Safety Warnings Cannot Wait for the Cloud, the Conditions for a Running Agent
Google DeepMind Running Guide agent shows that physical-world agents depend as much on latency, on-device safety, and validation as model quality.

- What happened: Google DeepMind introduced Running Guide agent, an accessibility system for blind and low-vision runners.
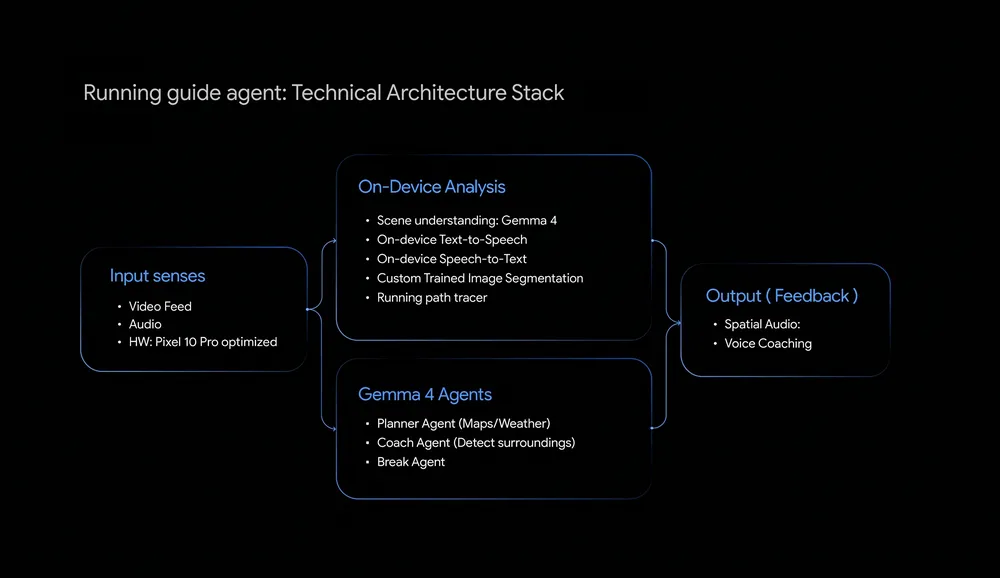
- It combines a chest-mounted
Pixel 10 Pro, on-device segmentation,Gemma 4 E4B, and separate Planner, Coach, and Break agents.
- It combines a chest-mounted
- Why it matters: Once agents leave the chat box and enter the physical world, the key capability is not only answer quality. It is latency and safety boundaries.
- Watch: Google describes testing with SG Enable and BLV runners, but broad independent validation across real environments has not been published.
- Rain, night running, background noise, camera shake, and route complexity are the conditions accessibility agents eventually have to survive.
Google DeepMind's Running Guide agent, announced on May 20, 2026, looks at first like a warm accessibility project. It is an AI running assistant designed to help blind and low-vision runners move without a human guide, a physical tether, or a marked line on the ground. For AI builders, though, the announcement asks a harder question: what kind of architecture does an agent need when it is no longer generating text on a screen, but helping a person make fast decisions in a moving physical environment?
The reason this question matters is straightforward. If a coding agent edits the wrong file, the change can often be reverted. If a support agent gives the wrong answer, the issue can be escalated or corrected. But if an obstacle appears in front of a runner and a STOP warning arrives late, the failure is no longer a line in a log. It becomes bodily risk. Running Guide agent is therefore less interesting as a model-performance announcement than as a signal about the operating conditions for physical-world agents.
According to Google, the system uses a chest-mounted Pixel 10 Pro to observe the path ahead and provide auditory feedback. The runner wears the phone on the body and hears directional ticking sounds, short spoken alerts, and pause or resume guidance through headphones or earbuds. Google says the work builds on Project Guideline, an earlier effort to help blind and low-vision runners follow a marked line using only a smartphone and headphones. The new step is a shift from following a line to understanding the environment around the runner.
Why Google split safety and reasoning
Google describes Running Guide agent as a hybrid, dual-path architecture. The first path is on-device segmentation. It runs offline on Pixel 10 custom silicon and handles immediate safety judgments. When the runner drifts from the safe path, approaches an urgent obstacle, or needs to stop, the system should not wait for a network call or a large model invocation. This layer emits STOP alerts, steering cues, and the directional ticking sound that helps the runner maintain orientation.
The second path uses Gemma 4 E4B for higher-level scene understanding. Google says this path processes multimodal image and text input to interpret terrain changes and unfamiliar obstacles. The important detail is that it does not analyze every frame. Smarter Frame Selection chooses frames with high information value, such as sudden terrain changes or newly appearing objects. Instead of making the model bigger and asking it to see everything, the system spends part of its engineering budget on deciding when the reasoning path should wake up.
That structure captures a reality many agent products still avoid. Dangerous actions should not be delegated to one model path. Fast, simple safety logic stays local. Slower interpretation runs separately when context is needed. This layered safety idea is familiar in robotics and autonomous systems, but it is notable to see it appear in a consumer accessibility agent. The central claim is not "we attached the strongest model." It is "we separated judgments that cannot be late from judgments that need richer context."
| Layer | Main role | Why it is separate |
|---|---|---|
| On-device segmentation | Immediate STOP, steering cue, path-deviation detection | Safety judgments cannot wait on the network or large-model latency. |
| Gemma 4 E4B | Obstacle, terrain-change, and scene-context understanding | Complex interpretation is useful, but processing every frame would be too slow. |
| Multi-agent layer | Planning, mid-run coaching, and break-state management | The running experience is split into role-specific state machines, not one prompt. |
Three agents divide the run
Google calls the system a collaborative multi-agent framework. That label can sound like current multi-agent marketing, but here the role split is concrete. Planner, Coach, and Break agents cover different time scales and risk levels.
The Planner agent works before the run begins. Google says it uses Gemma 4 function calling to fetch weather and Google Maps data, talk with the runner about workout goals, and calibrate a digital starting line. This could look like the setup screen of a fitness app, but for blind and low-vision runners, understanding the start point and route is part of the safety system. If planning is wrong, the agent has already made the run harder before the runner moves.
The Coach agent operates during the run. Google says it gives concise, telegraphic verbal alerts. The important design element is the triage hierarchy. DANGER means immediate avoidance. WARNING covers nearby runners or obstacles. NOTICE handles lower-urgency information such as an upcoming curve. A running audio interface cannot afford long explanations. The runner is breathing hard, the environment may be noisy, and response time is short. Output quality is therefore measured less by prose and more by priority, compression, and timing.
The Break agent handles pauses and resumes. Running is not one uninterrupted state. A person may stop, drink water, catch their breath, and start again. If the assistance system misses that state transition, it may issue alerts at the wrong time or misread the route when the runner resumes. Break agent makes that pause/resume state explicit. It is a small-sounding feature, but in real use, trust depends partly on whether the system knows what the user is currently doing.
This design fits a broader pattern in domain-specific agents. General reasoning matters, but workflow state often matters more as agents move into narrower, higher-stakes tasks. Coding agents divide planning, editing, testing, and review. Financial agents divide alert triage, case investigation, and human review. Running Guide agent applies the same principle to physical activity. The difference is the cost of failure: here, a state-management miss can become a safety problem.
What changed since Project Guideline
Running Guide agent is easier to understand next to Google's 2021 Project Guideline. That earlier research involved Google Research, Google Creative Lab, Google's Accessibility Team, and Guiding Eyes for the Blind. A smartphone camera watched a guideline on the ground, and audio signals told the runner when they drifted away from the center of the route. Google highlighted Guiding Eyes for the Blind CEO Thomas Panek completing an independent 5K in Central Park.
In 2023, Google released Project Guideline as an open-source computer-vision accessibility platform. The technical focus was already strongly on-device. The system used the runner's velocity vector to reduce camera-shake noise and accounted for irregular camera movement during running. Running Guide agent is therefore not a sudden agent demo. It is an agentic layer placed on top of several years of accessibility computer-vision work.
The difference is the shape of the route. Project Guideline was closer to following a marked line. Running Guide agent puts real-time environmental understanding in the foreground. Google frames this as a move from simple path following to advanced, real-time spatial reasoning. Read conservatively, that does not mean the model understands the whole world perfectly. It means the task has expanded from line detection in a constrained setting toward a more open setting with obstacles and terrain changes.
For developers, two lessons stand out. First, physical-world agents are rarely built end to end in one jump. A team starts with a narrower perception problem, then adds scene understanding, planning, and user-state handling. Second, even when the word agent appears, the foundation is still sensors, segmentation, latency, hardware, and user testing. The model may be the headline, but product trust often comes from the surrounding system.
The value of on-device AI becomes concrete
On-device AI is often described in terms of privacy or cost. Running Guide agent makes the value more direct: safety warnings cannot wait for the cloud. While a runner is moving, network quality is not guaranteed, and small latency differences can become large risk differences in the real world. That is why Google's offline segmentation path matters.
The choice to run Gemma 4 E4B on the device fits the same logic. Google says the model performs high-level scene understanding locally. The architecture is not "send camera video to a server and let a large model decide." Of course, model size, performance, battery life, heat, and frame-selection policy are all trade-offs. But in accessibility assistance, local inference is closer to a prerequisite than a product flourish.
This has implications for AI infrastructure teams. Agent architectures are increasingly unlikely to be described by one cloud LLM call. A fast local model, smaller vision model, event filter, function-calling layer, cloud service, device sensor, and policy layer may all share the job. Running Guide agent shows that pattern through a consumer accessibility scenario. Similar divisions may appear in factory safety assistants, logistics-floor agents, medical support devices, and in-vehicle personal assistants.
Smarter Frame Selection is especially worth watching. Sending every sensor input to a large model quickly breaks down on cost and latency. Instead, the system needs a layer that decides which frames are high risk or high information, and wakes the reasoning path only then. That is more than optimization. It is part of the agent runtime. The runtime decides what can be ignored and what must not be missed.
In accessibility AI, validation comes before features
Google says it is working with SG Enable, Singapore's disability and inclusion focal agency, to test the system with BLV runners. That matters because accessibility technology cannot be judged by a lab demo alone. Body condition, running experience, preferred audio cues, environmental noise, surface quality, weather, and cultural context all vary. A clean demo video is less important than how a diverse set of users experience failure over time.
At the same time, the public information has limits. Google's announcement explains the architecture and technical direction, but it does not publish independent long-term safety results, user counts, failure rates, performance by weather or lighting condition, or false-positive and false-negative rates for warnings. That is not a dismissal of the work. It is the standard needed to read the announcement accurately. Physical-world accessibility agents require a higher validation bar than ordinary app features.
If safety warnings fire too often, users may develop alert fatigue. If warnings are not conservative enough, dangerous situations may be missed. If directional cues are too complex, runners may not react in time. If they are too simple, the system may fail to distinguish important situations. Voice guidance has to compete with earbuds, traffic, wind, breathing, and other runners. Cameras are affected by rain, backlight, night conditions, shake, and sudden movement nearby. Those problems cannot be closed with a model benchmark alone.
That is why the core news is not "AI replaces human guides." A more accurate framing is that AI is being tested as an assistance layer that may expand independence under certain conditions. Human guides, safe infrastructure, accessibility communities, sports organizations, and city environments still matter. Running Guide agent is meaningful not because it removes all of that, but because it tries to expand the narrow but important part technology can handle.
The structural signal for developers
The word agent is now used so broadly that it can hide more than it reveals. Sometimes it means a chatbot with tool calls. Sometimes it means a software worker that runs for hours. Sometimes it means a system that uses sensors and acts in a physical environment. Running Guide agent narrows the term again. Here, an agent is a system that understands a goal, maintains state, uses sensors and tools, and changes behavior according to risk priority.
The first signal for builders is runtime separation. Safety-adjacent decisions move into a deterministic or small-model fast path, while richer interpretation goes to a slower path. The second signal is role separation. Planner, Coach, and Break make states and responsibilities explicit. The third signal is that the user is not just in the loop. The user is in motion. They are not looking at a screen and pressing a confirmation button. They are running and must react immediately. The UI and UX standard is completely different.
Viewed this way, Running Guide agent is both a Google accessibility project and a test case for ambient AI. Google also mentions an intelligent eyewear prototype. Glasses can provide a broader and more stable field of view, then stream data to a Pixel device and give the multimodal model better input. That points from phone-centered agents toward wearable-sensor agents.
But eyewear also raises privacy and social-acceptance questions. People and spaces around the runner may be captured by the camera, and the model interprets the surrounding environment. Even if data is processed on-device, trust requires clarity about what is stored, what is transmitted, and when records remain. Accessibility benefits can be substantial, but they do not remove the need for privacy and safety review.
The next unit of agent safety is milliseconds
Much of the recent AI news cycle centers on model scores, context windows, tool use, and benchmark rankings. Running Guide agent points at another axis. In the physical world, an agent's operating unit is not only the token. It is the frame, sensor latency, audio cue, battery, heat, network fallback, and user reaction time. As AI infrastructure moves into real environments, "what did the model generate?" becomes less important than "what did the system prevent within a few milliseconds?"
That shift indirectly matters even for coding agents. In higher-risk domains, the model's ability to explain itself is not enough. Systems need fast paths that stop risky behavior before a slower reasoning loop tries to justify it. File deletion, payment execution, medical advice, vehicle control, and industrial equipment all face the same design question. What should be blocked immediately by local policy? What should go through deeper reasoning? What should be escalated to a person? Running Guide agent places that question in the concrete scene of a runner on a route.
The value of this announcement is therefore not only that Google built an accessibility demo. It shows a minimum set of conditions for agents attached to the real world: an on-device safety path, a multimodal reasoning path, role-specific agent state, testing with the user community, and a conservative view of what remains unproven. Without those conditions, an agent can look intelligent and still be hard to trust.
Running Guide agent should not yet be read as a finished product with broad deployment and independent validation behind it. But the direction is clear. Agent safety does not end with prompt wording or model scores. It reaches down to which decisions must move out of the cloud, which alerts must fire within milliseconds, and which user states must not be lost while the person is moving. In front of a running human, AI has to speak briefly, stop faster, and behave more cautiously.