GLM-5.1 tops SWE-Bench Pro as Meta closes its open-source era
China-based Z.ai released GLM-5.1 under MIT terms and topped SWE-Bench Pro with a 744B MoE coding model, sharpening the open-source versus closed-model split.
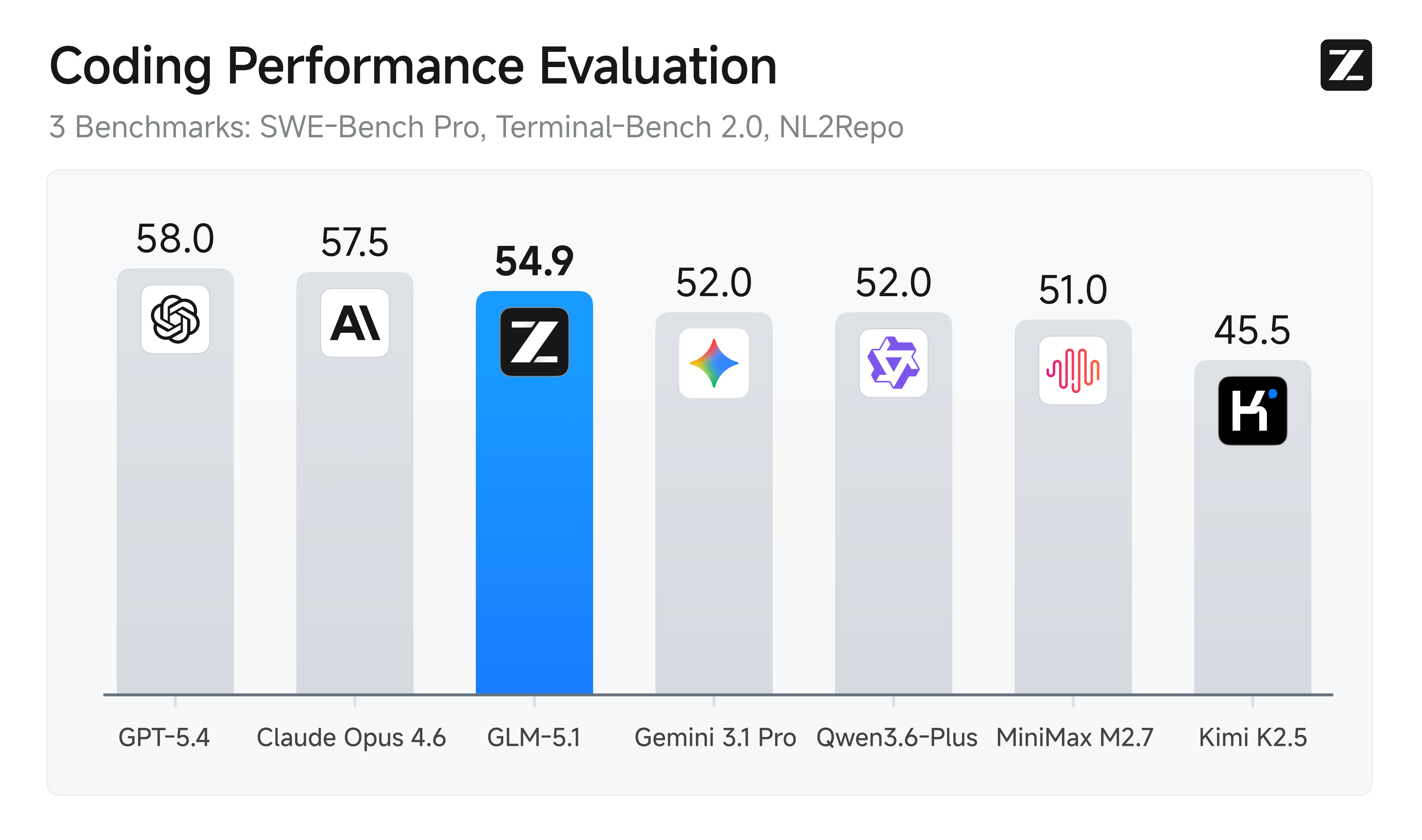
- What happened: Z.ai released GLM-5.1, a 744B-parameter MoE model, under an MIT license and reported a 58.4 SWE-Bench Pro score.
- The result placed GLM-5.1 ahead of Claude Opus 4.6 and GPT-5.4 on that benchmark, while closed models still lead several broader coding and reasoning tests.
- Why it matters: an open model now has a credible claim to first place on a practical coding benchmark rather than only on smaller synthetic leaderboards.
- Context: the release landed one day before Meta introduced Muse Spark as a closed model, creating a sharp contrast in AI platform strategy.
- Watch: MIT licensing does not make deployment easy; the full model still demands large memory, careful serving, and a realistic view of benchmark scope.
On April 7, an open model reached the top of a serious coding benchmark. Z.ai, formerly Zhipu AI, released GLM-5.1 and reported a 58.4 score on SWE-Bench Pro, ahead of Claude Opus 4.6 at 57.3 and GPT-5.4 at 57.7. The claim matters because SWE-Bench Pro is framed around practical software-engineering tasks, not only short-form code completion. For the first time in this article's comparison set, an open model beat the leading closed models on that specific coding benchmark.
The timing made the release more visible. On April 8, Meta introduced Muse Spark as a closed model after spending years as one of the most prominent open-model advocates through Llama. In the same week, Z.ai pushed a permissive model release while Meta moved in the opposite direction. The result is not a clean verdict on open source versus closed AI, but it gives developers a concrete case study: open distribution can now sit near the top of at least one frontier coding leaderboard.
Who Z.ai Is
Z.ai began in 2019 as a spinout from Tsinghua University's Knowledge Engineering Group. The company was led by professors Tang Jie and Li Juanzi and later raised more than $1.4 billion across 12 rounds from investors that included Alibaba, Tencent, Ant Group, Xiaomi, and Prosperity7 Ventures, the Aramco-backed fund.
In January 2026, Z.ai became one of the first major Chinese LLM companies to complete a Hong Kong Stock Exchange IPO. By April, the Korean source article tracked its market capitalization at roughly $44.3 billion. That arc matters because GLM-5.1 is not a one-off research checkpoint from a small lab. It is the latest product from a public company that has spent years building a model family and a commercial distribution path.
The model lineage is also important. Z.ai started with GLM-10B in 2021, moved to the GPT-3-scale GLM-130B in 2022, helped popularize smaller Chinese models with ChatGLM-6B in 2023, and shipped GLM-4 All Tools in 2024. GLM-5.1 sits at the top of that sequence as a coding and agentic-execution-focused release.
The Open Coding Model Race
The broader open-model coding race has developed a clear geographic pattern. Chinese labs and companies such as DeepSeek, Qwen, Kimi, and Z.ai have treated open releases as a primary distribution strategy. OpenAI, Anthropic, and Google continue to emphasize proprietary hosted models, API access, and integrated product surfaces. That split does not map perfectly onto model quality, but it does shape how developers can inspect, modify, deploy, and govern the systems they use.
The export-control context makes GLM-5.1 more than a benchmark story. Z.ai has been on the U.S. Entity List since January 2025, which limits legal access to Nvidia data-center GPUs. The source article says GLM-5.1 was trained with roughly 100,000 Huawei Ascend 910B accelerators and the MindSpore framework. If that account holds across the technical disclosures, the model is another example of restrictions accelerating domestic infrastructure capability rather than simply stopping frontier-model work.
For developers outside China, the immediate question is practical rather than geopolitical. If an MIT-licensed model can reach the top of SWE-Bench Pro while using a non-Nvidia training stack, procurement and architecture choices widen. Teams that cannot send code to a U.S. hosted model, teams that need local or private deployment, and teams that want more control over fine-tuning now have a stronger model to evaluate.
What The 744B MoE Design Changes
GLM-5.1 uses a Mixture-of-Experts architecture with 744B total parameters, while some sources cite 754B. Instead of activating the full model for every token, it selects 8 experts out of 256, keeping active parameters around 40B. That design lets the model carry a very large total parameter count while keeping inference closer to a smaller active compute profile.
| Benchmark | GLM-5.1 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| SWE-Bench Pro | 58.4 first | 57.3 | 57.7 |
| SWE-Bench Verified | 77.8 | 80.8 first | 79.2 |
| Terminal-Bench 2.0 | 63.5 | 69.4 | 75.1 first |
| GPQA-Diamond | 86.2 | 91.3 first | 89.7 |
| CyberGym | 68.7 first | 66.6 | 65.1 |
| MCP-Atlas | 71.8 first | 68.2 | 67.9 |
The context window is 200K tokens, and the maximum output length is 128K tokens. Two attention-related details carry the deployment story. DeepSeek Sparse Attention is used to reduce deployment cost while preserving long-context behavior, and Multi-head Latent Attention reduces memory overhead by 33 percent versus standard multi-head attention. Those choices point to the same product goal: keep a large agentic model usable over long tasks without making every token prohibitively expensive.
The pretraining corpus was 28.5 trillion tokens, up from 23 trillion tokens for GLM-4.5. The bigger difference, however, is post-training. GLM-5.1 is described as sharing the GLM-5 pretraining base while adding coding-agent and long-horizon autonomous-execution training.
Asynchronous RL With Slime
The post-training infrastructure is called slime, an asynchronous reinforcement-learning system designed to improve training throughput and iteration speed. The source article frames this as a central reason GLM-5.1 performs well on agentic coding tasks. In that view, the benchmark result is not only a reward for scale. It is also a reward for teaching the model how to plan, call tools, recover from failures, and continue across many rounds.
One Hacker News commenter summarized the point as an infrastructure claim: the real gap between frontier and non-frontier labs is not only pretraining compute, but RL infrastructure. That is not a formal benchmark result, yet it captures what many coding-agent builders now see in practice. Long-running coding performance depends on tool-use policy, test feedback, retry behavior, and the ability to avoid getting stuck after partial failure.
First On SWE-Bench Pro, Not First Everywhere
The benchmark table needs a careful reading. GLM-5.1's 58.4 SWE-Bench Pro score is the headline. It is also narrower than a claim of overall coding supremacy. On SWE-Bench Verified, Claude Opus 4.6 leads with 80.8 versus GLM-5.1 at 77.8. On Terminal-Bench 2.0, GPT-5.4 leads with 75.1 while GLM-5.1 scores 63.5. On GPQA-Diamond, Claude Opus 4.6 leads by more than five points.
The pattern is more specific. GLM-5.1 looks strongest in agentic execution, tool use, security tasks, and long autonomous coding runs. It leads CyberGym at 68.7 and MCP-Atlas at 71.8. It does not lead every reasoning or software-engineering benchmark. For platform teams, that means GLM-5.1 should be evaluated against the exact workflow where it will run: repo repair, long refactors, tool-heavy debugging, security tasks, or CI-integrated code review.
The distinction matters because AI coding claims are often compressed into a single leaderboard screenshot. A model that wins one hard benchmark can still lose on latency, terminal use, repo navigation, instruction following, reasoning, or safety constraints. GLM-5.1 gives the open-model ecosystem a symbolic win, but the practical question remains workload-specific.
The Eight-Hour Coding Agent Claim
GLM-5.1's most developer-facing claim is the ability to run coding tasks autonomously for up to 8 hours. Z.ai describes a loop of planning, execution, testing, fixing, and optimization across hundreds of rounds and thousands of tool calls. That moves the product framing away from autocomplete and toward a model that can hold state through a workday-scale task.
built from scratch
after 178 autonomous rounds
from 2.6x to 35.7x
The examples are concrete. In one demo, the model built a Linux-style desktop environment from scratch over 655 iterations in 8 hours. In another, it improved vector database query throughput by 6.9x after 178 autonomous rounds. In a CUDA kernel optimization example, it moved from a 2.6x speedup to 35.7x through continued self-directed tuning.
These examples still need the usual caution around demos. The target tasks, scaffolding, tool environment, and evaluation harness matter. But they describe the kind of work coding agents are increasingly asked to do: not answering a prompt once, but staying inside a repo, running tests, changing code, measuring the result, and repeating.
MIT Terms And The Deployment Reality
The licensing decision is as important as the benchmark. GLM-5.1 is released under the MIT license, which allows download, inspection, modification, fine-tuning, and commercial use with minimal restriction. That differs sharply from Meta's Llama license family, which includes custom terms, and from restricted model licenses that limit commercial or large-scale use.
For companies, permissive licensing changes the governance conversation. A team can evaluate private deployment, regulated workloads, code-sensitive tasks, and custom fine-tuning without relying entirely on a vendor-hosted endpoint. It also lets platform teams inspect weights and serving behavior in a way that API-only models do not allow.
The same point should not be overstated. A 744B MoE model is not laptop software. Full precision deployment needs roughly 1.5TB of disk and multiple GPUs. Even aggressive 2-bit quantization can require around 236GB of disk and more than 256GB of system RAM. The practical local-deployment target is enterprise infrastructure, specialized cloud setups, or heavily quantized community builds rather than a typical individual developer machine.
Meta's Closed Turn
Meta's Muse Spark release sharpened the comparison because it arrived one day later and was closed. For years, Meta used Llama to position itself as the large Western company most committed to open model distribution. Muse Spark moved in the other direction.
| Category | Z.ai GLM-5.1 | Meta Muse Spark |
|---|---|---|
| Release date | April 7, 2026 | April 8, 2026 |
| License | MIT, permissive | Closed |
| Strategy | Expand open distribution | Move from open model branding to closed control |
| Business model | Open ecosystem plus premium API | Proprietary service and API |
| Local deployment | Possible through llama.cpp and GGUF paths | Not available |
| Main bet | Developer ecosystem reach | Exclusive competitive advantage |
Z.ai's strategy is not pure altruism. The Korean source notes that GLM-5 Turbo remains proprietary and that Z.ai raised API prices by 8 to 17 percent around the GLM-5.1 launch. The business model looks more like open ecosystem expansion combined with paid premium access. That may make the strategy more durable than a release plan based only on goodwill.
What Developers Can Actually Do With It
The most immediate developer impact is cost. The source article lists Z.ai's official API price at $1.40 per million input tokens and $4.40 per million output tokens. Through OpenRouter, it lists $0.95 input and $3.15 output. Compared with Claude Opus 4.6 pricing at $15 input and $75 output, that creates a large cost gap for coding-agent workloads that can generate millions of tokens during repo-wide tasks.
That difference changes which workflows are affordable. A team that cannot justify calling a top closed model on every pull request might test GLM-5.1 for lower-cost review, refactoring, bug reproduction, or test-generation jobs. Major AI coding tools mentioned in the source article, including Claude Code, Cursor, Cline, and Kilo Code, already have paths to GLM-5.1-compatible APIs.
Local and private deployment create another category. MIT licensing plus quantization support through llama.cpp and Unsloth makes the model relevant for air-gapped or highly regulated environments. Finance, defense, healthcare, and industrial teams often cannot send full repository context, logs, schemas, or incident traces to a public hosted model. For them, a difficult but possible private deployment can be more valuable than a simpler public API.
The practical scenarios are specific. A team could run overnight legacy-code refactors, test-coverage expansion, or dependency migrations and review the resulting pull request in the morning. A regulated organization could evaluate an internal coding agent that never leaves its controlled environment. A CI/CD platform team could use the lower API cost to run AI checks on more pull requests without turning model usage into a budget exception.
Community Reaction
The GLM-5.1 thread on Hacker News reached 287 points and 90 comments, while an earlier GLM-5 thread reached 373 points and 452 comments. The positive reactions clustered around three points: the freedom of the MIT license, the reported ability to train near-frontier models with Huawei hardware, and the technical interest in slime as asynchronous RL infrastructure.
The skeptical reactions were also concrete. One Hacker News user argued that Z.ai removed flagship model updates from the Pro plan and raised prices sharply around the GLM-5 release. That complaint does not invalidate the open-weight release, but it highlights the gap between source availability and convenient access. If the model is open but hosted access becomes more expensive, developers still need to examine the total cost of serving, API use, and maintenance.
There was also benchmark skepticism. Commenters asked for more standardized controlled tests and pointed out that Claude remains ahead on broader coding comparisons. The critique is reasonable. SWE-Bench Pro first place is meaningful, but it should not be turned into a claim that open models have fully overtaken closed models across software engineering.
The r/LocalLLaMA community focused on GGUF quantizations and local-running guides. That is where the licensing story becomes operational. Community quantization work can make a 744B model more accessible, but the model remains enormous. The mood is best described as interested but realistic: GLM-5.1 expands the frontier of what can be tried locally or privately, while still requiring serious hardware.
Two AI Futures In One Week
GLM-5.1 and Muse Spark put two AI futures side by side. Z.ai is betting that releasing a strong model under MIT terms will attract developers, create ecosystem gravity, and feed demand for paid APIs or premium models. Meta's Muse Spark move suggests a different view: the strongest competitive advantage may come from keeping more capability inside a proprietary service.
Both strategies can be rational. Open releases can build trust, portability, customization, and community distribution. Closed releases can preserve product control, safety knobs, monetization, and integrated user experience. Developers do not need a philosophical winner to get value from the competition. They need credible options with clear tradeoffs.
GLM-5.1 gives the open-model side a new asset: a permissively licensed model with a top SWE-Bench Pro result and a long-horizon coding-agent story. It does not eliminate the reasons many teams will still choose Claude, GPT, Gemini, or other hosted systems. It does, however, force those choices to be argued on concrete grounds such as benchmark mix, governance, latency, cost, privacy, deployment control, and tool reliability.
The final signal is straightforward. A model trained without Nvidia data-center GPUs, released under MIT terms, and designed for 8-hour coding runs has reached the top of SWE-Bench Pro. One year earlier, that combination would have sounded unlikely. For AI coding, the next phase is not only about which model scores highest. It is about whether teams want an integrated closed service, a controllable open model, or a portfolio that uses both depending on the workflow.