11 Seconds of Audio in Under 8 Seconds, Without a GPU
Google and Arm show how on-device generative AI is moving from model releases into CPU runtimes, quantization, memory limits, and silicon features.

- What happened: Google and Arm published an on-device generative AI optimization path for
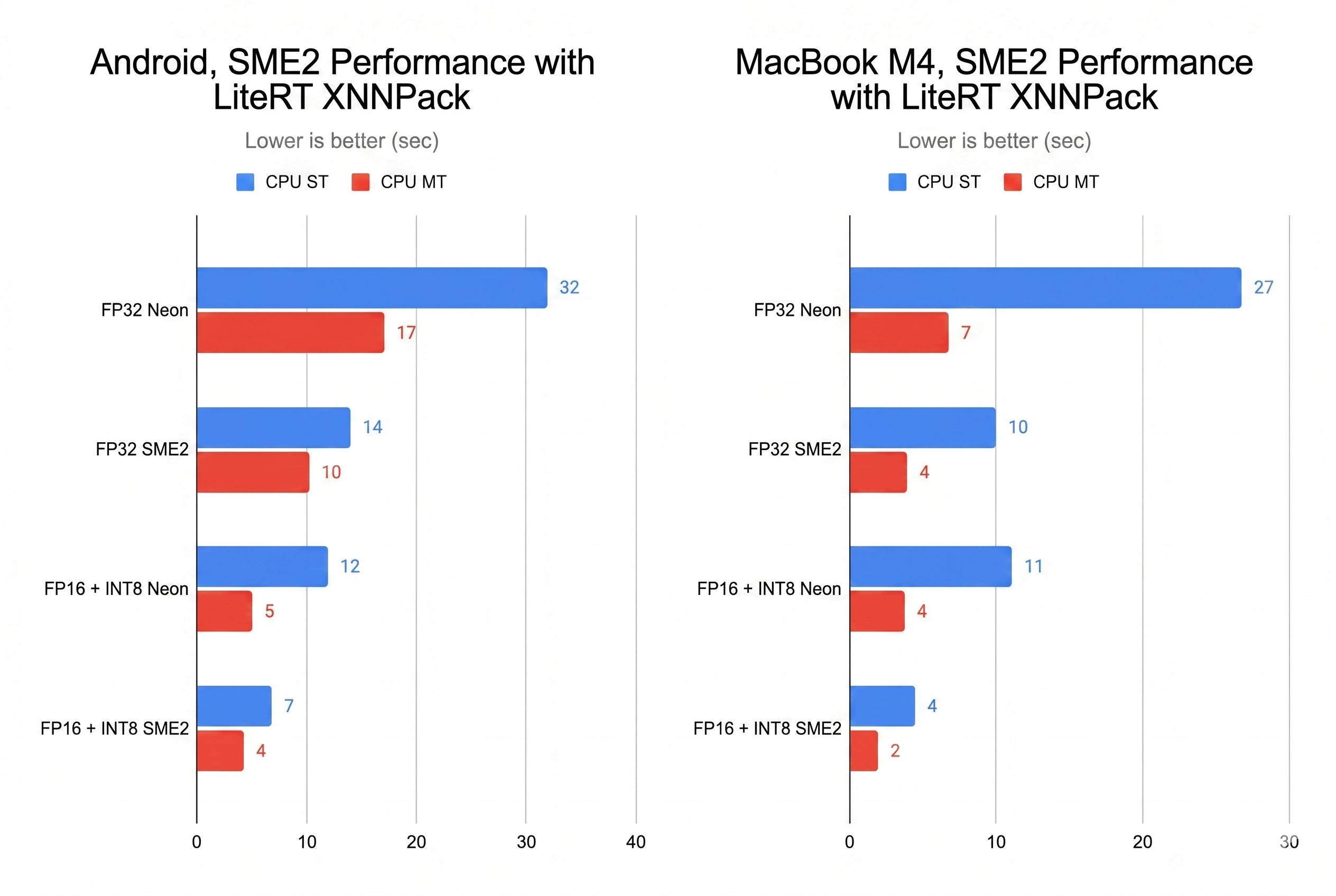
Stable Audio Open Smallusing LiteRT, XNNPACK, KleidiAI, and SME2.- The Google Developers Blog post is dated May 14, 2026, and says the Android SME2 single-thread path reduced a 14-second workload to 6.6 seconds.
- Key numbers: The DiT submodule saw a
3xperformance gain and a4xmemory reduction, while SME2 delivered more than a 2x speedup over NEON. - Why it matters: On-device AI is becoming a runtime, quantization, CPU instruction set, and deployment tooling problem, not just a model-size problem.
- Watch: This is one audio-generation workload. Product teams still need to test heat, battery drain, device support, model licensing, and quality regressions.
On May 14, 2026, the Google Developers Blog published a case study on Arm and Google AI Edge optimization. At first glance it looks like a straightforward mobile AI performance post. Google and Arm took Stability AI's Stable Audio Open Small, converted the PyTorch model into LiteRT, applied mixed INT8 and FP16 precision, and used XNNPACK plus Arm KleidiAI to reach SME2 on Arm CPUs. But the more interesting story is not simply that a demo got faster. It is that generative AI deployment is moving down the stack, from frontier-model announcements into runtimes, quantizers, memory pressure, instruction sets, and device coverage.
The numbers in the post are unusually concrete. Google and Arm say dynamic INT8 quantization on the DiT, or Diffusion Transformer, submodule improved performance by 3x and reduced memory use by 4x. In the end-to-end benchmark, audio generation on an Apple MacBook M4 dropped from 10 seconds to 4.3 seconds. On an Android device with Arm SME2, using one thread, the workload dropped from 14 seconds to 6.6 seconds. The next claim is the one product teams will notice: SME2 was more than 2x faster than NEON, and a single CPU core could generate 11 seconds of audio in under 8 seconds. That is a claim that near-real-time mobile generation may not always require a GPU-only or NPU-only path.
This is quieter than a new model launch, but it asks a more practical question for teams shipping AI features on real devices. Calling a cloud API can provide strong quality, but it brings cost, latency, privacy, and network dependency. Moving inference onto the device flips the tradeoff. The model may be too large, memory can run out, acceleration paths differ by device, and battery or heat can ruin the experience even when a benchmark looks good. AI product design is increasingly a negotiation between what model to run and where to run it. The Google and Arm example widens that negotiation at the CPU layer.
Why the CPU is back in the conversation
When people talk about on-device AI, the first component that comes to mind is usually the NPU. Apple Neural Engine, Qualcomm Hexagon NPU, Google Tensor's TPU-family blocks, and MediaTek NPUs all position dedicated acceleration as the obvious path. GPUs remain important too. The hard part is that developers have to make model formats, delegates, drivers, operating systems, and device tiers behave predictably. In a commercial app, the fastest path is not always the most important path. The broadest and most reliable path can matter more.
That is where the CPU comes back in. CPUs exist on almost every target device, and operating systems and runtime teams have spent decades making them reliable. The weakness is that traditional CPU inference paths have been slow for matrix-heavy generative workloads. Arm's Scalable Matrix Extension 2, or SME2, is meant to narrow that gap. Arm describes SME2 as a matrix-compute extension inside Armv9 CPUs. Google's post frames it as integrating a dedicated matrix-compute unit into the CPU cluster. In practical terms, the CPU is not just a fallback anymore. It becomes another deployment target for matrix-heavy generation.
Google AI Edge is the other key actor. The LiteRT GitHub repository describes LiteRT as the successor to TensorFlow Lite for high-performance on-device ML and GenAI deployment. It lists Android, iOS, Linux, macOS, Windows, Web, and IoT as targets, and emphasizes acceleration, GenAI inference, and runtime-level deployment. In this case, LiteRT reaches KleidiAI microkernels through the XNNPACK delegate. Developers are not expected to write assembly or custom hardware code directly. The intended flow is to convert the PyTorch model, apply quantization, and let the runtime route execution into the best available CPU acceleration path.
Why Stable Audio Open Small is a useful test case
The workload here is text-to-audio. Stable Audio Open Small generates a stereo audio sample from a text prompt, and Google framed the demo around creating an 11-second stereo clip from a single prompt. This is an interesting test because audio generation has a harsher user-experience threshold than many chat use cases. A text answer can arrive a few seconds late and still feel usable. Audio generation produces binary media, and if latency is too high the creative loop breaks. If quality regresses, the user hears it immediately.
The model also exposes three common on-device deployment problems. First, diffusion-style generation performs repeated computation. Second, audio quality can degrade quickly when quantization is too aggressive. Third, a mobile app needs lower model footprint and lower peak memory. That is why the announcement does not just say that the entire pipeline was reduced to INT8. Google explicitly notes that naive quantization can severely damage audio quality, then focuses on the DiT submodule as a part of the model that can tolerate dynamic INT8 quantization.
This is where Model Explorer enters the story. Google's Model Explorer visualizes the graph and uses node-data overlays to show which operators are compute intensive and which layers are safer to quantize. According to the post, DiT transformer blocks showed low error when comparing FP32 with FP32 plus INT8, which made them good candidates for dynamic INT8 quantization. On-device optimization is not a compression recipe. It is a search for the parts of the model that can be reduced while preserving the output users care about.

Convert, Optimize, Deploy is the product strategy
Google organizes the workflow as Convert, Optimize, Deploy. That sounds like documentation, but it is also a platform strategy. Moving a research model into a production mobile app often burns time in format conversion, quantization, and runtime integration. Model cards and papers usually start from PyTorch. Mobile apps may need .tflite, Core ML, ONNX, or a vendor SDK format. Shape constraints, operator support, tokenizers, memory layout, and delegate compatibility then become the real work.
LiteRT-Torch is the bridge from PyTorch into the LiteRT ecosystem. AI Edge Quantizer handles compression. Model Explorer provides the visual layer for deciding whether an optimization damages the model. At runtime, LiteRT's CompiledModel API and the XNNPACK delegate handle device execution. On the Arm side, KleidiAI microkernels and SME2 bring the code closer to the hardware. The important part of the announcement is that these pieces are being presented as one developer experience rather than as unrelated low-level tools.
PyTorch Stable Audio Open Small
LiteRT-Torch conversion and AI Edge Quantizer
Model Explorer identifies quantization-safe layers
LiteRT + XNNPACK + KleidiAI
On-device audio generation on Arm SME2 CPUs
For developers, this changes the menu of choices. Until recently, many teams evaluating on-device generative AI started with a binary question: use a smaller model with lower quality, or send the request to the cloud. Now the product question also includes which submodules can be quantized, which runtime can select delegates across devices, and whether a CPU path can guarantee a minimum usable experience. For prompt-to-audio tools, voice effects, local sound design, short-form media creation, and privacy-sensitive personalization, cutting the cloud round trip can be valuable even if the device path is not the highest-quality path.
How to read the numbers
There are four headline numbers in the announcement: a 3x speedup for the DiT submodule, a 4x memory reduction for that submodule, MacBook M4 generation dropping from 10 seconds to 4.3 seconds, and Android SME2 single-thread generation dropping from 14 seconds to 6.6 seconds. Those claims sit beside two broader points: SME2 is more than 2x faster than NEON, and a single core can generate 11 seconds of audio in under 8 seconds.
These numbers should not be generalized too quickly. They come from one model, one audio-generation pipeline, and specific test-device conditions. They do not represent the whole Android ecosystem. SME2 support is also a gating factor. Older Arm devices and different SoCs may not see the same result. Multi-threading raises another set of questions around thermal throttling and battery drain. Real users may run the app while a browser, camera, background sync, notifications, and system services compete for resources.
The numbers still matter because they describe a deployment path, not just a possibility. Google and Arm did not simply run a research model as a demo. They connected conversion, quantization, visualization, runtime execution, microkernels, and instruction-set support. They also published charts, sample material, and a learning path. That does not mean a production team can drop the model into an app tomorrow. It does mean a team can start testing its own models and device matrix against the same kind of path.
LiteRT after TensorFlow Lite
The LiteRT name is best understood as a reorganization after TensorFlow Lite. TensorFlow Lite was one of the defining runtimes for mobile ML deployment. But the generative AI era adds requirements that image classification and object detection did not fully capture. LLMs, diffusion models, multimodal encoder-decoders, and audio generators have different memory patterns and operator shapes. Tokenizers, KV cache, quantization strategy, streaming output, and long-running inference all matter.
The LiteRT repository leads with high-performance ML and GenAI deployment on edge platforms. Its README emphasizes the Compiled Model API, automated accelerator selection, asynchronous execution, NPU runtime, GPU performance, and GenAI inference. That should not be read as a finished product promise for every workload, but the direction is clear. Google wants on-device AI to be a runtime product that spans model conversion through execution, rather than a single delegate or a legacy mobile inference layer.
For Arm, the same shift matters. Arm owns the foundation of the mobile CPU market, but AI marketing has spent years centering GPUs and NPUs. SME2 and KleidiAI are a message that CPUs can remain meaningful acceleration layers for generative workloads. More precisely, the claim is not that the CPU will be the fastest path in every case. It is that broad device coverage and a predictable fallback path can raise the baseline experience. The more generative AI becomes a mass-market feature, the more that baseline matters.
Cloud cost pressure and the return of local inference
The other reason on-device AI keeps returning is cost. When AI features are experimental, API calls can look small relative to the rest of the product. Once the feature becomes a core workflow, usage grows, and media generation or repeated local transformations enter the product, the economics change. Sending every prompt, intermediate state, and media output to the cloud creates latency and privacy concerns, but it also creates gross-margin pressure.
On-device inference is not free. It adds model optimization work, device QA, crash analysis, binary-size concerns, local storage pressure, battery regression testing, and a support matrix. But if a product can move a meaningful share of work onto the device, cloud inference can be reserved for higher-value or higher-quality jobs. A hybrid design might run drafts, previews, personal effects, offline fallbacks, or private redaction locally, then send final high-quality rendering or long jobs to the cloud. A stronger CPU path expands the design space for that kind of architecture.
The Stable Audio Open Small case is about audio generation, but the structure is broader. Similar decisions show up in local image editing, short-video preprocessing, voice transformation, meeting-note redaction, private document embeddings, and small action models. Not every workload fits the CPU. But as model partitioning and selective quantization get better, the boundary between local and cloud work becomes more flexible.
Questions builders should ask now
Teams evaluating on-device AI after this announcement should start by decomposing their own bottlenecks. Is the whole model slow, or is one submodule responsible? Is memory bandwidth the limit? Is operator support the blocker? Are tokenizer, pre-processing, or post-processing steps consuming the latency budget? The Google and Arm example isolates the DiT submodule. Treating the full model as one black box would make that optimization target harder to see.
The second question is quality regression. INT8 or FP16 can improve a benchmark while damaging user-facing quality. In audio, the failure mode may be noise, high-frequency artifacts, collapsed stereo imaging, or weaker prompt adherence. In text models, it may be hallucination, tool-call inaccuracy, or unstable output formatting. Google emphasizes Model Explorer's error overlays because performance alone is not enough for a production decision.
The third question is device policy. A recent Armv9-A CPU with SME2 support and an older device without it cannot always receive the same experience. Apps may need capability detection, model-variant selection, fallback latency planning, and user-facing mode choices. A product might say local generation is fast on this device, or recommend cloud mode on another. As AI quality becomes tied to device tier, runtime capability becomes part of UX.
The reaction is quiet, but the direction is clear
I did not find signs that this Google Developers Blog post triggered a large standalone Hacker News discussion. Developer curation sites such as daily.dev and TECH Dashboard summarized it as a case of on-device audio generation and CPU inference optimization. The muted reaction makes sense. This is not a consumer-product launch; it is runtime engineering. But those engineering posts often become the foundation for later product shifts.
Arm had already published 2025 material on running Stable Audio Open Small on Arm CPUs with KleidiAI, including a learning path and sample repository. The Google post brings that work into the Google AI Edge story and gives it a broader Android and edge-developer frame. In other words, the news is not just a one-off demo. It is that a route into an official runtime stack is forming. When LiteRT, XNNPACK, KleidiAI, and SME2 line up, developers can test their own models against a supported path instead of copying a vendor blog by hand.
The risks that remain
The largest risk is generalization. An optimization that works well for Stable Audio Open Small may not produce the same ratio on another audio model, an LLM, a vision-language model, or an image/video diffusion model. Architecture, layer distribution, activation ranges, and operator support all differ. LLMs add attention, KV cache, memory bandwidth, and long-context behavior. Image and video diffusion shift the compute and memory profile again.
The second risk is licensing and release policy. Stable Audio Open Small is publicly available, but product teams still need to verify the license terms that apply to their use case. Generated audio also brings copyright and training-data questions. Running the model on-device does not remove responsibility for outputs. It may even reduce centralized moderation or logging, which means abuse detection and safety design need to move deeper into the app.
The third risk is battery and thermals. A latency benchmark does not show what happens when a user generates audio many times in a day, how much performance drops after thermal throttling, or what restrictions the operating system applies in background states. On-device AI is attractive because of privacy and latency, but power management and expectation management are just as important.
The layer below the model war
For the last few years, AI news has been dominated by larger models, longer context windows, and higher benchmark scores. That race continues. But product deployment raises a different set of questions. Where does the model run? Where does user data go? Who pays for inference? What happens when the network drops? Can older devices still use the feature? Can newer devices receive a visibly better experience?
Google and Arm's answer is to make the deployment path wider: not everything has to go to the cloud, and not everything has to depend on a dedicated NPU. CPU runtimes and quantization tools can become part of the generative AI product stack. This is still one audio-generation workload. But the numbers are specific, the tooling path is public, and the work fits Google's broader LiteRT strategy.
The next phase of on-device AI is unlikely to end with smaller model announcements. The more important questions will be which runtime makes conversion less painful, which quantizer makes quality regressions visible, which CPU/GPU/NPU delegate can be selected automatically, and which instruction set can provide a minimum user experience. Models remain the headline. The lower layers decide whether those models feel usable in the device already in a user's hand.
That is the real point of this announcement. Stable Audio Open Small did not merely get faster. Generative AI is becoming a product problem that spans model architecture, runtime behavior, and silicon features. "11 seconds of audio in under 8 seconds without a GPU" is a useful marker for that transition. Teams building AI apps now need to read runtime charts and memory graphs with the same care they give model cards.