Language Models Need Sleep, Fast Weights Target the Long-Context Bottleneck
Language Models Need Sleep proposes sleep-like fast weight consolidation, shifting long-agent memory from prompt compaction toward model execution schedules.
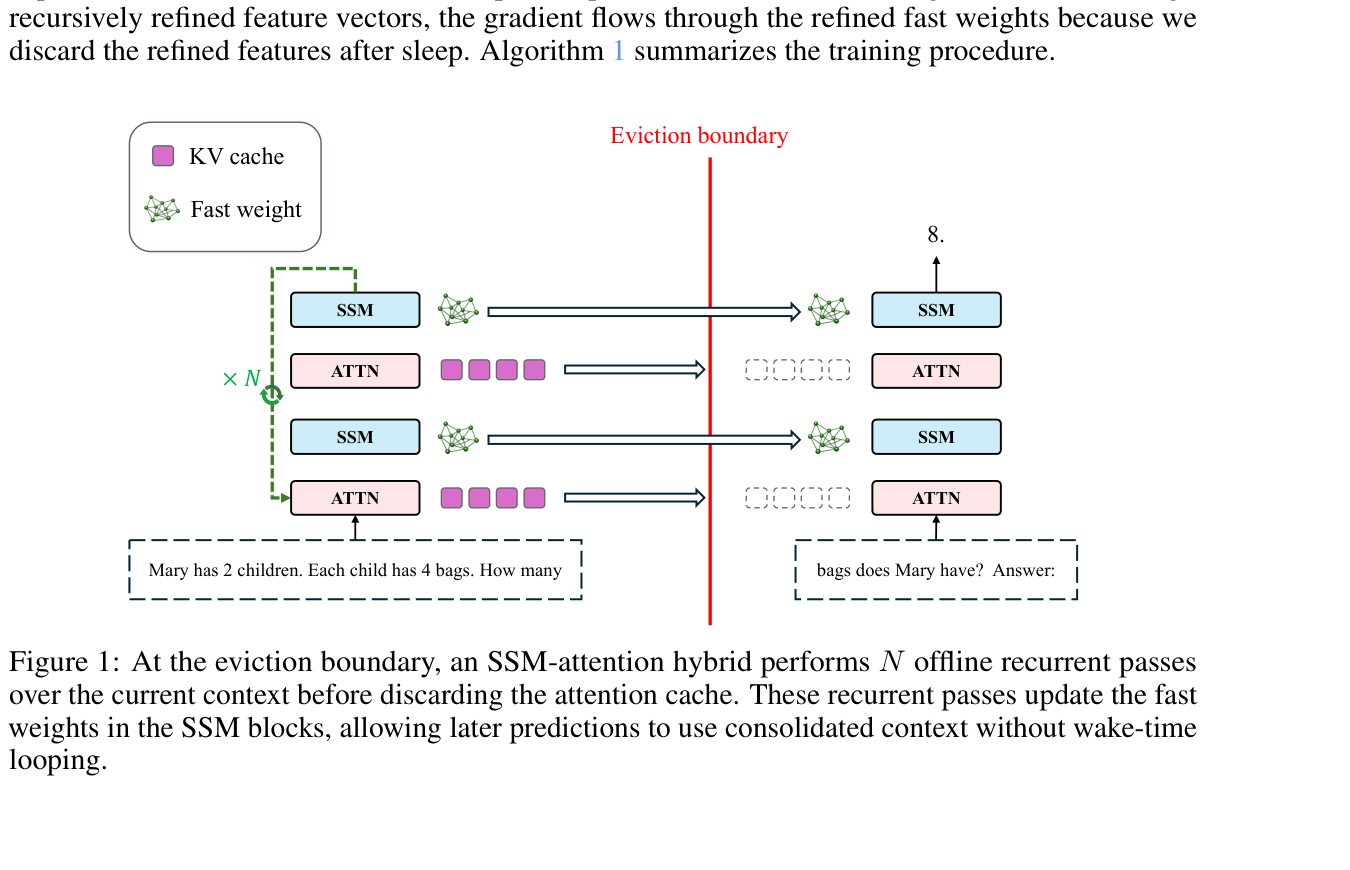
- What happened: Researchers from CMU and Maryland released Language Models Need Sleep on arXiv.
- Instead of keeping long context in the
KV cache, the method runs several offline passes before eviction and consolidates context intofast weights.
- Instead of keeping long context in the
- Why it matters: Agent memory starts to look less like a prompt-summary or RAG feature and more like a model scheduling problem.
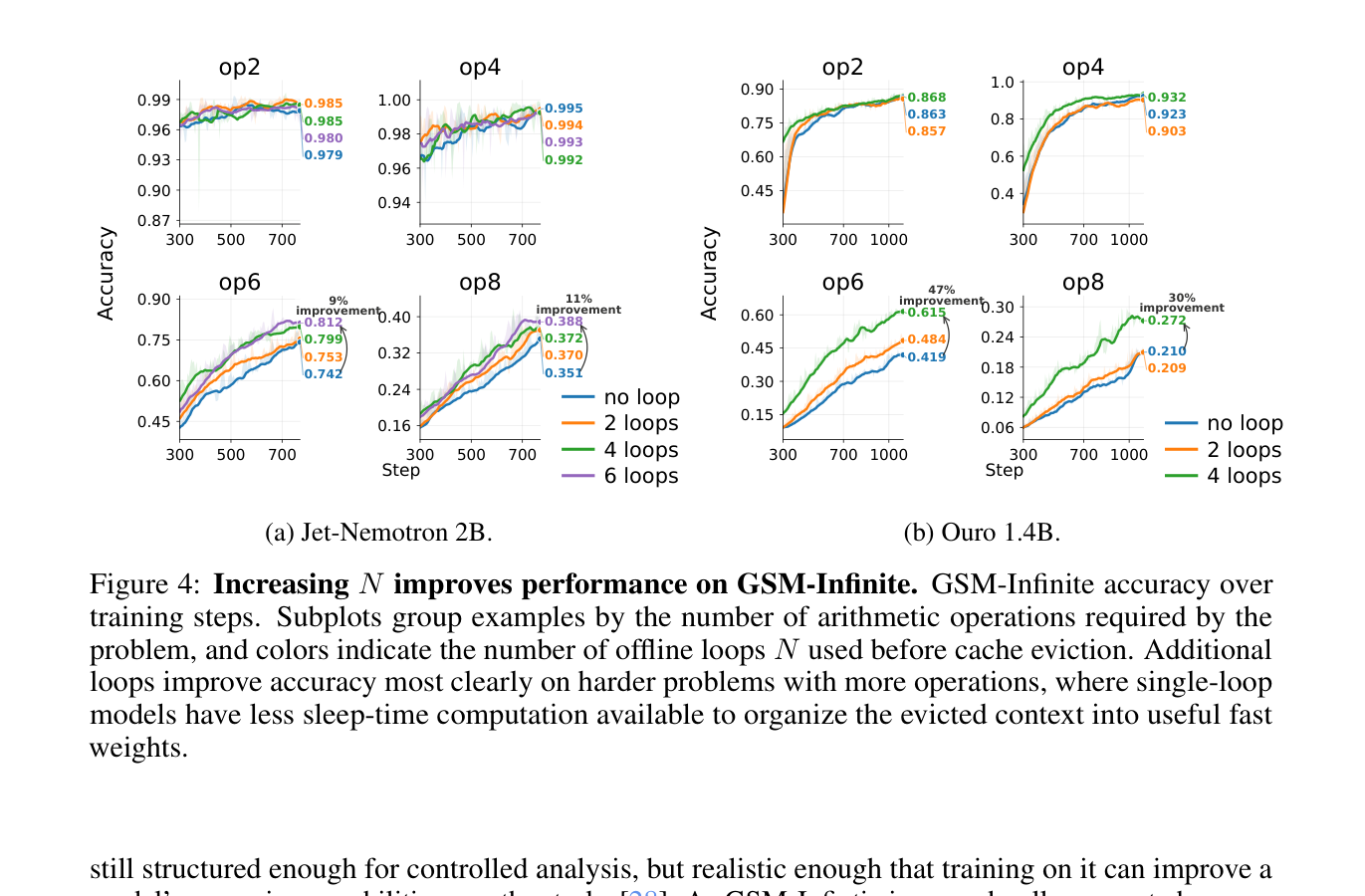
- Key number: On GSM-Infinite, Ouro 1.4B improved on 6-operation problems from
0.419accuracy to0.615.- The trade-off is real: recurrent sleep loops make training cost grow roughly linearly, and the evidence is still centered on controlled benchmarks.
- Watch: The useful engineering idea is offline recurrent memory consolidation, not the claim that models literally sleep.
The arXiv paper Language Models Need Sleep, posted on May 25, 2026, has a title that almost invites overreading. It sounds like another biological metaphor for AI. The actual technical problem is more practical: as an LLM works over a long session, the KV cache grows, attention gets expensive, and the system has to decide what to do with old context. For coding agents and research agents that run for hours, "keep everything active" quickly becomes a latency, memory, and reliability problem.
The paper's proposal is not that a model experiences sleep. It is that a model can run a consolidation phase when the context window is about to evict old tokens. During that phase, the model stops receiving new external input, repeatedly processes the recent context, updates SSM-style fast weights, and then clears the KV cache. Later, during prediction, the model uses a single forward pass. In other words, the additional compute is moved away from answer time and placed at the boundary where context would otherwise be discarded.
That shift is why the paper is worth watching. Most long-running agent products today combine context compaction, summary memory, vector retrieval, scratchpads, and ad hoc memory files. Those systems manage memory at the application layer. This paper asks a lower-level question: before context disappears from attention, can the model convert it into an internal state that remains useful after eviction? Long-term agent memory moves from a product feature into architecture and inference scheduling.
What the paper calls sleep
A standard Transformer stores past keys and values so future tokens can attend back to them. That works well, but the cost structure is uncomfortable. Attention compute grows sharply with context length, and cache memory grows linearly with the number of stored tokens. Hybrid models try to soften that constraint by mixing attention blocks with SSM or linear recurrent layers. The attention path handles recent context precisely. The recurrent path carries compressed state forward.
The paper goes one step deeper. A fixed-size memory is not the same as useful reasoning over old context. Saving some representation of past tokens does not guarantee that the model has organized the relationships it will need later. Once the cache is gone, the original text cannot be read again through attention. If old context matters, the model has to spend enough computation before eviction to turn that context into a usable internal state.
The authors call this sleep-like consolidation. Imagine a window of L tokens. A conventional hybrid model processes those tokens once, updates its recurrent state, and moves to the next window. In the proposed method, before the cache is discarded, the same context chunk is processed N additional times. Those repeated passes refine the SSM block's fast weights. After that, the attention cache is deleted. In the later prediction phase, the model does not get extra loops or extra chain-of-thought tokens.
The constraint matters. Many test-time compute methods make the model slower when the user is waiting for an answer. This paper moves compute into a different time slot. For a long-running agent, that is a natural operating model: do not make every user-facing response slower; instead, consolidate memory when the active context fills up and old tokens are about to leave the window.
| Approach | Where memory lives | When cost is paid | Practical meaning |
|---|---|---|---|
| Long KV cache | Active attention context | Every prediction and cache retention | Accurate access, but memory and latency grow. |
| Summary and RAG | Application summary or external store | Retrieval, reinsertion, and summary refresh | Easy to integrate, but separate from model-internal reasoning. |
| Sleep consolidation | Fast weights in SSM blocks | Offline loop before eviction | Compresses old context into internal state while preserving answer-time latency. |
The numbers point to organization, not storage alone
The paper starts with a simplified Rule 110 cellular automaton task. The model reads binary strings, evolves each string for t steps, and predicts the first bit. Because the experiment uses hard eviction in 24-token windows, the prediction phase cannot attend back to the original strings. A hybrid SSM-attention model can retain some information in fast weights, but as t grows, the problem requires more computational depth than simple storage.
The result follows the intuition. A vanilla GDN-attention hybrid model degrades as rollout depth increases. Adding two, three, or four offline loops before eviction improves performance in harder settings such as t = 32. The no-loop model remains near 10% accuracy after roughly five billion training tokens, while three-loop and four-loop versions move above 30%. The absolute number is not the main point. The important point is that context length and prediction-time compute stay fixed, while consolidation-time compute changes the outcome.
The Depo multi-hop retrieval task shows a similar pattern. Depo mixes directed cycles and asks the model to answer which node appears after k hops from a queried node. The cycle information arrives across several windows, and by the query-answer phase much of it has been evicted from cache. For easy 1-hop cases, sleep loops do not matter much. At 4-hop and higher, offline loops improve learning speed. At 16-hop, only the four-loop model starts making meaningful progress.
The most concrete numbers come from GSM-Infinite. This benchmark stretches GSM8K-style math problems with distractor tokens, combining long-context handling with multi-step reasoning. The authors test Jet-Nemotron 2B and Ouro 1.4B. For Jet-Nemotron 2B, 6-operation accuracy rises from 0.742 to 0.812, while 8-operation accuracy rises from 0.351 to 0.388. For Ouro 1.4B, the 6-operation case moves from 0.419 to 0.615, and the 8-operation case from 0.210 to 0.272.
These results complicate the simple answer that models only need larger context windows. A long window helps, but the model still has to decide what structure to preserve from that context. In agent workloads, old context includes logs, tool results, file diffs, test failures, user corrections, and intermediate plans. Keeping all of it verbatim is expensive. Compressing it poorly can be worse than forgetting. Sleep-like loops allocate a specific compute budget to the act of turning soon-to-be-evicted text into memory.
The signal for agent memory
Today's coding agents mostly rely on external memory strategies. When the conversation gets too long, they summarize the transcript, reread files, query a vector store, or write important decisions into a memory file. Those approaches are useful because they are inspectable and product-friendly. They also have failure modes. A bad summary can become a trusted false premise. Retrieval can miss the key fact. A memory file can preserve stale decisions long after they stopped being true.
The paper asks a different question: what if the model could perform part of that organization before the context leaves the active window? Imagine a long-running coding agent that has inspected hundreds of files, run tests, read stack traces, and revised its plan several times. Current systems usually leave that trail as text to be summarized or retrieved later. A sleep-style model would consolidate chunks of that experience into fast weight state at eviction boundaries, then use that state later without reattending to the original logs.
That is not a product feature yet. The paper is built around controlled synthetic tasks and modest-scale pretrained models. It does not prove that a frontier coding agent can safely and cost-effectively use session-specific fast weights in production. There are open questions around safety policy, user boundaries, state lifetime, multi-tenant inference, personalization, and data contamination. If fast weights persist within a session, prompt injection or bad tool output could potentially leave a longer-lived trace than ordinary context.
Still, the direction matters. Long-context marketing often focuses on how many tokens can fit in one prompt. This work pushes a different question: when old tokens must be discarded, what computation should happen before they go? As agents do longer jobs, that may become more important than raw context length.
The cost table is still heavy
Sleep-like consolidation is not free. The paper explicitly notes that increasing recurrent depth N makes training cost grow roughly linearly. There is also a dependency between windows: processing window j + 1 depends on finishing the sleep pass and fast-weight update for window j. That limits how much the sequence axis can be parallelized, giving up part of the conventional Transformer training advantage.
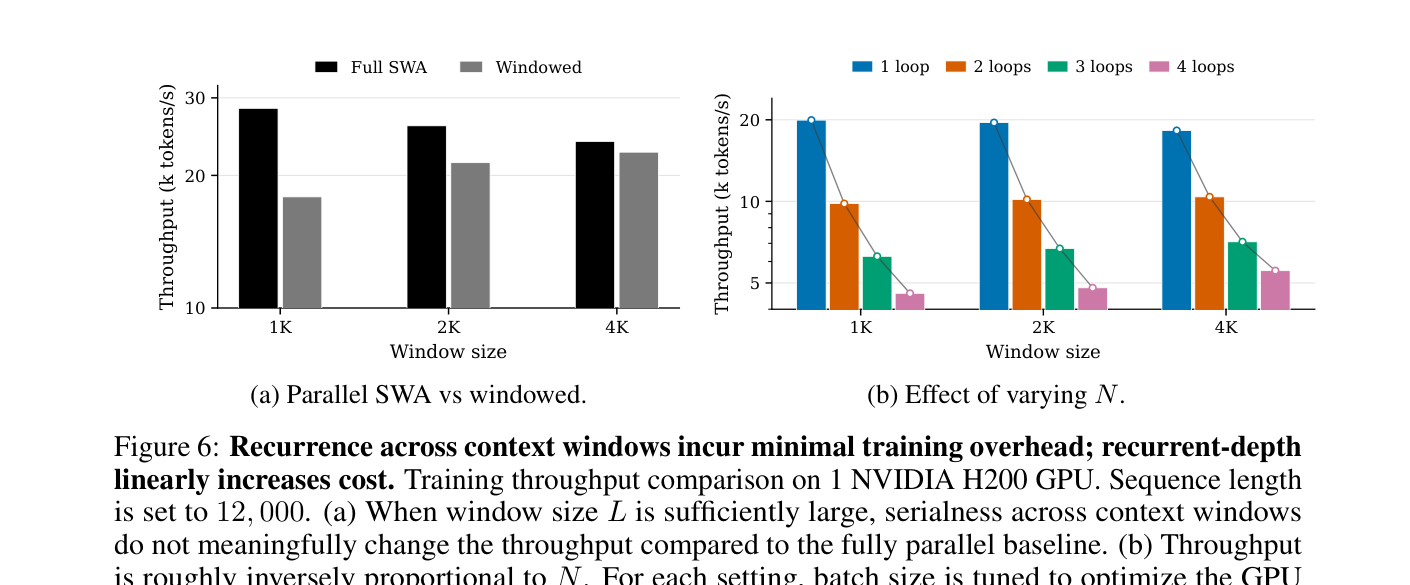
Figure 6 in the paper illustrates this trade-off. With sufficiently large windows, the sequential dependency between windows may not destroy GPU utilization by itself, but the extra loop count has an obvious cost. This makes the method look less like a universal setting for every request and more like a specialized option for workloads where long context must survive eviction and later reasoning depends on it.
For AI infrastructure teams, the pricing implication is interesting. Agent runtimes may eventually track not only cost per generated token, but also the cost of background memory consolidation. The user-facing response can stay fast, while the agent spends compute during idle or boundary moments to reorganize memory. At the product layer, we already see background agents, scheduled compaction, and memory indexing. This paper suggests a similar split may appear inside the model execution path.
The name is useful and risky
The Hacker News discussion around the paper was active and not uniformly positive. Some readers connected the work to long-context cost and KV cache pressure. Others objected to the word "sleep," arguing that the metaphor pulls in too much biological meaning. That critique is fair. The method is not modeling animal sleep. It is an engineering mechanism: repeated offline processing of recent context with fast-weight updates while no new external input is accepted.
The more precise label would be offline recurrent memory consolidation. The sleep analogy is understandable because the system moves recent information into a more durable representation while input is paused and later behavior benefits from that state. But the metaphor should not be allowed to expand the claim. The model is not learning arbitrary new facts in a magical way. It is consolidating session context into a bounded internal state.
For developers, the boundary is the important part. If a system uses per-session fast weights, the product has to define where that state lives, how long it lasts, who can inspect or reset it, and what data is allowed to affect it. This becomes especially sensitive for enterprise codebases, security logs, personal assistants, and multi-tenant serving systems. Memory is not only a capability. It is also a security and governance surface.
The next bottleneck is the form of memory
Language Models Need Sleep is early research, not a deployment recipe. The benchmarks are controlled, and the paper does not replace evaluation on real agent workloads. It would be premature to assume these exact gains transfer to large commercial LLM serving. But the direction is clear enough to matter: for long-running AI systems, memory is not simply a larger context window.
The design space is becoming more explicit. Some information should remain in active context. Some should be summarized. Some should be retrieved from an external store. Some might eventually be consolidated into model-internal state before the original context is evicted. Each choice has a cost profile, observability model, and safety boundary.
That is the real news value of the paper. The headline is not that LLMs sleep. The useful signal is that the next agent-memory bottleneck may be the form of memory itself. More tokens will keep helping, but models that work for a long time may also need a scheduled way to reorganize what they have already seen. Whether that becomes background compute in agent runtimes or a formal sleep phase inside model architecture is still open.