Google AI Overviews exposes the gap behind citation cards
A May 13 arXiv study measured 55K Google searches and 98K AI Overview claims, showing where citations, ranking, and publisher economics diverge.

- What happened: A May 13 arXiv paper measured Google AI Overviews across
55,393search queries and98,020claim-level units.- Overall activation was 13.7%, but question-style searches triggered AI Overviews 64.7% of the time.
- Key numbers: Among cited claims, 11.0% were not sufficiently supported by their cited pages, and 29.8% of cited domains did not appear on the same query's first results page.
- Why it matters: The risk in AI search is not only hallucination. It is a new information layer where ranking, citation, and click economics can separate.
- Teams building RAG products and answer UIs need to distinguish between "a source is attached" and "the claim is actually grounded."
Google's AI Overviews are no longer a side experiment at the top of search results. A user can type a question into the familiar search box and receive a generated answer before opening a separate chatbot. Links appear beside or below the answer as supporting cards. Google is pushing further in that direction. On January 27, 2026, it announced Gemini 3 as the global default model for AI Overviews and showed a path from an AI Overview directly into an AI Mode conversation. On May 6, Google said it would improve original links, news subscription links, public discussion previews, social source previews, and inline link previews inside AI Mode and AI Overviews.
The official story is optimistic. Google argues that AI search helps people reach deeper parts of the web and discover original sources more easily. But a May 13, 2026 arXiv paper, Measuring Google AI Overviews: Activation, Source Quality, Claim Fidelity, and Publisher Impact, asks a sharper set of questions. If an AI answer has citations, what exactly do those citations certify? Are they drawn from the same web that appears on the first page of traditional search results? If cited pages depend on advertising revenue, who pays when the answer layer absorbs the click?
The paper is less a polemic than a measurement study. Researchers from Washington University in St. Louis collected 55,393 trending queries from Google Trends in the United States over 40 days, from March 13 to April 21, 2026. They covered 19 topical categories and stored search results, AI Overview text, cited links, first-page organic results, page text, and advertising structure. They then decomposed AI Overview answers into 98,020 atomic claims and checked whether each claim was supported by the cited pages.
The important part is that the study does not reduce AI search quality to a single "accuracy" number. It measures activation, source selection, claim fidelity, and publisher economics together. That makes the result more uncomfortable. AI Overviews appear very often for question-style searches. Their cited sources are, on average, reasonably credible. Yet a citation card does not mean every sentence in the generated answer is grounded.
AI answers are not rare for question searches
The first number to inspect is activation. Across all observed queries, the researchers saw AI Overviews on 13.7% of searches. That might still sound limited. But when the query was phrased as a question, activation jumped to 64.7%. Non-question queries triggered AI Overviews 9.5% of the time. The paper summarizes the difference as a 6.8x higher activation rate for question queries.
That gap maps directly onto how many people search when they are less certain what they need. A user typing short keywords can still get a conventional results page. A user asking "what should I do," "why did this happen," or "how should I compare these options" is much more likely to see an AI answer. AI Overviews are therefore not just an extra feature attached to some informational queries. They are becoming the default interface for exploratory, question-shaped search.
Google's January announcement points in the same direction. Google said Search would better understand longer and more complex questions, then let users move from an AI Overview into follow-up questions in AI Mode. The search flow is shifting from "the user compares links" to "the system writes a first answer and the user asks next." That is convenient, but it also changes where verification happens.
In the old results-page model, users inspected titles, sources, rankings, and snippets before deciding what to open. In an AI Overview, they read the synthesized conclusion first. Sources then look like evidence attached to that conclusion. A user can feel they have already received the answer without opening any link. In that setting, a citation card can become less the end of verification and more an interface that makes verification appear complete.
The meaning of 29.8% outside first-page results
The second striking result is source selection. The researchers compared AI Overview cited domains with the first page of ordinary results for the same query. The conclusion is mixed. On one hand, AI Overview citations had higher average credibility scores than standard first-page results. That cuts against a simple version of the critique that AI Overviews are merely pulling random low-quality pages into the answer box.
At the same time, 29.8% of cited domains did not appear on the first page for that same query. This matters because Google describes AI Overviews as generated summaries integrated with Search's information systems. In practice, the citation pool a user sees inside the AI answer can differ materially from the result set the same user would encounter by scrolling through the first page. The web selected by ranking and the web selected as AI answer evidence are not always the same web.
That separation is a transparency problem even when it is not a source-quality problem. A cited source may be more credible than a first-page result. But the user cannot easily tell why that source was selected, why it did not appear in the organic ranking, or how the source-selection layer relates to search ranking. If AI answers have a separate citation layer, SEO and content strategy also change. Ranking on the first page and being cited by an answer system may become different goals.
For developers, the pattern looks familiar from RAG system design. Search ranking, retrieval candidates, reranking, answer synthesis, and citation rendering are separate layers. Showing links in the final UI does not make the retrieval policy or ranking policy transparent. In fact, the more links an interface displays, the easier it is for a user to feel that the answer is well-grounded. The real question is which source supports which sentence.
11% of 98,020 claims were not sufficiently supported
The most direct measurement is claim fidelity. The researchers split answers from 7,583 AI Overviews into atomic claims and evaluated 98,020 claims across 7,491 verifiable AI Overviews. The labels were clear, vague, ambiguous, incorrect, and omitted. If clear and vague are grouped as consistent, 89.0% of claims were consistent. If ambiguous, incorrect, and omitted are grouped as inconsistent, 11.0% were inconsistent.
That 11% should not be flattened into "AI Overviews are 11% wrong." The underlying categories are more specific. Incorrect claims, where the cited source directly contradicted the answer, accounted for 2.7%. Ambiguous claims were 1.4%. Omitted claims were 7.0%. The largest category was therefore not direct contradiction. It was the case where a specific answer claim could not be found in the cited page. The user sees a link, but the link may not actually say what the generated sentence says.
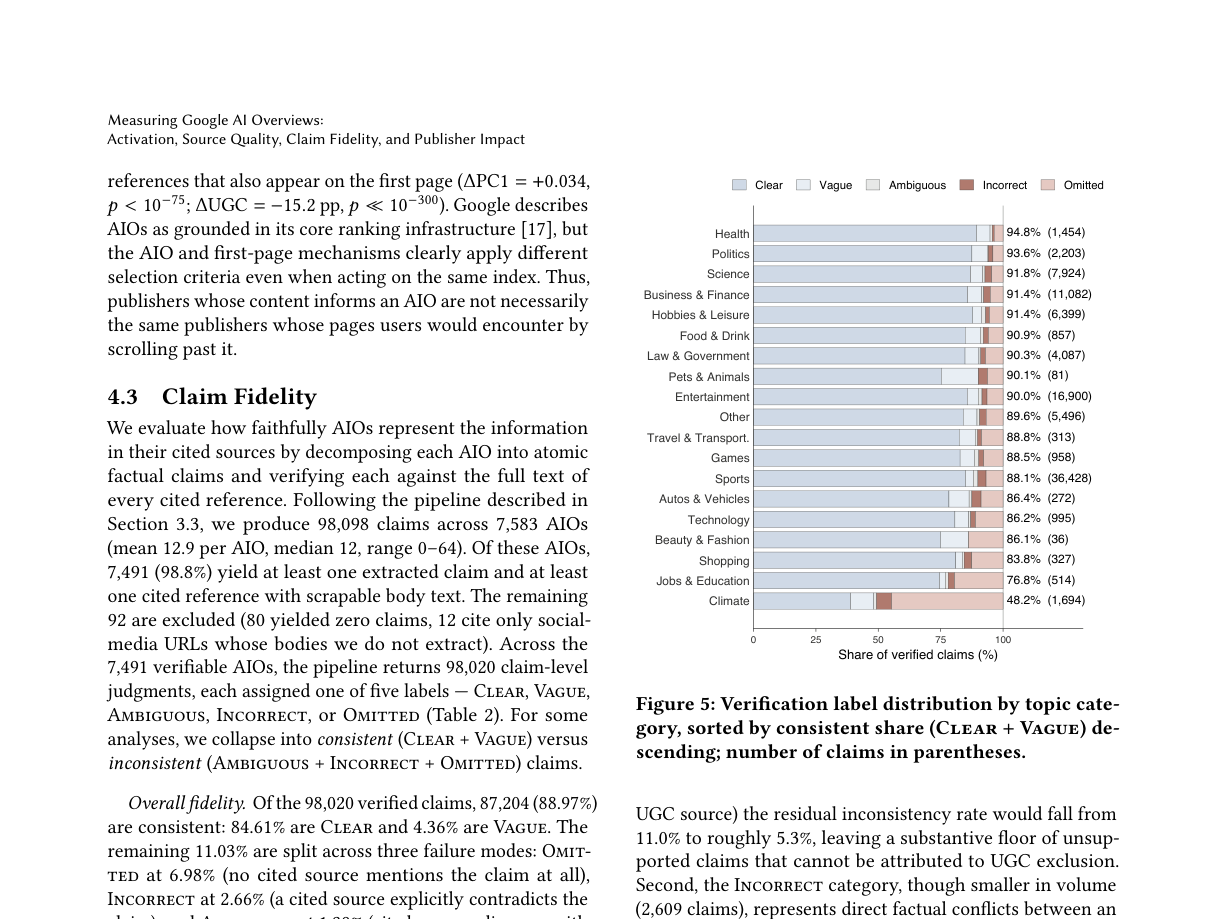
The paper also shows variation by topic. Health and Politics had higher consistent shares, while Jobs and Education and Climate were lower. The authors treat Climate cautiously, noting possible measurement artifacts. That caveat matters. Measuring AI search is hard. Results can vary by time, location, account state, query phrasing, interface experiments, and crawler detection. The researchers used fresh browser profiles, AWS Lambda, CAPTCHA retries, and randomized typing, but they do not claim perfect representation of every real user session.
Even with those limits, the numbers set a useful baseline for answer products. A product that shows sources must prove more than the existence of a source. It needs to show that each claim maps to source text. The same issue appears in enterprise search, document Q&A, support agents, and legal, medical, or financial RAG. Citation UI can create trust. Without claim-level grounding, it can also create the appearance of trust.
Google's link improvements face a harder measurement question
The timing is notable. On May 6, Google said it would add more direct links in AI Mode and AI Overviews, emphasize news subscription links, show public discussion and social source previews, and add desktop inline previews on hover. The message was clear: AI search is not cutting the web off, but improving how people reach original sources.
The paper attaches measurable questions to that claim. The more important issue is not only whether there are more links. It is what role those links play. A link can be an entrance to further exploration. It can also look like a certificate for an already generated answer. Or it can be a channel meant to preserve the revenue flows of an ad-supported web. These are different jobs.
Publisher economics make the tension sharper. The researchers report that at least 50.6% of pages cited by AI Overviews included display advertising. If AI Overviews reduce clicks, cited publishers may contribute the content used to answer the query while losing the ad impressions that support that content. Meanwhile, sponsored ads on the same Google results page can still be shown. The paper notes that in some cases Google ads appeared above the AI Overview.
One study cannot prove the total causal traffic impact of AI Overviews across the web. The researchers did not directly measure clickstream data. But it weakens the simple argument that publishers benefit because AI Overviews cite them. Citation and visits are not the same thing. Visibility and revenue are not the same thing either. Publisher strategy in AI search is becoming less about rank tracking alone and more about citation tracking, answer share, click-through attribution, and subscription paths.
The source debate is already moving beyond domains
The arXiv paper itself does not yet appear to have produced a large standalone Hacker News or GeekNews debate. But the same debate has already been underway. Earlier this year, GeekNews discussed reporting on a German health-search study that found Google AI Overviews citing YouTube more often than medical sites for health searches. The comments split in a familiar way. One side worried that AI answers could cite AI-generated or weakly verified videos, creating a loop of distorted reality. The other side argued that YouTube also includes hospitals, physicians, and public institutions, so platform-level criticism can be too coarse.
That argument lines up with this paper. Source quality does not end at the domain name. YouTube can contain university lectures, hospital explainers, personal anecdotes, SEO content, and AI-generated videos. Reddit has the same problem. Public discussion and lived experience can be valuable for some questions and dangerous for others. Since Google said on May 6 that it would bring more public online discussions and social media previews into AI answers, it becomes more important to separate source format from claim support.
AI product teams face the same issue. In an internal document search system, a Confluence page may be the source, but that page can contain outdated policy, newer decisions, comments, and drafts. For a coding agent, a GitHub issue can be the source, but the original description and the latest comment may disagree. The fact that a source exists matters less than which fragment of that source supports which claim.
Claim-level provenance becomes the real search quality bar
The most practical idea in the paper is claim-level provenance. Search and RAG products often stop at "the answer has links underneath it." That is not enough once answer interfaces become default experiences. Each sentence needs a basis. Missing support should be visible as missing support. Conflicting sources should be exposed as conflict rather than smoothed into a single confident paragraph.
| Layer | What users see | What must be verified |
|---|---|---|
| Search ranking | First-page links and snippets | How much the AI citation pool overlaps with ranked results |
| Answer generation | Synthesized conclusions and paragraphs | Whether each sentence is directly supported by cited text |
| Citation cards | Links, domains, and previews | Whether domain credibility and claim fidelity are managed separately |
| Economic impact | Source visibility inside the answer | Whether visibility becomes visits, ad impressions, or subscriptions |
This is not only Google's problem. Perplexity, ChatGPT Search, Microsoft Copilot Search, enterprise knowledge search, support chatbots, and developer-documentation agents all face the same pressure. Answer interfaces save users time, but they also absorb part of the verification work users previously did by reading original sources. If the system cannot perform that work, the time savings become a trust cost.
Several product questions follow. Should every cited source be displayed with the same weight? When a cited page does not directly support a claim, should the system remain silent or mark the claim as under-supported? If AI answers reduce clicks, what feedback loop should content providers receive? If question-style searches expose less experienced users to AI answers more often, should high-risk topics receive more conservative policies?
Conclusion
The paper does not argue that AI Overviews are useless or categorically dangerous. Its conclusion is more subtle. Google AI Overviews activate strongly for question-style searches and tend to select credible sources on average. But they also use a citation pool that can differ from first-page results, leave 11.0% of 98,020 measured claims insufficiently supported by cited pages, and create tension between publisher advertising economics and Google's own search ad layer.
The core issue is not simply that AI search can be wrong. It is that the trust structure of search is changing. In the link-list era, users opened and compared sources. In the AI Overview era, the system writes the answer first, and sources appear like warranties attached to that answer. Measuring exactly which sentences those warranties cover will define search quality, RAG quality, and publisher economics.
Google's May 6 blog post says it will make links richer inside AI search. That is a useful direction. But link quantity and link placement are not enough. The next competitive bar in AI search may be the ability to let users trace, sentence by sentence, what supports a claim and what does not.