A 73% Agent Report Card Ends the Model-Only Benchmark Era
Open Agent Leaderboard evaluates full agent systems, not just standalone models, combining architecture, tools, cost, and failure behavior.

- What happened: IBM Research and Hugging Face released
Open Agent Leaderboardalongside theExgenticevaluation framework.- The May 18, 2026 announcement covers five agent architectures, five backbone models, and six benchmark environments.
- Why it matters: Agent evaluation is moving from standalone model scores to system-level measurement of
model + harness + tools + cost. - Key numbers: Agent architecture can shift results by up to 12 percentage points on the same model, while failed runs cost 20-54% more than successful ones.
- The early public leaderboard showed a top configuration near 73% success, but the live ranking can change as new runs are added.
- Watch: The comparison avoids benchmark-specific tuning, so it should not be read as a direct replacement for product-specific internal evals.
The AI agent market has been stuck on one familiar question: which model is stronger? Which one posts the better coding benchmark score? Which one survives the longest context? Which one climbs another reasoning leaderboard? Those questions still matter. But teams that operate real agent products quickly run into a more practical set of questions. Why does one agent finish the job while another agent, using the same model, gets lost in the tool list? Why does one configuration spend several times more money for a similar success rate? When an agent is failing, should it stop early, or should it keep trying?
That is the problem IBM Research and Hugging Face are trying to make measurable. On May 18, 2026, they announced Open Agent Leaderboard. The release also includes the open-source Exgentic evaluation framework and the General Agent Evaluation paper. The core claim is simple: if we are evaluating agents, we should not evaluate only the model. We need to evaluate the agent architecture, tool interface, benchmark adaptation, cost, and failure behavior around the model.
That shift matters because an agent is no longer a single model call. A coding agent reads a repository, edits files, runs tests, interprets logs, and tries again. A customer-support agent reads policy documents, checks order status, and decides whether a refund is allowed. A research agent browses the web, gathers evidence, and resolves conflicts between sources. In each case the model is the central component, but the deployed product is a larger system: planner, tool router, memory, retry policy, prompt scaffold, sandbox, logger, and evaluator.
Why model leaderboards are no longer enough
LLM leaderboards have been useful. Scores on MMLU, GPQA, SWE-Bench, HumanEval, MMMU, and related benchmarks gave both model builders and users a shared vocabulary. They made it easier to understand where a model stood in reasoning, coding, vision, math, or instruction following. For agents, though, that style of measurement hits a wall.
First, an agent does not answer a task in one step. It observes, calls tools, reads intermediate results, changes direction, and decides when to stop. The same model can behave very differently depending on how tool descriptions are presented, how intermediate observations are compressed, and how stopping rules are enforced. A standalone model benchmark mostly cannot see those differences.
Second, the cost structure changes. A normal chat completion can be approximated by counting input and output tokens. An agent may call the model repeatedly inside one task, browse, search, execute code, open files, and keep working after an initial mistake. The Hugging Face announcement says failed runs were 20-54% more expensive than successful runs in the experiments. Failure is not just a quality problem. It is also a billing problem.
Third, domain-specific optimization makes comparison messy. One team can tune a prompt and tool flow tightly for SWE-Bench. Another can optimize around customer-support policies. Those results can be useful for their domains, but they are not the same as evidence for a general-purpose agent. Open Agent Leaderboard is trying to measure performance across multiple environments without benchmark-specific tuning.
Six environments on one evaluation surface
The benchmark mix is deliberate. The launch combines SWE-Bench Verified, BrowseComp+, AppWorld, tau2-Bench Airline/Retail, and tau2-Bench Telecom. That means coding, web research, personal-app operation, airline and retail customer support, and telecom technical support all sit on the same evaluation surface. The point is not to claim that one number explains everything. The point is to make "general agent" claims harder to support with only one type of task.
The paper introduces a unified protocol to make this possible. Each benchmark has its own interface, assumptions, and scoring rules. Each agent also has its own way of receiving context and calling tools. Claude Code is comfortable with a CLI and filesystem loop. Smolagent is closer to a Python execution and tool abstraction model. ReAct-style systems revolve around text reasoning and tool-call loops. Exgentic creates a common shape between them using tasks, context, and actions, then connects each benchmark and agent through the same evaluation pipeline.
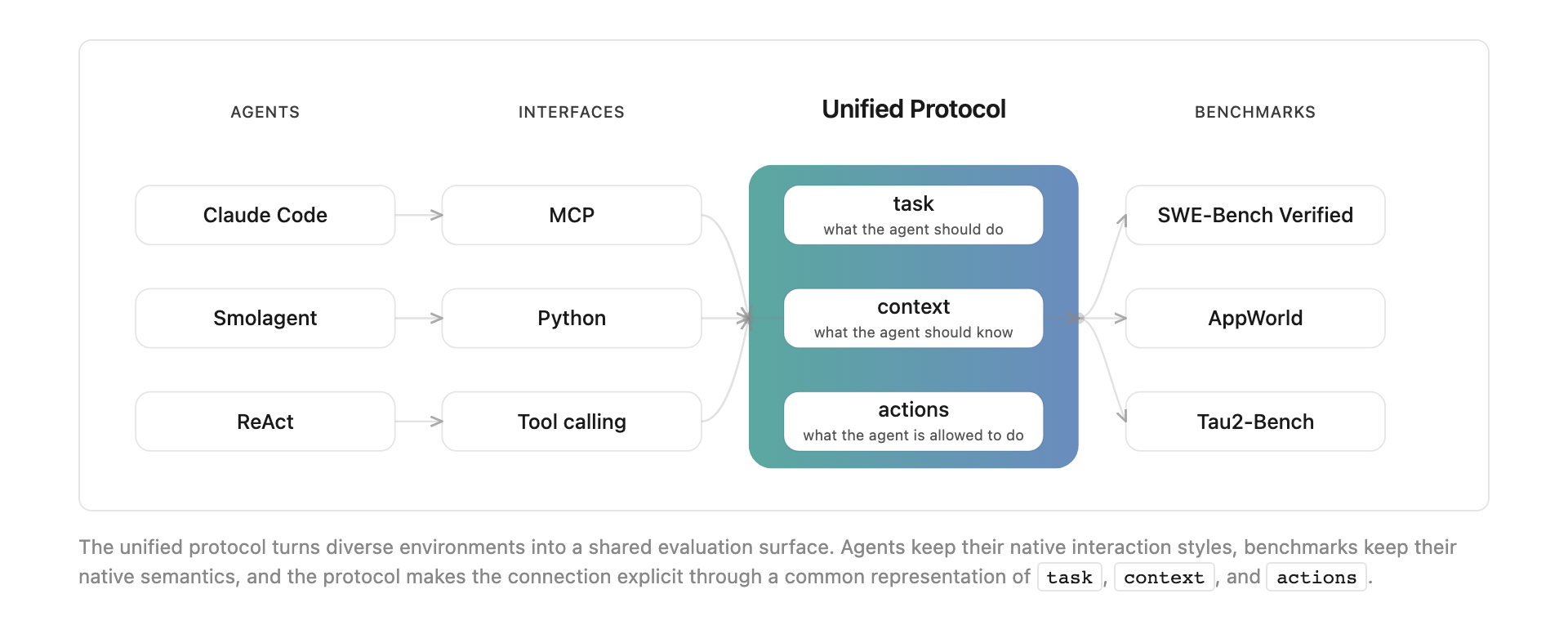
The important part is that unification does not mean flattening all benchmarks into the same toy problem. SWE-Bench Verified asks the agent to fix real GitHub issues. tau2-Bench asks an agent to follow business policies in customer-support conversations. If those are reduced to one generic "accuracy" number, the original meaning of each benchmark disappears. If they remain fully separate, it becomes hard to compare agent architectures across environments. Exgentic is an attempt to occupy that middle ground.
Same model, different agent, different result
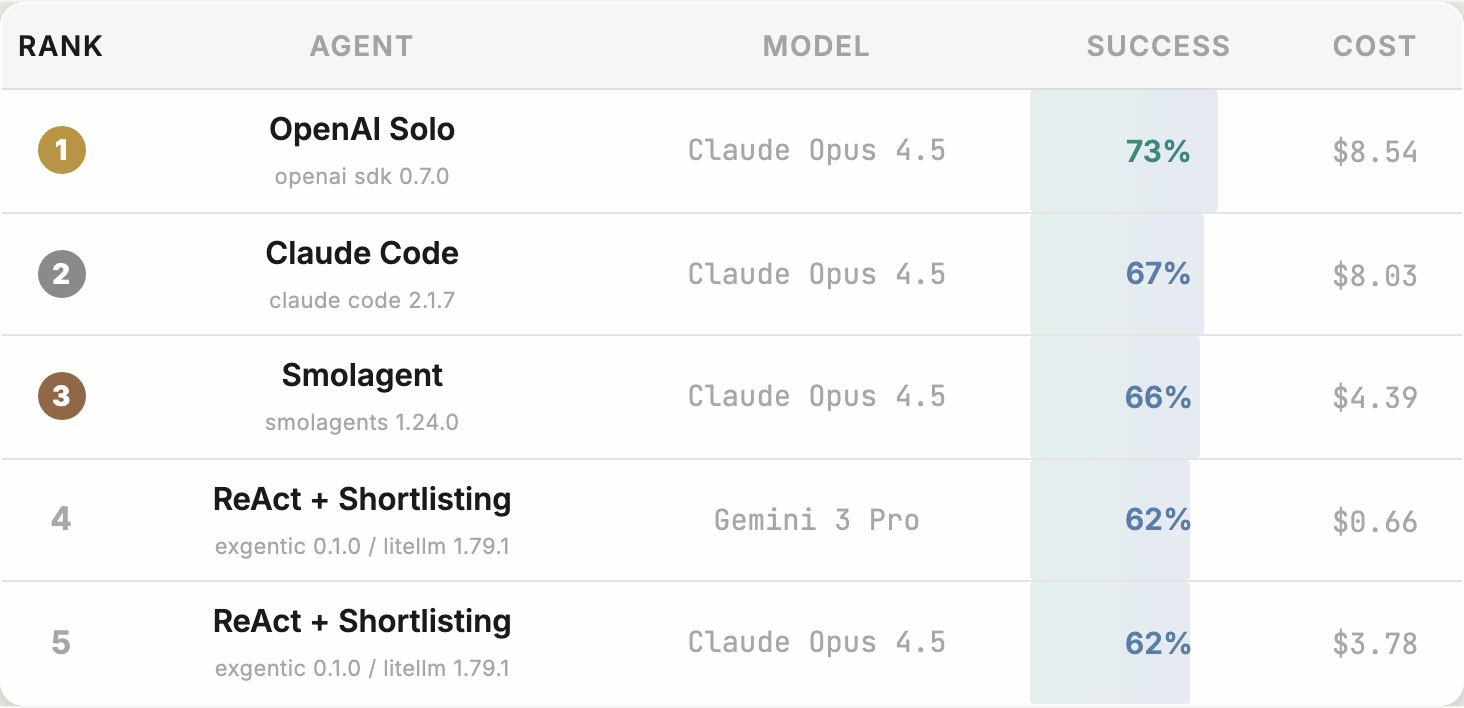
The most visible result is that top configurations can use the same underlying model while producing different success rates and costs. The Hugging Face post highlights that the top three used the same Claude Opus 4.5 backbone but different agent systems. The early public ranking showed OpenAI Solo plus Claude Opus 4.5 around 73% success, followed by Claude Code plus Claude Opus 4.5 and Smolagent plus Claude Opus 4.5. The exact numbers can move because the leaderboard is live, but the message is stable: choosing the model does not settle agent quality.
The paper reaches a similar conclusion. The researchers report that the choice of agent architecture can shift performance by up to 12 percentage points when the backbone model is held constant. At the same time, backbone model choice still explains a large share of the overall performance spread. Both statements are true. The model is not everything, and the model is still very important.
For development teams, that balance is useful. A weak model cannot be rescued indefinitely by a clever harness. But a strong model does not automatically produce a reliable agent product either. If the tool list is too broad, the agent may choose the wrong tool. If context compression drops key constraints, the agent may make a plausible but invalid move. If retry policy is loose, the system may spend more money moving deeper into a failed path. The thing to evaluate is not a model call. It is the execution loop.
Cost-success curves are now product strategy
Open Agent Leaderboard becomes more interesting because it puts cost on the same screen as success rate. A configuration that is two or three percentage points better is not always the better deployment choice. If its average task cost is several times higher, the product decision may point somewhere else. In high-volume areas such as support automation, code review, and research triage, the Pareto frontier between cost and success becomes a practical operating constraint.
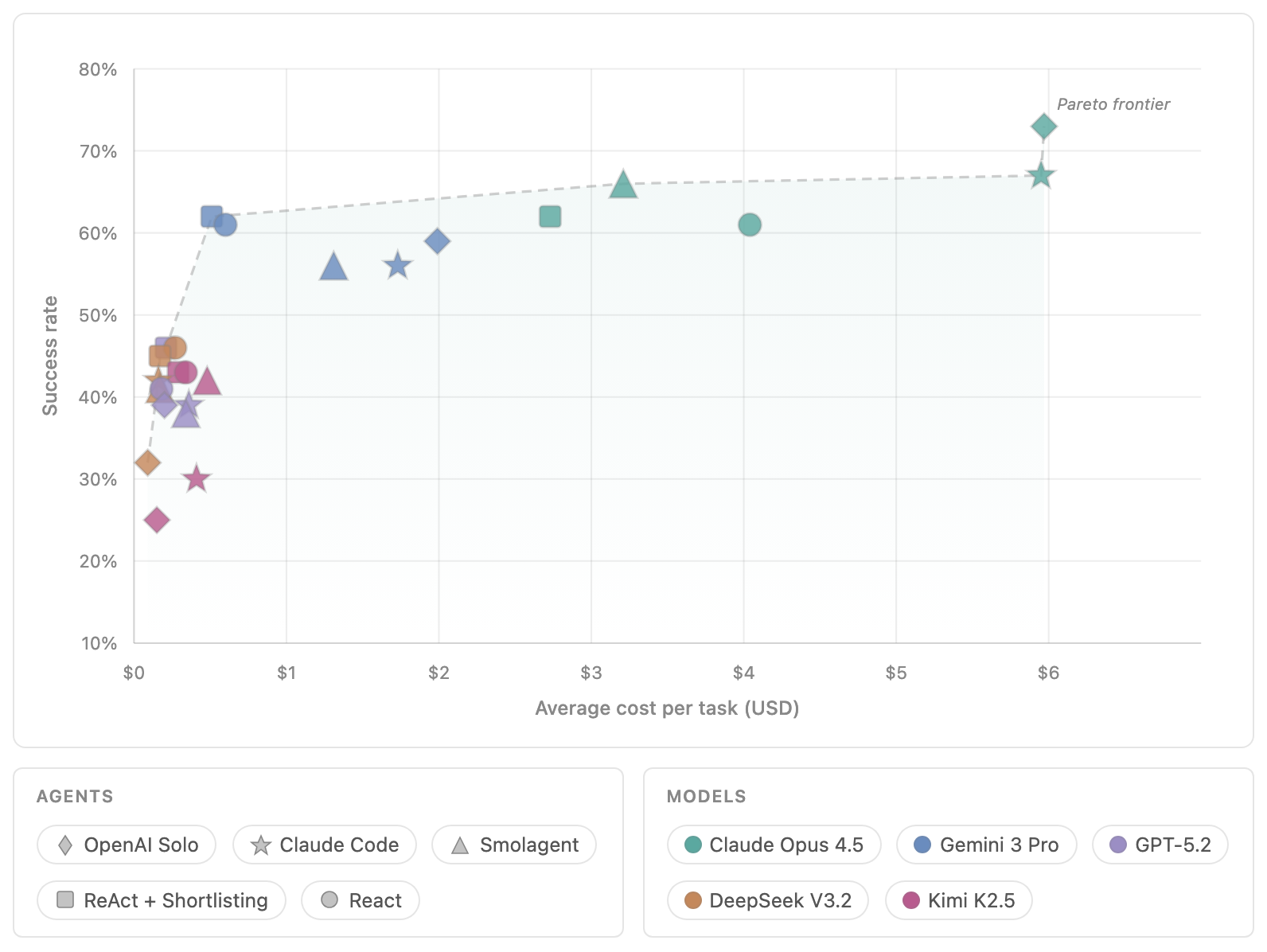
The upper-right corner of that kind of chart is powerful but expensive. The upper-left corner is usually more attractive because it represents strong results at lower cost. In production, however, the answer depends on the workflow. Security patches, financial transactions, and legal review may justify a more expensive configuration because the cost of a wrong answer is high. Drafting, internal research, and repetitive triage may prefer a cheaper configuration if a human will still review the output.
That framing changes agent procurement too. Asking "what is your SWE-Bench score?" is not enough. Teams also need to ask: what is our average cost per task? What is the p95 cost? How long and how expensively do failed sessions run? How does cost change as tool calls increase? Is there an early-stop policy when the agent is clearly stuck? Open Agent Leaderboard does not answer those questions for every company, but it moves them into the public evaluation vocabulary.
Tool shortlisting shows the power of small architecture choices
One of the more practical findings in the announcement is tool shortlisting. The researchers say tool shortlisting improved performance across all tested models. Instead of forcing an agent to search every available tool on every step, the system helps it focus on the tools most relevant to the current task.
That should feel familiar to teams building with MCP servers and connectors. The number of available tools is growing quickly. But more tools do not automatically make an agent smarter. Similar tool names, overlapping permissions, partial failures, and inconsistent return shapes can make the agent more confused. A broad tool surface increases choice cost.
The design question is therefore not "how many tools can we attach?" It is "how well can we narrow the tool set for this task?" A stronger agent platform looks at the request, builds a relevant subset of tools, considers permission and cost, chooses an execution order, and changes path quickly when a tool fails. Those choices are invisible on a model-only leaderboard. They are exactly the choices an agent-system evaluation should expose.
Openness and reproducibility matter more for agents
Hugging Face emphasizes that the leaderboard, Exgentic code, paper, and results dataset are open from day one. The GitHub repository uses the Apache-2.0 license, and the README points toward benchmarks and agents such as tau2, AppWorld, BrowseComp+, SWE-Bench, BFCL, Claude Code, Codex CLI, Gemini CLI, OpenAI MCP, and SmolAgents. The leaderboard is not only a scoreboard. It is also an invitation to reproduce and extend the harness.
That matters because agent demos are easy to oversell. A carefully chosen task, a cleaned-up repository, a prompt designed by insiders, and a video with failures removed can make an agent look more capable than it is. Public harnesses, traces, and cost reports give other teams something to rerun, inspect, and challenge.
Open evaluation still has limits. Benchmarks capture only part of reality. A company's legacy monorepo, internal permission system, slow CI, security policy, and private APIs will rarely be represented faithfully in a public benchmark. So a leaderboard score should not be translated directly into "this is the best agent for our company." The stronger lesson is that internal evals should also measure full agent systems, not only model responses.
Open-weight models face a generality question
The next-step discussion in the announcement is also worth watching. After launch, the team added open-weight models such as DeepSeek V3.2 and Kimi K2.5. The post says they can be competitive in certain configurations, but on average lag frontier closed-source models by 18-29 percentage points. The arXiv abstract frames this as a "generality sinks" problem: some models collapse consistently under particular agent architectures or benchmark families.
That does not mean open-weight models are unusable. It creates a better question. In which domains, with which agent wrapper, and with which tool set are open-weight models stable enough? When do cost, latency, data control, and deployment flexibility compensate for lower average success? If a model performs well on one benchmark, how quickly does it degrade when moved to a different agent environment?
For AI infrastructure teams, those questions are central. Self-hosting or private deployment can be attractive for regulatory, security, cost, and latency reasons. But agent workloads expose more failure surfaces than ordinary chat. If an open-weight model is going to power agents, teams need cross-environment evals and failure traces, not just standalone reasoning scores.
The reaction is quiet, but the direction is clear
This announcement did not create the immediate public noise of a frontier model launch. The Korean research note found no major direct discussion on Hacker News or Reddit at the time of writing. Secondary summaries and AI-agent community posts mostly focused on the same point: agent evaluation needs to compare execution systems and costs, not only model scores. Awesome Agents emphasized the variance explained by backbone model choice, while Chinese and Japanese summaries read the project as an early step toward public agent-evaluation standards.
That quieter response makes sense. A leaderboard is not a new chat product people can immediately try. It is infrastructure for evaluating products and research. Over time, that kind of infrastructure can matter more than a launch demo. Model names change every few weeks, and user interfaces change quickly. Evaluation methods seep into procurement, internal engineering practice, and the language teams use when they ask whether an agent is good.
What development teams should change
First, internal evals should move to the agent level. Do not compare only model A and model B on answer quality. Run tasks with the actual tool set, permissions, sandbox, retry policy, memory, and logging attached. The deployed agent is the system, not the model endpoint.
Second, cost belongs beside success rate. Track average cost, p95 cost, failed-task cost, early-stop rate, retry count, and tool-call count. As automation volume rises, an agent that fails while working very hard can become expensive quickly.
Third, teams need a taxonomy of failures. Aggregate score is convenient, but two agents with the same 60% success rate can fail for very different reasons. One may skip evidence. Another may choose the wrong tool. Another may understand the task but break the execution environment. Remediation depends on knowing which kind of failure is happening.
Fourth, benchmark-specific tuning and generality should be kept separate. A product that only needs to handle one customer-support workflow should be evaluated differently from an internal agent platform that will run across many domains. Open Agent Leaderboard is closer to the second question. Not every team needs to copy it directly, but any team claiming generality should bring evidence from multiple environments.
The next competition is evaluation
Open Agent Leaderboard is not a flashy product launch. It is not a new chat window and not a new foundation model. But it is an important signal for the agent market. The competition is moving from "our model is smarter" toward "our agent system finishes work across environments, at a defensible cost, in a reproducible way."
That shift creates useful pressure for AI builders. Traces become more important than demo videos. Cost-success frontiers become more important than single benchmark scores. Tool interfaces and failure policies become more important than the model name alone. As agents move into real workflows, these questions become harder to avoid.
The 73% number is only the headline. The more important fact is that it is not a model-only score. The same model can change with the agent wrapper. The same success rate can mean different things at different costs. The same failure can point to completely different fixes depending on its cause. It is still too early to say the model-only benchmark era is over, but the agent report card can no longer be a single line with a model name.