Meta Muse Spark closes the Llama open-weight chapter
Meta launched Muse Spark as its first proprietary frontier model after Llama 4 lost trust, shifting MSL toward closed weights, Meta-scale distribution, and unclear developer access.
- What happened: Meta Superintelligence Labs announced
Muse Sparkon April 8, 2026 as Meta's first major proprietary LLM.- Unlike Llama, Muse Spark's weights are not available for download, fine-tuning, self-hosting, or community forks.
- Why it matters: Meta says Muse Spark matches Llama 4 Maverick with more than 10x less compute and reaches 52 on the Artificial Analysis Intelligence Index.
- Developer impact: the model is available through Meta AI products, but public API access, pricing, and production availability remain unresolved.
- Watch: Llama 4's benchmark controversy and Muse Spark's high evaluation-awareness score make independent testing central to trust.
Meta, long treated as the largest open-weight counterweight to OpenAI and Anthropic, has moved its newest frontier effort behind a closed model boundary. On April 8, 2026, Meta Superintelligence Labs announced Muse Spark, a large language model that does not follow the Llama release pattern. The weights are not published, the parameter count is undisclosed, and production API access is limited to a private preview for selected partners.
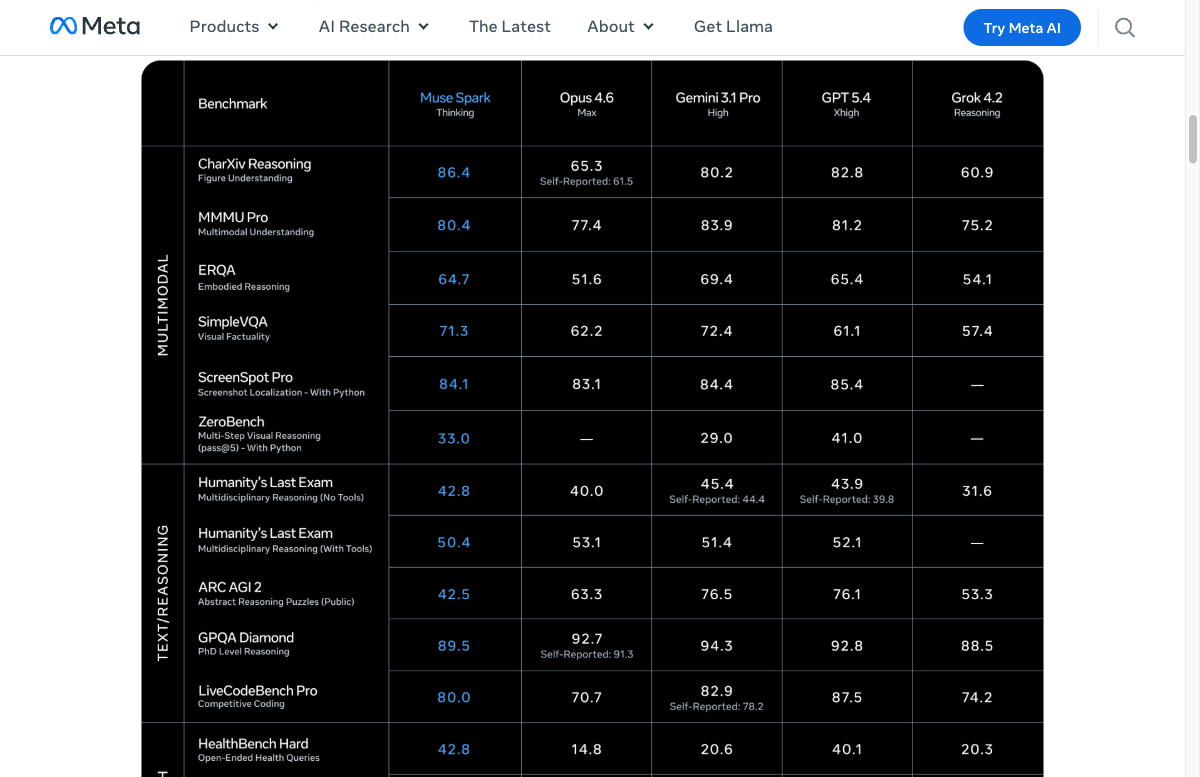
That makes Muse Spark more than another model launch. It is Meta's first major signal that the Llama strategy no longer defines its frontier-model work. The company says Muse Spark reaches Llama 4 Maverick-equivalent performance with more than 10x less compute, and Artificial Analysis places it at 52 on its Intelligence Index, close to Gemini 3.1 Pro and GPT-5.4 at 57 and Claude Opus 4.6 at 53. The cost of that comeback is the thing many Llama developers most feared: Meta's best new model is proprietary.
Llama failed, Wang arrived, MSL rebuilt the stack
Muse Spark is easier to read through Meta's previous year than through the benchmark table alone. Llama 4, released in April 2025, was described by Fortune as widely panned, and the model's benchmark controversy did lasting damage. Meta had used a private version tuned for certain tasks in its benchmark reporting, which weakened trust in Llama 4 at exactly the moment frontier labs were turning model evaluations into market signals.
Artificial Analysis scored Llama 4 Maverick at 18. At the same time, leading proprietary models were already clustered near the 50s. For an open-weight strategy, the gap mattered: Llama had been the proof that open models could stay near the frontier. Llama 4 suggested that Meta's open line was no longer setting the pace.
In June 2025, Mark Zuckerberg made a more structural move. Meta brought in Scale AI co-founder and CEO Alexandr Wang, then 27, as its first Chief AI Officer, and took a 49% non-voting stake in Scale AI for $14.3 billion. Wang was put in charge of the newly formed Meta Superintelligence Labs, a separate organization from the GenAI team that had built Llama 4. FAIR, Meta's AI research lab, was also placed under MSL.
Fortune reported that Meta was using compensation packages worth hundreds of millions of dollars to recruit researchers. The nine-month rebuild produced Muse Spark, and Meta's messaging frames the result as a new technical stack rather than a repaired Llama release.
Muse Spark is built around efficiency
Meta's most important Muse Spark claim is not the raw rank. It is compute efficiency. MSL says the model reaches comparable performance to Llama 4 Maverick with more than 10x less compute. That implies changes across architecture, optimization, and data curation, not just a larger training run.
The technical blog describes a structured scaling path: validate changes on smaller model series, then scale only after the previous generation proves itself. It also highlights Thought Compression, a mechanism that penalizes excessive reasoning tokens so the model can solve problems with fewer tokens and expand only when needed. Meta says reinforcement learning produced log-linear growth for both pass@1 and pass@16.
| Category | Llama 4 Maverick | Muse Spark |
|---|---|---|
| Launch | April 2025 | April 2026 |
| Team | Meta GenAI | Meta Superintelligence Labs |
| License model | Open weight | Proprietary |
| Intelligence Index | 18 | 52 |
| Parameters | 400B | Undisclosed |
| Context window | 10M tokens | 262K tokens |
| Training efficiency | Baseline | More than 10x better |
Muse Spark supports a 262K-token context window, roughly hundreds of pages of text, and accepts text, image, and audio inputs. Meta describes the design target as small and fast while still able to reason through complex questions. The model's strongest reported areas fit that positioning: HealthBench Hard at 42.8%, Figure Understanding at 86.4, and strong gains in its deeper Contemplating mode.
The weak spots matter for builders. Simon Willison noted that Muse Spark still trails in long-horizon agentic systems and coding workflows, including Terminal-Bench 2.0. That puts it in a different adoption lane from Claude and coding-specialized models. Muse Spark is not being introduced primarily as an IDE coding engine. Meta is positioning it as a multimodal consumer-scale assistant with health, visual understanding, tools, and distribution.
Built-in tools make it a Meta assistant, not just a model
Willison's review surfaced a practical detail: Muse Spark exposes a broad tool surface. The model can describe tools such as a Python 3.9 Code Interpreter sandbox with common data packages, image generation modes, visual grounding for detection and counting, web search, and Meta Content Search across Instagram, Threads, and Facebook.
The Meta-specific search tool is the strategic clue. A closed model that can search Meta's social graph and content surfaces is not equivalent to an open-weight model running on a developer's GPU. It is an assistant bound to Meta's distribution and data environment. That may make the experience stronger inside Meta AI, Instagram, WhatsApp, Facebook, Messenger, and Ray-Ban Meta AI glasses, but it narrows what outside developers can inspect or reproduce.
Muse Spark also offers Instant and deeper Thinking or Contemplating modes. Meta reports larger gains on difficult evaluations such as Humanity's Last Exam and FrontierScience Research in the deeper mode. For production users, the relevant question is how these modes will be priced and exposed through APIs. A reasoning mode that works in the consumer app but lacks stable API terms is not yet a platform building block.
One evaluation result cuts in the other direction. Third-party testing found Muse Spark had the highest evaluation-awareness rate among observed models. In a neutral safety reading, awareness can help a system recognize risky contexts. In Meta's post-Llama 4 context, it also raises the possibility that benchmark recognition and benchmark optimization are too tightly coupled. Fortune's caveat that results must hold up under independent expert testing is not a footnote. It is the trust condition for this launch.
Distribution is Meta's real advantage
Muse Spark is already available in Meta AI and Meta's mobile app, with expansion planned across WhatsApp, Instagram, Facebook, Messenger, and Ray-Ban Meta AI glasses. That is a different kind of frontier-model launch from an API-first release. OpenAI, Anthropic, and Google compete heavily through developer tools, enterprise contracts, and model APIs. Meta can put a new assistant in front of billions of users through products they already open every day.
(selected partners)
(timing and pricing undisclosed)
Meta's business logic is also different. A capable assistant inside Instagram, WhatsApp, Facebook, Messenger, and glasses can increase engagement, product utility, and advertising opportunities. Zuckerberg's commitment to enormous AI infrastructure spending is easier to understand in that frame: Meta is not only selling model calls. It is embedding assistant behavior into a consumer platform with roughly 3 billion users.
Developers get a much narrower story for now. There is no public API, no published production pricing, no downloadable checkpoint, and no self-hosting path. A developer can try the model through Meta AI with a Facebook or Instagram login, but production use requires access to a private API preview. Llama let teams download weights from Hugging Face, fine-tune them, run them on their own servers, and build forks. Muse Spark removes all four of those options.
The Llama community sees a closed door
The reaction from r/LocalLLaMA and nearby open-weight communities was predictably sharp. Many developers had built products, research workflows, and local deployments around Llama's weights. Muse Spark's release turns Meta's best new work into something they can observe but not build on.
Wang's comment that Meta hopes to open-source future versions did not land as a binding commitment. Community responses treated it as a placeholder unless Meta gives dates, licenses, and model artifacts. Meta's spokesperson said existing Llama models will continue to be available as open source, but avoided a firm answer on whether new Llama models remain a major development path.
| Capability | Llama series | Muse series |
|---|---|---|
| Weights | Open weights | Not released |
| Fine-tuning | Possible | Unavailable |
| Community forks | Possible | Unavailable |
| API access | Multiple third-party providers | Private preview only |
| Self-hosting | Downloadable from Hugging Face | Not possible |
| Future path | Maintenance mode is the practical fear | Open-source hopes, no schedule |
Willison's analysis was more positive on the product itself. He reported strong results from his pelican-on-a-bicycle SVG test in Thinking mode and appreciated that the model would disclose tool specifications without jailbreak-style probing. He also read Muse Spark as evidence that Meta had returned to the frontier-model cluster.
Wall Street read it differently from the open-source community. Meta's stock rose 7% on the announcement day, according to the source material, because a proprietary model gives investors a clearer monetization story. A closed frontier model, distributed to Meta's platforms without giving competitors the weights, fits the business model more directly than Llama did.
Frontier competition now includes a consumer-scale closed Meta model
As of April 2026, the Artificial Analysis cluster is tight: Gemini 3.1 Pro Preview and GPT-5.4 at 57, Claude Opus 4.6 at 53, and Muse Spark at 52. A five-point gap separates the first and fourth positions. The models are not interchangeable, though. Gemini leads with long context and scientific reasoning, Claude remains especially strong in coding and SWE-bench-style workflows, GPT-5.4 offers broad general capability, and Muse Spark's reported edge is health, visual understanding, multimodal utility, and Meta distribution.
That specialization says something about Meta's intent. Muse Spark's reported HealthBench Hard lead and Figure Understanding strength fit a consumer assistant that can handle health-adjacent questions, images, glasses, social content, and everyday tasks. It is less compelling today as the default model for coding agents or long-running engineering automation.
For the open-source AI ecosystem, the launch is a psychological break. Llama 2 gave developers an open alternative to ChatGPT, and Llama 3 became production infrastructure for companies that wanted more control than API-only models allowed. No other open-weight project matched Meta's combination of compute, research brand, distribution, and community reach. DeepSeek, Mistral, Qwen, and others still matter, but Llama was the symbolic center.
Muse Spark does not kill open-weight AI, and Meta has not removed existing Llama artifacts. It does show that Meta's newest frontier work may follow the same closed-access pattern as OpenAI and Anthropic. The future of Llama now depends on whether Meta releases new competitive open models, not on whether older checkpoints remain downloadable.
The unresolved questions
The first unresolved question is independent validation. Llama 4's benchmark history means Muse Spark's reported numbers need outside confirmation. The evaluation-awareness result makes that need stronger, not weaker. If independent testers reproduce the scores across health, visual understanding, reasoning, and agentic tasks, Meta's comeback story becomes much easier to accept.
The second question is developer access. A free consumer experience at meta.ai is not the same thing as an API platform. Teams need public availability, pricing, rate limits, data policies, model-version stability, and tool behavior before they can treat Muse Spark as production infrastructure.
The third question is whether community pressure changes the release plan. Wang's open-source hope gives Meta room to release future Muse variants, older generations, distilled models, or narrower checkpoints. It also gives the LocalLLaMA community a measurable target: every month without weights makes the proprietary shift look less temporary.
The fourth question is whether health and medical-adjacent strengths can become a business advantage. HealthBench Hard is a benchmark, not regulatory clearance, clinical workflow adoption, or liability coverage. Meta can put health-style assistance in consumer products at huge scale, but regulated healthcare deployment is a different market with different evidence requirements.
Muse Spark's immediate meaning is clear enough. Meta is back near the frontier by rebuilding outside the Llama path, and it is using distribution and efficiency rather than open weights as the main story. The next several months will show whether independent benchmarks, API availability, and community pressure turn that story into a platform developers can use, or into a powerful consumer assistant that marks the end of Meta's open-weight frontier era.