Copilot Memory Turns Agent Memory Into a Control Surface
GitHub Copilot Memory now separates deletion, repository controls, CLI state, and memory scope as coding agents become operational infrastructure.

- What happened: GitHub added deletion guidance, a repository off switch, CLI controls, and clearer scope labels to
Copilot Memory.- The changelog landed on May 26, 2026, and Copilot Memory remains in public preview.
- Why it matters: Long-term context for coding agents is moving from convenience feature to admin policy surface.
- Operational impact: Teams now need to separate repository facts, user preferences, CLI state, and the 28-day retention window.
- The repository off switch stops future use, but it does not automatically delete facts that were already stored.
GitHub Copilot is starting to ask a more explicit question: what is this coding agent allowed to remember? On May 26, 2026, GitHub said in its Changelog that Copilot Memory now has four additional controls in public preview. Copilot can guide users to the right place when they ask it to forget something. Repository admins can turn Memory off for a specific repository. Copilot CLI users can inspect and change memory state with /memory. The store_memory permission prompt now shows whether the proposed memory is a user-level preference or a repository-level fact.
At first glance, this looks like a product polish update. In the flow of a coding agent, it is more than that. Once an agent reads a repository, comments on pull requests, suggests commands in a terminal, or opens a PR from a cloud agent session, long-term context becomes both a productivity layer and a risk surface. A useful memory can remove repeated explanations. A bad memory can resurrect stale rules, reinforce assumptions the team no longer wants, or carry context further than the organization expected.
Recent devlery coverage of GitHub Copilot targeted model rules focused on who can use which model inside an organization. Copilot Memory sits on another axis. Model routing is a policy table for cost, capability, and risk. Memory scope is a policy table for what the agent can treat as durable context. As coding agents move from personal tools into shared development infrastructure, those two axes start to matter together.
Copilot Memory Has Two Different Kinds of Memory
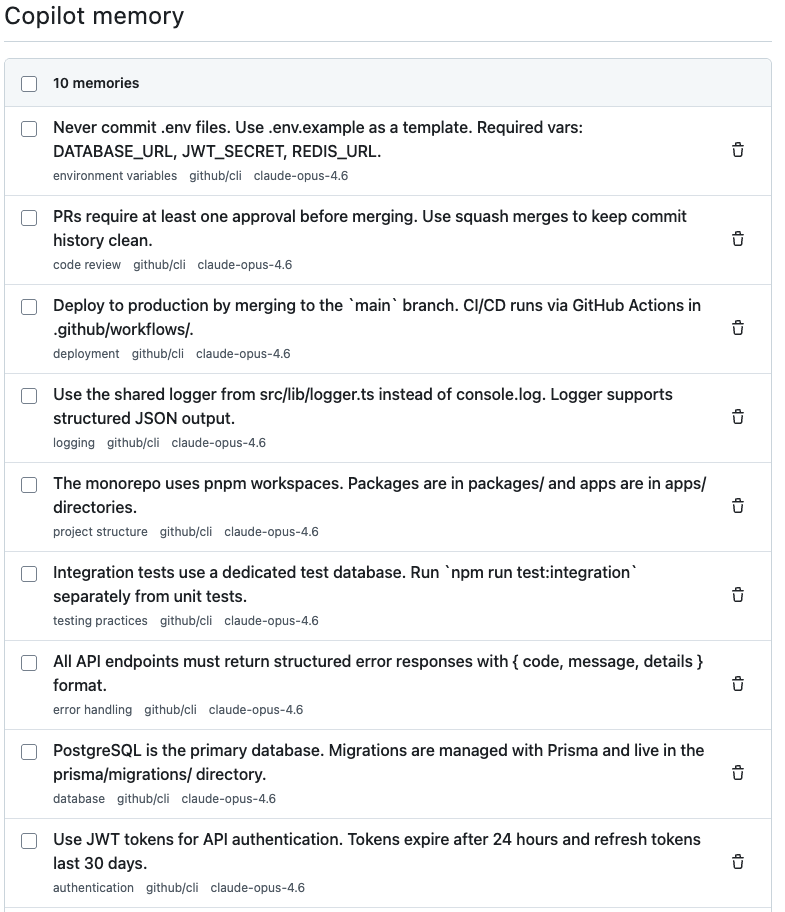
GitHub Docs describe Copilot Memory as a way for Copilot cloud agent, Copilot code review, and Copilot CLI to learn from a codebase and a user's preferences. The important point is that memory is not one undifferentiated store. GitHub distinguishes between repository-level facts and user-level preferences.
A repository-level fact is attached to a specific repository. It might describe the command the project uses for tests, a generated-code directory that should not be edited manually, or an internal convention that contributors follow. This kind of memory can affect multiple people who work on the same repository. That is why a repository owner needs review, deletion, and disable controls.
A user-level preference is attached to an individual. It can capture how a developer likes answers to be structured, how much detail they want, or which workflow they prefer. GitHub Docs say Copilot Memory is on by default for individual Copilot Pro and Pro+ users. For enterprise and organization-managed Copilot subscriptions, it is off by default and must be enabled in enterprise or organization settings. If a user receives Copilot through multiple organizations, the most restrictive setting applies.
That distinction matters because the value and risk of memory change with scope. A personal preference can make one developer faster. A repository fact can change how an agent behaves for a whole team. If a temporary guess from one developer becomes a repository-level fact, other contributors may inherit it. If a real team rule is stored only as a personal preference, the organization never gets a consistent agent behavior. That is why the updated store_memory prompt is not just a UI nicety. It tells the user whether they are approving a private preference or a shared repository fact.
Asking an Agent to Forget Is Not the Same as Deleting Data
"Forget this" is an intuitive command in an AI product. Operationally, it is ambiguous. Which memory should be removed? Is it a user-level preference, a repository-level fact, a piece of temporary chat context, or a durable item stored outside the current conversation? GitHub's update acknowledges that difference. When a user asks Copilot to forget something, Copilot can now point them to the right deletion location and down-vote the relevant memory where voting is available.
This is the kind of detail that shows why agent governance cannot be solved by UX copy alone. A user can express intent in natural language. A long-term memory system still has storage locations, owners, deletion rights, and retention policies. If teams assume one natural-language request deletes every layer instantly, audit and recovery become unclear. If users express a deletion intent and cannot find the actual deletion path, trust erodes.
GitHub Docs say repository facts and user preferences can be deleted directly. Repository owners can review and remove repository memories from repository settings. Individual users can view user-level preferences in personal Copilot settings. GitHub also says both repository facts and user preferences are automatically deleted after 28 days. That retention window is meant to reduce the chance that old context keeps shaping future agent behavior.
The 28-day window is useful, but it is not a full answer. Twenty-eight days is long enough for a bad fact to affect many repeated tasks. If an agent stores an inaccurate repository fact, and that fact keeps influencing code review or CLI suggestions, the team can see almost a month of quality issues. Fast-moving repositories have another problem: a memory can become stale even while it is still inside the retention window. GitHub says memory is validated before use, but each organization still needs a review and deletion routine that matches its own pace of change and risk tolerance.
What the Repository Off Switch Actually Does
The most operationally important part of the update is the repository-level off switch. GitHub says repository admins can disable Copilot Memory in the repository's existing Copilot feature controls. After that, repository-level facts are no longer stored or read for that repository. Existing facts are not automatically deleted. User-level preferences are not affected.
That short distinction matters. The off switch is a disable control, not a data deletion control. Turning Memory off for a repository stops future repository-level memory use. It does not wipe facts that were already stored. If a security team or platform team treats "off" as equivalent to "deleted," the operating procedure is incomplete. Disable, inspect, delete, and re-enable are separate actions.
The pattern is familiar from other developer infrastructure. Disabling a CI secret is not the same as deleting the secret value. Turning off a feature flag is not the same as deleting state in a database. Copilot Memory needs the same operational discipline once it becomes part of the development system. AI memory is especially sensitive because a short text fragment that a human never reviewed carefully can shape an agent's next action.
Repository-level control also maps better to real organizational risk than a single global switch. Some repositories benefit from agent memory. A large monorepo, a legacy system with unusual test commands, or a project with specific deployment conventions can save time if the agent remembers how the codebase works. Other repositories may need less memory: customer-specific code, regulated workloads, security research, short-lived migration repositories, or repositories where sensitive operational details are frequent. Enterprise and organization-wide policy is necessary, but it is often too coarse. The repository switch is closer to the unit where risk actually lives.
| Scope | Who manages it | What this update changes |
|---|---|---|
| User preference | Individual user | View and delete in personal settings, bounded by organization policy |
| Repository fact | Repository owner or admin | Review, delete, and disable from repository settings |
| CLI state | CLI user and organization policy | /memory on, /memory off, and /memory show persist beyond one session |
| Retention | GitHub Memory policy | Repository facts and user preferences are automatically deleted after 28 days |
Memory Controls Have Reached the CLI
The CLI part of the update is also worth watching. GitHub says Copilot CLI now supports /memory on, /memory off, and /memory show, and the choice persists across sessions. The terminal is a more direct execution surface than an editor chat panel. It is where an agent sees local project state, suggests commands, and interacts with the developer's environment. Once memory participates in that surface, users need a quick way to see whether it is enabled.
CLI memory controls sit between developer experience and organizational governance. A developer wants to know whether the current session is using memory. An organization wants enterprise AI controls to enforce what is allowed. If those signals disagree, users get confused. In the Reddit thread under the update, one early commenter said the CLI appeared to show Memory as enabled even though enterprise AI controls disabled it for the organization. That is a small sample and not an officially confirmed bug, so it should not be overstated. But the feedback points to the core risk: the state users see and the state admins intend must match.
AI coding CLIs are taking on more work. They no longer just answer questions. They explore repositories, write plans, edit code, run tests, and prepare pull requests. In that workflow, memory state becomes debugging information. If an agent consistently chooses a command, avoids a directory, or applies a convention, the team needs to know whether memory influenced that behavior. A command like /memory show is not only a convenience feature. It is a small unit of agent observability.
Long-Term Memory Is a Productivity Feature and a Security Surface
The benefit of Copilot Memory is straightforward. Developers do not want to explain the same project background on every task. If an agent can remember test commands, style expectations, disallowed patterns, preferred libraries, or naming conventions, its success rate can improve. For cloud agents and code review, persistent repository context can also reduce cost and time. Relearning a codebase from scratch on every task is inefficient.
The risk is equally clear. Prompt injection discussions often focus on external documents, issues, READMEs, or web pages that push a model toward bad instructions. Memory lengthens that problem. A wrong or malicious fact can persist across sessions. A temporary instruction from an experimental branch, a stale migration note, or an adversarial pull request description should not become durable agent context.
That is why GitHub's scope label on the store_memory permission prompt is practical. A user approving memory needs to know whether the item affects only them or can affect everyone working in the repository. The same sentence changes meaning depending on scope. "Always run tests with pnpm" might be a personal preference, or it might be a repository fact. If it is the latter, repository owners need visibility and control.
Staleness is another risk. GitHub's 28-day deletion policy helps limit old context, but real projects may need shorter or more explicit memory lifetimes. During a large migration, a dependency switch, a build-system rewrite, or a secret rotation, the useful life of a rule can be far shorter than 28 days. On the other side, a stable repository convention might be useful for longer than 28 days. That tension suggests where memory products may go next: more granular retention, pinned memories, audit trails, or stronger review flows for shared repository facts.
GitHub Has an Advantage Because It Already Owns Repository Permissions
Copilot Memory is not just a model feature. A better model does not automatically solve it. Useful memory for coding agents has to connect repository permissions, organization policy, user settings, CLI state, code review, and cloud agent workflows. GitHub has an advantage because those primitives already exist inside the platform.
Agent memory needs to live close to code. Repository owners should be able to see it. Repository settings should hold the control surface. Organization policy should constrain it. GitHub does not need to invent that permission model from scratch. It can attach memory controls near branch protection, Actions secrets, code owners, Copilot policies, and enterprise AI controls. That is difficult for standalone AI coding tools to replicate cleanly.
The advantage also creates responsibility. Once a memory is presented as a repository fact, developers may treat it as a fact managed by GitHub, not merely a suggestion from a chat session. The UI needs to make scope, deletion, expiration, and admin override obvious. If a bad memory causes an agent to make repeated poor suggestions, users will not only blame the model. They will blame the memory management experience.
This is one reason memory controls may become a competitive layer in coding agents. Claude Code, Cursor, OpenAI Codex, Gemini CLI, and other agentic tools all need some way to carry durable context forward. But durable context is hard to make trustworthy without the surrounding authorization, audit, and team workflow layers. The memory store itself is not the product. The management model around it is the product.
What Teams Should Check Now
Teams should first confirm where Copilot Memory is enabled. Individual Pro and Pro+ users may have it on by default. Enterprise and organization-managed subscriptions may have it off by default unless an admin enabled it. Users who receive Copilot through multiple organizations should remember that the most restrictive setting applies. It is also worth checking whether CLI state, personal settings, repository settings, and organization policy all tell the same story.
The second question is repository classification. Not every repository needs the same memory posture. Internal tools, customer-specific repositories, security-sensitive projects, open source repositories, and fast-moving migration branches have different risk profiles. A repository-level off switch is a first step toward expressing those differences. The operating procedure should explicitly say that turning memory off does not delete existing facts.
The third question is review cadence. Repository owners need a lightweight routine for reviewing stored facts and deleting stale or incorrect items. This becomes especially important when investigating agent failures. A team should be able to separate model weakness, tool permission problems, flaky test environments, stale memory, and memory contamination. Without that separation, agent quality work becomes guesswork.
The fourth question is developer training. Users need to read the store_memory permission prompt and understand the scope they are approving. A private preference should not accidentally become a repository fact. A real team convention should not stay trapped as one developer's personal setting. CLI users should also know to run /memory show when an agent behaves as if it is following an old rule.
Conclusion
This Copilot Memory update is not a flashy model launch. It is not a new agent demo. But these quieter changes may matter longer inside real engineering organizations. A useful coding agent needs memory. A serious organization needs to know what is remembered, who can delete it, where it applies, and when it expires.
GitHub's deletion guidance, repository off switch, CLI /memory command, scope labels, and 28-day retention policy all point in the same direction. Long-term memory is no longer just a chat UX feature. In coding agent operations, memory is becoming a control surface alongside models, permissions, cost, and audit.
For the last few months, AI coding news has focused on stronger models, faster agents, and larger context windows. The next question is different: as agents work longer, what should they be allowed to remember longer? GitHub Copilot Memory's latest update is an early answer. It does not push toward invisible automation. It pushes toward visible scope, deletion paths, off switches, CLI state, and expiration windows.
Sources
- GitHub Changelog: Copilot Memory has more controls for deletion, scope, and the Copilot CLI
- GitHub Docs: Managing and curating Copilot Memory
- GitHub Changelog: Agentic memory for GitHub Copilot is in public preview
- GitHub Changelog: Copilot Memory now on by default for Pro and Pro+ users in public preview
- GitHub Docs: About GitHub Copilot CLI