- The advantage is aimed at low-to-medium batch, dedicated-GPU, local interactive workflows rather than every cloud serving case.
- Watch: Google still recommends standard Gemma 4 when maximum output quality is the main requirement.
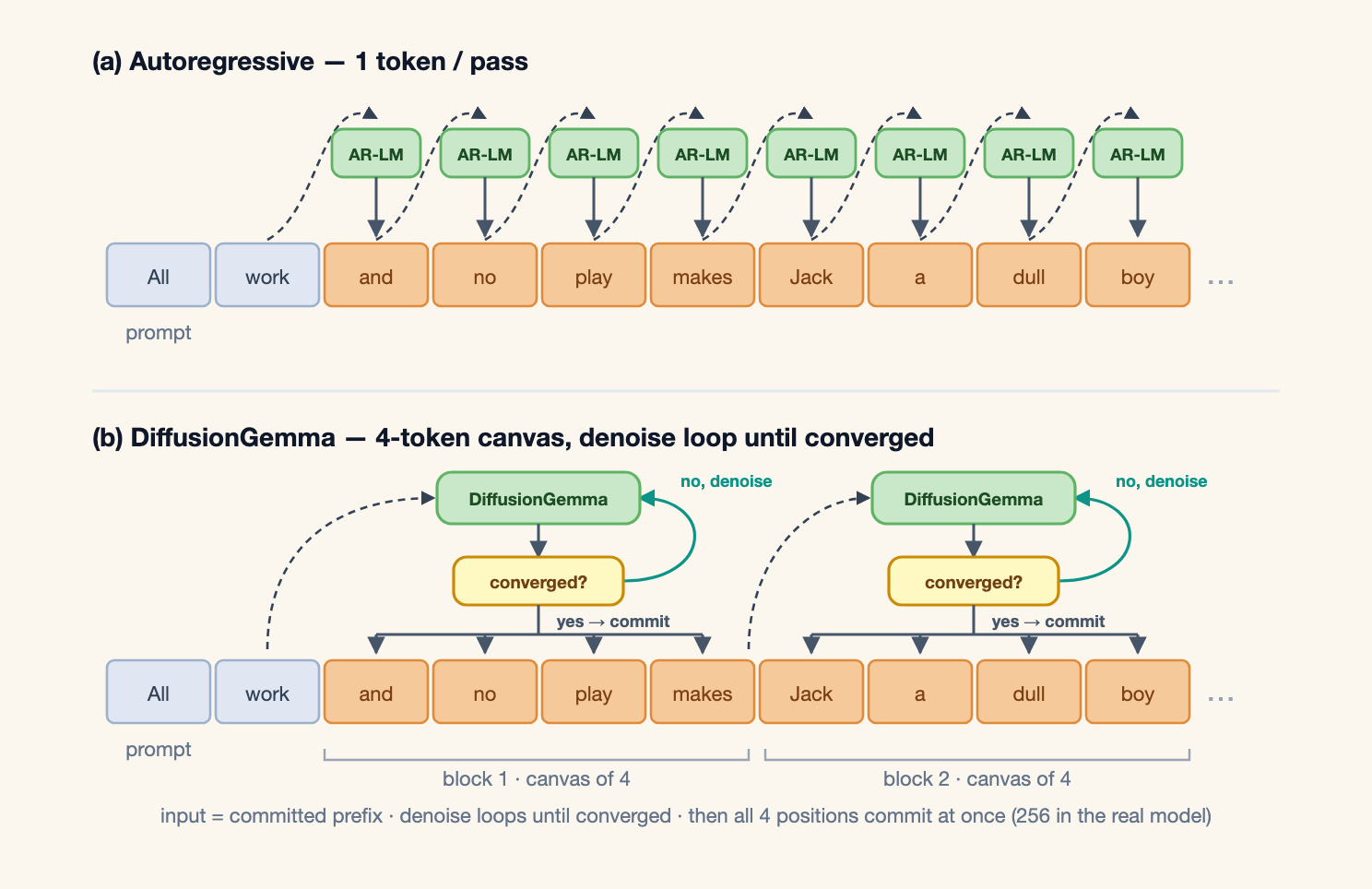
Google released DiffusionGemma on June 10, 2026. The launch post calls it an experimental open model for exploring text diffusion. The license is Apache 2.0. The architecture is a 26B Mixture of Experts model built on a Gemma 4 backbone, with 3.8B active parameters during inference. The more consequential detail is the decoding path. DiffusionGemma does not generate text left to right, one token at a time. It opens a 256-token canvas and repeatedly refines many positions at once.
That makes this announcement less about a new model name and more about a serving bottleneck. Google says DiffusionGemma can deliver up to 4x faster token output on dedicated GPUs. The headline numbers are 1000+ tokens/s on NVIDIA H100 and 700+ tokens/s on GeForce RTX 5090. Google also says a quantized deployment fits within 18GB of VRAM. For a developer running local completions, inline edits, code infilling, or short agent responses on an RTX 4090 or 5090-class machine, the pitch is concrete: use more available compute to avoid the memory-bandwidth drag of autoregressive generation.
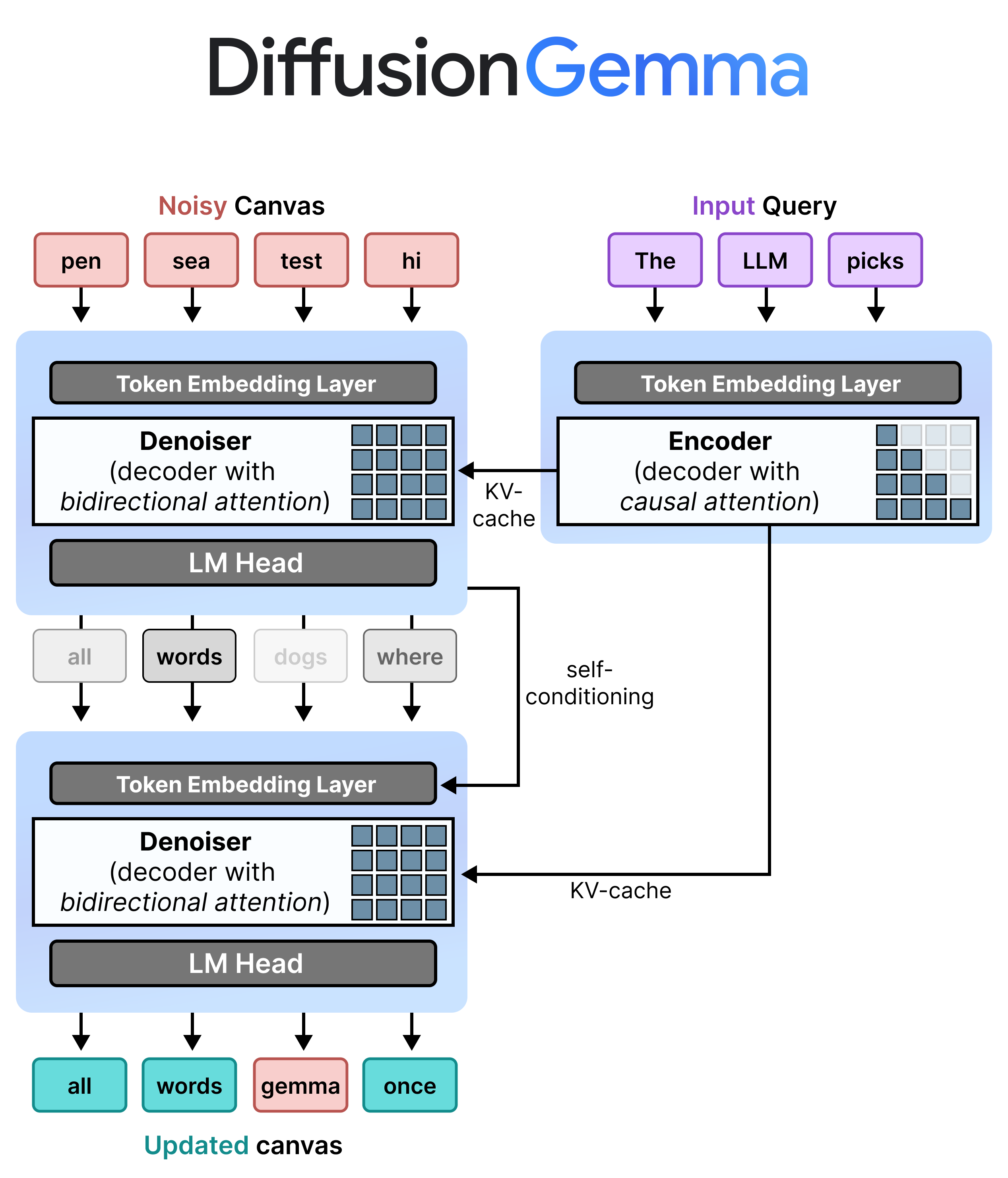
Calling DiffusionGemma simply "faster" misses the mechanism. A standard autoregressive model predicts the next token, appends that token to context, then predicts the next token again. Large cloud serving systems can hide part of that sequential shape by batching many requests and keeping the GPU busy. A single local user often cannot. Google frames this as a memory-bandwidth problem. DiffusionGemma changes the unit of work from one next-token step to a 256-token block, giving tensor cores a larger parallel workload.
Google's developer guide describes the process in more operational terms. The model starts with random placeholder tokens in the canvas. It runs denoising passes that predict candidate tokens at each position. High-confidence tokens are fixed. Lower-confidence positions are re-randomized and evaluated again in the next step. After the block converges, the model commits the 256-token block, writes it into the KV cache, and starts the next block.
This is not fully non-sequential generation. Within a block, DiffusionGemma uses bidirectional attention so every position in the canvas can see every other position. Across blocks, the output still moves left to right: a committed block conditions the next canvas. Google describes this as block autoregressive denoising. The compromise matters because it brings diffusion-style parallel refinement into a stack that still resembles existing LLM serving enough to support practical deployment.
 .
.
The vLLM implementation post, published the same day by the vLLM and Google DeepMind teams, shows why the compromise is technically important. vLLM calls DiffusionGemma the first diffusion LLM it natively supports. Diffusion language models do not fit the standard autoregressive serving path cleanly. They need bidirectional attention during denoising, iterative refinement, block-based generation, and custom sampling state. vLLM added a ModelState abstraction to carry per-request state such as the canvas, denoising phase, commit phase, and self-conditioning probability.
The hardest serving detail is that the attention mode can differ by request. Prefill and commit use causal attention. The denoising canvas uses bidirectional attention. In one batch, vLLM may have one request reading a prompt, another refining a canvas, and another committing a block. The team implemented dynamic per-sequence causal attention so each request can carry its own causality setting. Triton Attention and FlashAttention 4 paths were updated to accept per-request causality tensors.
vLLM also connects the design to speculative decoding. The canvas can be interpreted as a large draft token set produced at each step, then accepted or rejected through refinement. That lets vLLM reuse mature accounting from its speculative decoding path and avoid rewriting the scheduler and model runner around a completely separate primitive. During a denoise step, vLLM reports num_sampled = 0 so the KV cache position does not advance. During commit, it emits the clean argmax canvas as 256 tokens. That is close to a production blueprint for putting a diffusion model into an LLM serving framework.
The vLLM benchmark numbers are more aggressive than Google's launch-page framing. The vLLM team reports that FP8 DiffusionGemma reached 1,288 generation tokens/s on H200, about 6x a standard autoregressive baseline and about 3x a multi-token prediction baseline. On H100, it reports 1,008 tokens/s, about 5x the autoregressive baseline and about 2.6x the MTP baseline. Those results are for a batch-size-1 interactive setting. They should not be read as a direct cost claim for a high-QPS cloud deployment that already keeps GPUs full through batching.
Google is explicit about that boundary. The launch post says the speedup is targeted at local and low-concurrency inference. In high-QPS cloud serving, an autoregressive model can often saturate compute through large batches, reducing the advantage of diffusion and potentially raising serving cost. Google also notes that unified-memory systems such as Apple Silicon Macs may not see the same acceleration when inference remains memory-bandwidth-bound. Dedicated GPUs with spare compute are the more favorable target.
The quality trade-off is also part of the release. Google says DiffusionGemma prioritizes speed and parallel layout generation, and that overall output quality is lower than standard Gemma 4. For applications that need maximum quality, Google recommends deploying standard Gemma 4. That means DiffusionGemma is not a higher-tier Gemma model. It is a targeted experimental architecture for workflows where interactive latency matters more than peak reasoning or writing quality.
The most practical developer use cases are narrow but useful. Code infilling is one. A function body, Markdown table, JSON block, or HTML/CSS snippet often has constraints on both sides of the blank region, making bidirectional refinement more natural than strict left-to-right generation. Inline editing is another. A user may already have a paragraph or code selection and want a small rewrite that respects surrounding context. Constrained text structures are a third. Google's developer guide uses Sudoku fine-tuning to illustrate why bidirectional context propagation can help when row, column, and grid constraints interact.
The Sudoku example is not just a toy. Google says base DiffusionGemma had almost 0% success when it was not trained for Sudoku. After a simple SFT recipe based on Hackable Diffusion, correctness rose to 80% while inference step count also fell. The lesson for product teams is specific: diffusion LLMs may become more persuasive when fine-tuned for fast refinement in structured tasks, rather than used as generic chat models.
NVIDIA published its own optimization post on the same day. NVIDIA says DiffusionGemma generates text in parallel and is optimized for RTX PRO platforms, DGX Spark systems, and GeForce RTX GPUs. Google's announcement also names a hardware range from consumer RTX 4090 and 5090 systems to Hopper, Blackwell, DGX Spark, and DGX Station. The open-model message is therefore paired with a hardware message: local AI PCs and desk-side AI workstations are becoming a testbed for alternative decoding paths.
The deployment surface is broad for a first release. Google names Hugging Face weights, vLLM, Hugging Face Transformers, SGLang, MLX, Google Cloud Model Garden, and NVIDIA NIM. Official llama.cpp support is only described as arriving soon. For teams trying it immediately, vLLM's OpenAI-compatible local server is the best documented path. The developer guide shows vllm serve google/diffusiongemma-26B-A4B-it with --diffusion-config '{"canvas_length": 256}' and entropy-bound sampling settings.
Community reaction has focused less on the top-line speed number and more on the conditions around it. GeekNews listed the launch as "DiffusionGemma: 4x faster text generation." In r/LocalLLaMA discussions, users asked how the numbers compare with other high-throughput claims such as Gemini Flash, which hardware and batch settings were used, and whether Unsloth or GGUF paths would make the model easy to run locally. That skepticism is useful because DiffusionGemma's value depends on workload shape and deployment conditions, not a universal tokens-per-second headline.
DiffusionGemma should also not be framed as an immediate replacement for multi-token prediction or speculative decoding. MTP accelerates the autoregressive path by predicting multiple next tokens or using a draft model. DiffusionGemma treats the entire 256-token canvas as an iterative denoising target. vLLM's benchmark shows diffusion beating its MTP baseline under FP8/H100/H200 and batch-size-1 conditions. A production router would likely split work instead of treating one decoder as universal: DiffusionGemma for short interactive completions, Gemma 4 or frontier models for quality-sensitive reasoning, and standard autoregressive serving for long high-batch workloads.
For AI coding tools, the prompt architecture also changes. Traditional completion is optimized around building context before the next token. DiffusionGemma is more interesting when the blank sits in the middle or the output must satisfy constraints on both sides. An editor extension could place nearby code, a type error, a failing test, and the desired patch shape into the canvas, then rapidly refine candidates. That is different from asking a chat model to plan a repository-wide refactor. For multi-file reasoning, long tool use, or high-stakes design decisions, output quality and agent reliability still matter more than raw token throughput.
Operating teams should measure four things before treating this as a deployment win. First, latency should be measured as time to first useful edit, not just tokens per second. A model can produce 1000 tokens/s and still fail to improve the user's perceived wait if denoising and commit phases do not align with the UI. Second, quality regression has to be measured by task: factuality, instruction following, and code correctness may fall differently across workloads. Third, hardware utilization should be checked on the actual target machines, especially if they are Apple Silicon or CPU-offload systems. Fourth, cost per accepted edit matters more than cost per generated token if users discard more candidates.
The news value of DiffusionGemma is not that text diffusion has suddenly replaced every LLM. The narrower change is more useful. Google and vLLM packaged a discrete diffusion language model with open weights, an Apache 2.0 license, native vLLM serving, NVIDIA optimization, and Hugging Face distribution. A research idea has become something a local developer workflow can test without rebuilding the entire serving stack. Even if the model itself remains experimental, it pushes the inference discussion below context length and reasoning scores into decoding path and hardware utilization.
The next signals are straightforward. Watch how quickly llama.cpp and consumer-GPU quantization mature. Watch whether inline editing and code-infilling benchmarks show real acceptance-rate gains against autoregressive models, not just throughput gains. Watch whether vLLM's ModelState abstraction makes it easier to support the next diffusion or hybrid language model. DiffusionGemma may never become the production default, but 256-token parallel generation is now a practical benchmark for local AI latency experiments.