LLM 추론 90% 병목, CUDA 13.3의 새 튜닝 레버
NVIDIA CUDA 13.3은 CompileIQ와 CUDA Python 1.0으로 LLM 추론 비용의 낮은 계층인 커널과 컴파일러 병목을 겨냥합니다.

- 무슨 일: NVIDIA가
CUDA 13.3과CompileIQ를 공개했습니다.- 공식 발표일은 2026년 5월 26일이며, CUDA Tile C++, CUDA Python 1.0, C++23 지원도 함께 묶였습니다.
- 핵심 숫자: NVIDIA는 GEMM과 attention이 LLM 추론 compute의 90% 이상을 차지한다고 설명합니다.
- CompileIQ는 이미 최적화된 Triton attention과 CUTLASS GEMM kernel에서 최대 15% speedup을 제시했습니다.
- 의미: 모델 가격 경쟁 아래에서 compiler heuristic과 Python GPU runtime이 새 원가표가 됩니다.
- 주의점: 자동 마법은 아닙니다. 좋은 benchmark와 이미 다듬어진 kernel이 있어야 마지막 성능 여지를 찾습니다.
NVIDIA가 CUDA 13.3을 공개했습니다. 표면적으로 보면 GPU 개발자에게 익숙한 툴킷 업데이트입니다. CUDA Tile C++ 지원, CUDA Python 1.0, C++23 지원, CCCL 3.3, cuBLAS와 cuSPARSE와 cuSOLVER 개선이 한꺼번에 들어왔습니다. 하지만 AI 인프라 관점에서 더 날카로운 부분은 따로 있습니다. NVIDIA가 LLM 추론의 남은 병목을 "컴파일러가 고르는 내부 선택지"로 끌고 내려왔다는 점입니다.
이번 발표의 핵심 단어는 CompileIQ입니다. NVIDIA는 이를 GPU kernel을 위한 compiler auto-tuning framework라고 설명합니다. 일반적인 compiler는 수많은 workload에 대체로 잘 맞는 기본 heuristic을 적용합니다. register allocation, instruction scheduling, loop transformation 같은 선택은 특정 kernel 하나만을 위해 매번 새로 최적화되지 않습니다. CompileIQ는 이 가정을 뒤집습니다. 사용자가 benchmark objective를 정의하면, evolutionary algorithm과 genetic algorithm이 compiler configuration을 탐색하고, 가장 좋은 설정을 advanced controls file로 남깁니다.
이것이 왜 지금 AI 뉴스가 되는지는 숫자에서 드러납니다. NVIDIA는 GEMM과 attention이 LLM inference compute의 90% 이상을 차지한다고 설명합니다. 그리고 CompileIQ가 이미 최적화된 Triton attention과 CUTLASS GEMM kernel에서 최대 15% speedup을 냈다고 말합니다. 15%라는 숫자는 모델 벤치마크 뉴스에서는 작아 보일 수 있습니다. 그러나 대규모 inference cluster에서는 다릅니다. 같은 GPU에서 더 많은 token을 처리하거나, 같은 traffic을 더 적은 GPU로 감당하거나, latency budget 안에서 더 큰 batch를 유지할 수 있기 때문입니다.
모델 가격표 아래의 층
2026년 AI 업계는 모델 가격표를 자주 봅니다. 입력 token 가격, 출력 token 가격, batch discount, cache hit rate, context window, reasoning effort가 제품 선택 기준이 됩니다. 하지만 실제 원가표는 그보다 아래에 있습니다. 모델이 attention을 계산하는 kernel, MLP block의 GEMM, KV cache를 옮기는 memory path, kernel launch overhead, compiler가 만든 machine code가 모두 inference cost를 결정합니다.
이미 많은 팀은 쉽게 잡히는 최적화를 끝냈습니다. quantization을 적용하고, batching을 조정하고, FlashAttention 계열 kernel을 쓰고, tensor parallelism과 pipeline parallelism을 나눕니다. profiler를 보면 특정 kernel 몇 개가 대부분의 시간을 가져갑니다. 그다음에는 "더 좋은 kernel을 쓰자"와 "더 좋은 compiler codegen을 찾자" 사이의 싸움이 됩니다.
CompileIQ가 들어가는 자리는 바로 여기입니다. NVIDIA의 CompileIQ deep dive는 compiler 내부 parameter가 public flag로 노출되지 않는다고 설명합니다. 개발자는 objective function을 씁니다. 예를 들어 특정 candidate compiler configuration으로 kernel을 compile하고, benchmark를 돌리고, runtime 또는 power 같은 점수를 반환합니다. CompileIQ는 search space를 돌며 더 나은 configuration을 찾습니다. 결과는 ACF 파일로 저장되고 compiler는 --apply-controls로 이 파일을 적용합니다.
이 설계가 흥미로운 이유는 성능 최적화가 코드 바깥으로 나온다는 점입니다. 지금까지 AI inference optimization은 kernel code, framework graph, runtime scheduler, hardware topology의 문제로 보였습니다. CUDA 13.3은 여기에 "compiler heuristic 자체도 versioned artifact가 될 수 있다"는 층을 추가합니다. 팀은 kernel source 옆에 ACF를 commit하고, 특정 workload에서 검증된 compiler 선택을 배포 pipeline에 넣을 수 있습니다.
CompileIQ는 무엇을 자동화하나
CompileIQ의 메시지를 "AI가 compiler를 대신 튜닝한다"로만 요약하면 너무 넓습니다. 실제로는 더 제한적이고 그래서 더 실용적입니다. NVIDIA는 CompileIQ가 production workload의 GPU 및 CPU target에서 검증됐고, TritonBench와 Helion kernel에서 최대 15% 개선 사례를 제시한다고 설명합니다. 동시에 "poorly-written code를 자동으로 고성능 코드로 바꾸는 마법은 아니다"라고 선을 긋습니다.
즉 CompileIQ는 낮은 품질의 kernel을 구원하는 도구가 아닙니다. 이미 상당히 잘 최적화된 kernel에서 default compiler heuristic이 놓친 조합을 찾는 도구입니다. 이 차이는 중요합니다. 많은 개발팀은 compiler flag 몇 개를 바꾸는 정도의 튜닝은 해볼 수 있습니다. 하지만 내부 compiler parameter 공간을 세대별로 탐색하고, benchmark 결과를 기준으로 candidate를 선택하고, mutation과 crossover를 반복하는 일은 일반적인 inference team의 일상 workflow가 아니었습니다.
NVIDIA는 이 탐색 결과를 ACF로 남긴다고 설명합니다. 이 파일은 code review와 version control의 대상이 될 수 있습니다. inference platform 팀에게 이것은 꽤 큰 변화입니다. 성능 튜닝의 결과가 "누군가의 local 실험"에서 끝나는 것이 아니라, 재현 가능한 배포 artifact가 됩니다. 모델 weight, kernel source, container image, driver version, CUDA version처럼 compiler tuning 결과도 운영 계약의 일부가 될 수 있습니다.
다만 위험도 있습니다. benchmark가 실제 traffic을 대표하지 못하면 CompileIQ는 잘못된 목표를 최적화할 수 있습니다. 가장 빠른 runtime만 보면 power consumption이나 compile time, binary size, 안정성, tail latency가 악화될 수 있습니다. NVIDIA가 multi-objective optimization과 Pareto frontier를 강조하는 이유도 여기에 있습니다. 대규모 AI inference에서는 "가장 빠른 1회 실행"보다 "전력, latency, throughput, 배포 재현성의 균형"이 더 중요합니다.
CUDA Python 1.0의 조용한 의미
CompileIQ가 성능 hotspot을 겨냥한다면, CUDA Python 1.0은 운영 표면을 겨냥합니다. NVIDIA는 CUDA Python 1.0을 내며 semantic versioning을 약속했습니다. breaking API change는 major version에서만 발생하고, minor release는 기능 추가, patch release는 bug fix라는 계약입니다. AI 개발자에게 이것은 단순한 버전 숫자가 아닙니다. Python이 GPU serving과 실험, data pipeline의 중심 언어인 상황에서 CUDA runtime을 안정적으로 제어할 수 있는 API surface가 생긴다는 뜻입니다.
공식 발표는 cuda.core가 device, stream, program, linker, memory resource, graph를 다루는 Pythonic interface를 제공한다고 설명합니다. 여기에 green contexts, CUDA checkpointing, IPC가 추가됐습니다. 각각은 AI serving에서 꽤 직접적인 문제와 연결됩니다.
green context는 GPU의 SM을 분리된 partition으로 나누고, 각 partition에 context와 stream을 줄 수 있습니다. 이는 latency-sensitive kernel을 긴 throughput kernel로부터 보호하는 데 쓰일 수 있습니다. inference serving에서 짧은 interactive 요청과 긴 batch job이 같은 GPU를 공유할 때 이런 격리는 tail latency를 줄이는 단서가 됩니다.
process checkpointing은 실행 중인 CUDA process의 device allocation, stream, context 같은 상태를 snapshot하고 나중에 restore하는 방향입니다. NVIDIA는 Linux에서만 가능하다고 설명합니다. 이것은 shared cluster의 preemption, migration, long job fault tolerance, inference worker warm-start 같은 운영 시나리오와 맞닿아 있습니다. 지금 AI infra의 큰 비용 중 하나는 GPU process를 다시 띄우고 모델과 cache를 warm up하는 시간입니다. checkpoint/restore가 안정적으로 성숙하면 GPU worker 운영 방식도 달라질 수 있습니다.
IPC도 중요합니다. host memory를 거치지 않고 Python process 사이에서 GPU memory를 공유할 수 있다면, multi-process serving이나 producer/consumer pipeline의 copy overhead를 줄일 수 있습니다. 이런 변화는 모델 아키텍처만큼 화려하지 않지만, 실제 제품 latency와 GPU utilization에는 직접적인 영향을 줍니다.
Python과 C++ 사이의 경계가 얇아집니다
CUDA 13.3은 Python만 밀지 않습니다. CUDA Tile programming in C++도 들어왔습니다. CUDA Tile은 parallelism, memory movement, asynchrony 같은 낮은 수준의 세부를 추상화해 tile 기반 kernel을 더 높은 수준에서 작성하게 합니다. 이전 CUDA Tile 흐름이 제한된 환경과 특정 backend 중심이었다면, C++ 지원은 기존 CUDA C++ codebase와 개발자 기반을 더 넓게 끌어들이는 변화입니다.
AI kernel 개발은 이미 Python과 C++ 사이를 오갑니다. 연구자는 Python에서 PyTorch, JAX, CuPy, Triton으로 실험합니다. 성능이 필요하면 CUDA C++, CUTLASS, custom extension으로 내려갑니다. 문제는 이 경계가 자주 깨진다는 점입니다. tensor는 Python framework 안에 있고, 고성능 kernel은 pointer와 stride와 shared memory view를 직접 다룹니다. 이때 shape, stride, dtype, ownership, lifetime이 어긋나면 성능과 안정성이 함께 흔들립니다.
CCCL 3.3의 DLPack/mdspan interoperability는 이 경계를 조금 더 정리합니다. 공식 발표는 PyTorch, JAX, CuPy 같은 framework tensor를 cuda::std::mdspan view로 바꾸고, 다시 DLPack으로 넘길 수 있다고 설명합니다. C++ kernel 안에서도 multi-dimensional shared memory view를 만들 수 있어 indexing을 더 명확하게 유지할 수 있습니다. 이런 변화는 "AI 연구 코드에서 production kernel로 내려가는 비용"을 낮춥니다.
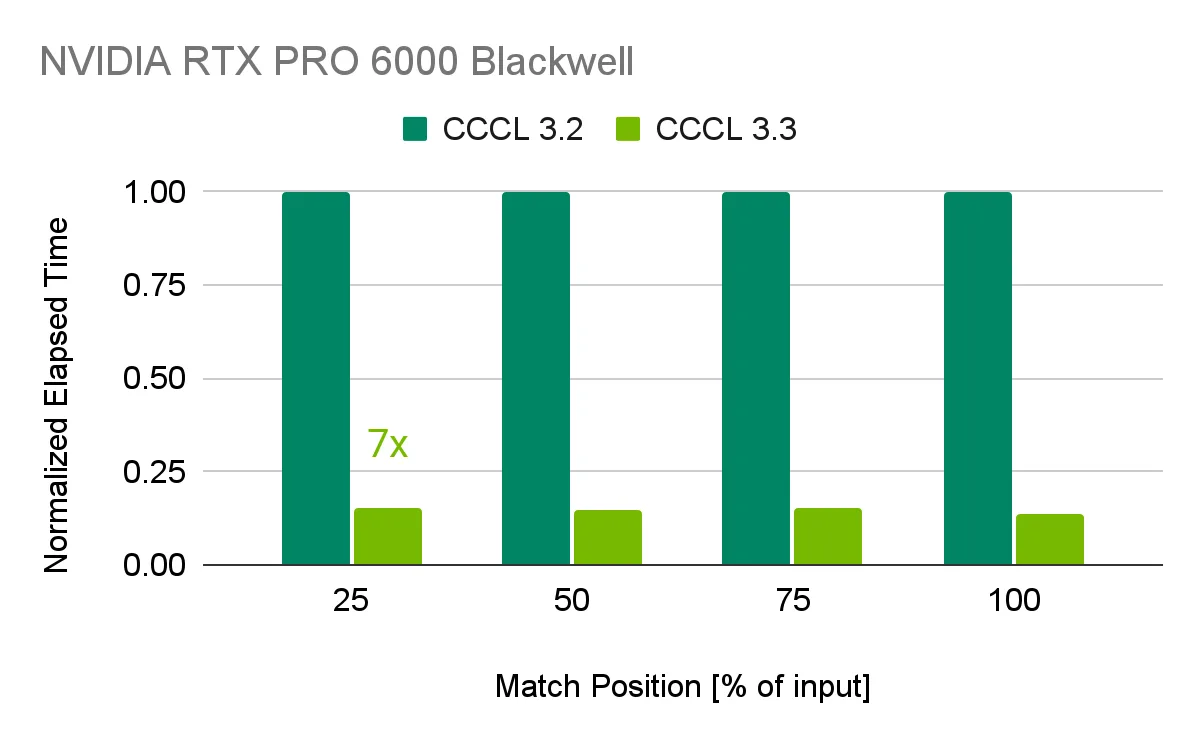
이 차트는 CUDA 13.3의 다른 축도 보여줍니다. CCCL 3.3의 search algorithm 개선은 특정 API 하나의 성능 개선처럼 보일 수 있지만, 실제로는 AI와 HPC code가 반복적으로 쓰는 낮은 수준 primitive의 비용을 줄이는 일입니다. NVIDIA는 cub::DeviceFind::FindIf가 CCCL 3.2의 search 구현 대비 최대 7배 speedup을 낸다고 설명합니다. LLM inference의 핵심 경로가 아니더라도, data preprocessing, retrieval, simulation, sparse workflow 같은 주변 workload에서는 이런 primitive가 누적 비용을 만듭니다.
왜 지금 compiler tuning인가
NVIDIA가 이 시점에 CompileIQ를 꺼낸 이유는 시장 구조와 맞물립니다. frontier model 회사와 AI app 회사는 더 이상 "GPU만 있으면 된다"고 말하기 어렵습니다. 같은 GPU를 얼마나 조밀하게 쓰는지가 곧 제품 경쟁력입니다. GPU 확보 경쟁이 계속되는 동안, 이미 가진 GPU에서 5%, 10%, 15%를 더 뽑는 기술은 곧 capacity 확보와 같습니다.
특히 LLM inference는 학습과 다릅니다. 학습은 큰 job을 길게 돌리고, throughput과 stability가 중요합니다. inference는 traffic이 변하고, latency SLO가 있고, cache hit rate와 batch shape가 계속 바뀝니다. 이 환경에서는 kernel 하나의 평균 속도뿐 아니라 다양한 shape에서의 재현성과 tail latency가 중요합니다. compiler tuning을 자동화하더라도 실제 운영에서는 shape별 profile, model별 hotspot, hardware generation, power cap, driver version을 모두 고려해야 합니다.
CompileIQ는 이런 복잡성을 없애지 않습니다. 오히려 성능 엔지니어링의 새로운 관리 대상을 만듭니다. ACF 파일을 언제 만들고, 어떤 benchmark로 검증하며, 어떤 hardware에만 적용할지 결정해야 합니다. CUDA version이 바뀌면 다시 탐색해야 할 수도 있습니다. kernel source가 바뀌면 기존 ACF가 더 이상 최적이 아닐 수 있습니다. 하지만 이것은 나쁜 소식만은 아닙니다. 관리 대상이 된다는 것은 자동화와 review와 rollback의 대상이 된다는 뜻이기도 합니다.
개발팀이 가져갈 실무 질문
이번 CUDA 13.3 발표를 보고 모든 팀이 당장 CompileIQ를 도입해야 하는 것은 아닙니다. 일반적인 AI 제품팀이 hosted API를 쓰고 있다면 이 변화는 간접적인 비용 개선으로만 체감될 가능성이 큽니다. OpenAI, Anthropic, Google, xAI, Mistral 같은 모델 제공자가 내부 inference stack을 더 잘 최적화하면 언젠가 가격, latency, rate limit, capacity로 내려올 수 있습니다.
자체 inference stack을 운영하는 팀은 다릅니다. vLLM, TensorRT-LLM, Triton, custom CUDA extension, CUTLASS kernel을 직접 다루는 팀이라면 질문이 구체적입니다. 첫째, 우리 workload에서 top hotspot kernel은 무엇인가. 둘째, 그 kernel의 benchmark는 실제 traffic shape를 대표하는가. 셋째, speed만 볼 것인가, power와 compile time과 tail latency도 같이 볼 것인가. 넷째, compiler tuning artifact를 source control과 CI에 넣을 준비가 되었는가.
CUDA Python 1.0도 비슷합니다. Python에서 GPU runtime을 직접 제어하는 팀은 stable API와 semantic versioning의 이점을 볼 수 있습니다. 하지만 runtime 제어가 쉬워질수록 책임도 커집니다. green context partitioning을 잘못 잡으면 특정 workload가 굶을 수 있고, checkpoint/restore가 실패하는 경계 조건을 이해하지 못하면 장애 복구가 더 복잡해질 수 있습니다. GPU memory IPC는 copy를 줄일 수 있지만, lifetime과 ownership을 명확히 하지 않으면 debugging이 어려워집니다.
경쟁은 모델 밖에서 벌어집니다
CUDA 13.3은 모델 발표가 아닙니다. 새 LLM도 아니고, 새 AI 앱도 아닙니다. 그런데 이 업데이트가 중요한 이유는 AI 경쟁이 점점 모델 밖으로 확장되고 있기 때문입니다. 모델이 비슷한 성능대를 형성하면, 실제 차이는 serving cost, latency, reliability, observability, deployment flexibility에서 납니다. 이 모든 것은 compiler, runtime, library, scheduler, hardware feature와 연결됩니다.
NVIDIA는 GPU vendor인 동시에 AI software stack vendor입니다. CUDA, cuBLAS, CUTLASS, TensorRT-LLM, Triton integration, NIM, Nsight, Run:ai까지 이어지는 stack은 단순히 GPU를 팔기 위한 부속품이 아닙니다. AI 회사가 NVIDIA hardware를 계속 쓰게 만드는 운영 체계입니다. CompileIQ는 그 stack 안에서 compiler layer를 더 적극적인 제품 표면으로 끌어올립니다.
AMD ROCm, Intel oneAPI, open-source Triton/MLIR 계열도 같은 압박을 받습니다. AI team은 특정 GPU에서만 빠른 code보다 여러 hardware와 cloud에서 운영 가능한 code를 원합니다. 하지만 비용이 커질수록 vendor-specific optimization의 유혹도 커집니다. CUDA 13.3은 이 딜레마를 더 분명하게 만듭니다. portable abstraction은 중요하지만, 마지막 15%를 얻으려면 vendor compiler와 hardware feature 깊숙이 들어가야 할 수 있습니다.
결론: 15%는 작은 숫자가 아닙니다
CUDA 13.3의 뉴스 가치는 "새 기능이 많다"가 아닙니다. 더 정확히는 "AI inference의 원가표가 얼마나 낮은 계층까지 내려갔는가"입니다. NVIDIA는 LLM 추론 compute의 대부분이 GEMM과 attention에 있다는 사실을 전면에 놓고, compiler heuristic 탐색을 제품화했습니다. 동시에 CUDA Python 1.0과 green context, checkpointing, IPC로 Python 기반 GPU serving의 운영 표면을 다듬었습니다.
이 변화는 대다수 개발자에게 바로 보이지 않을 수 있습니다. ChatGPT나 Claude나 Gemini를 호출하는 사람은 CompileIQ를 직접 만지지 않습니다. 그러나 그 뒤에서 누군가는 attention kernel의 1%를 줄이고, batch shape를 다시 재고, GPU worker를 warm-start하고, compiler artifact를 versioning합니다. AI 제품의 가격과 속도와 사용 한도는 결국 이런 작업의 합으로 내려옵니다.
그래서 CUDA 13.3은 조용하지만 중요한 AI 인프라 뉴스입니다. 모델이 더 커지고 에이전트가 더 오래 실행될수록, "토큰을 얼마나 싸게 만들 수 있는가"는 더 중요한 질문이 됩니다. 그 답은 모델 아키텍처에만 있지 않습니다. 이번 발표가 보여주듯, 답의 일부는 compiler가 어떤 instruction을 고르고, Python runtime이 GPU context를 어떻게 나누고, library primitive가 tensor를 얼마나 덜 복사하느냐에 있습니다. LLM 추론 90% 병목의 새 튜닝 레버는 그렇게 모델 아래쪽에서 올라오고 있습니다.