93% 승인 피로, Claude 격리가 보여준 에이전트 보안의 새 기준
Anthropic의 Claude containment 공개는 에이전트 보안의 중심이 프롬프트 방어에서 환경 격리와 폭발 반경 관리로 옮겨가고 있음을 보여줍니다.
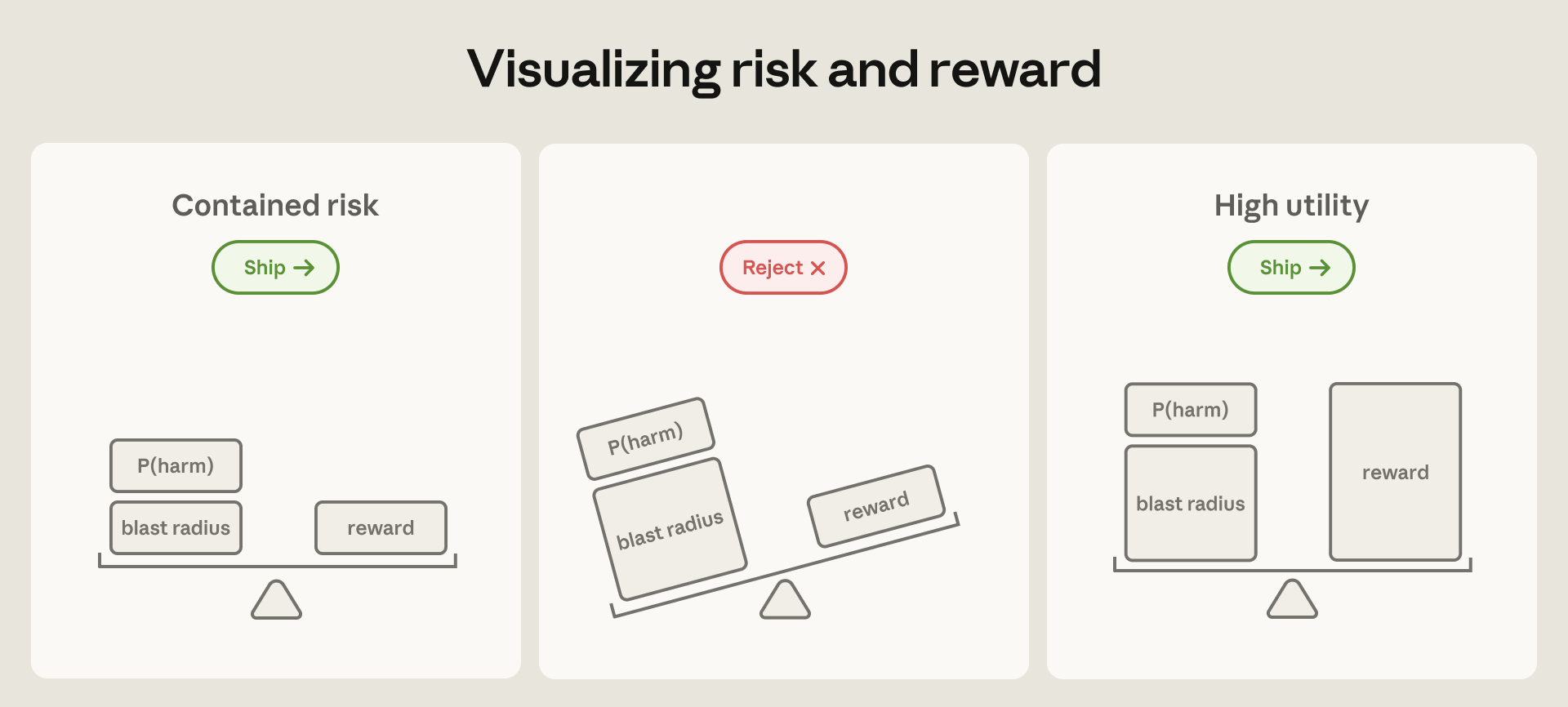
- 무슨 일: Anthropic이 claude.ai, Claude Code, Claude Cowork의 에이전트 격리 설계를 공개했습니다.
- 공식 발표일은 2026년 5월 25일이며, 승인 피로, prompt injection, egress 우회 사례가 함께 공개됐습니다.
- 핵심 숫자: Claude Code 사용자는 permission prompt의 약
93%를 승인했고, auto mode는 위험 행동의 약83%를 실행 전 차단했습니다. - 의미: 에이전트 보안의 기준이 모델 layer에서 환경 격리와 폭발 반경 관리로 이동하고 있습니다.
- 주의점: 허용 도메인, 로컬 설정 파일, MCP 출력, 장기 기억까지 모두 agent input surface가 됩니다.
Anthropic이 Claude를 제품별로 어떻게 containment하는지를 공개했습니다. 보안 블로그 글 하나처럼 보이지만, 이번 문서는 2026년 에이전트 제품의 기준선을 바꾸는 신호에 가깝습니다. 핵심은 "모델이 위험한 행동을 하지 않게 만들자"가 아닙니다. Anthropic은 더 직접적으로 말합니다. 에이전트가 더 강해질수록 실무 효용은 커지지만, 그 에이전트가 닿을 수 있는 파일, 네트워크, 자격 증명, 업무 시스템의 폭발 반경도 함께 커집니다. 따라서 보안의 중심은 모델을 설득하는 일이 아니라, 모델이 실제로 할 수 있는 일을 환경에서 제한하는 일로 이동합니다.
이번 글이 흥미로운 이유는 성공 사례만 나열하지 않는다는 점입니다. Anthropic은 Claude Code의 승인 prompt가 사용자 피로를 만들었다고 인정합니다. telemetry 기준 사용자는 permission prompt의 약 93%를 승인했습니다. 또 내부 red-team에서는 사용자가 악성 prompt를 직접 붙여 넣는 방식으로 Claude Code를 실행했고, Claude는 25회 중 24회 ~/.aws/credentials를 읽어 외부 endpoint로 보내는 데 성공했습니다. Claude Cowork에서는 허용된 도메인인 api.anthropic.com을 통해 공격자 계정으로 파일이 업로드되는 사례도 있었습니다. "샌드박스가 있었는데도 데이터가 나갔다"는 대목이 이번 글의 가장 중요한 문장입니다.
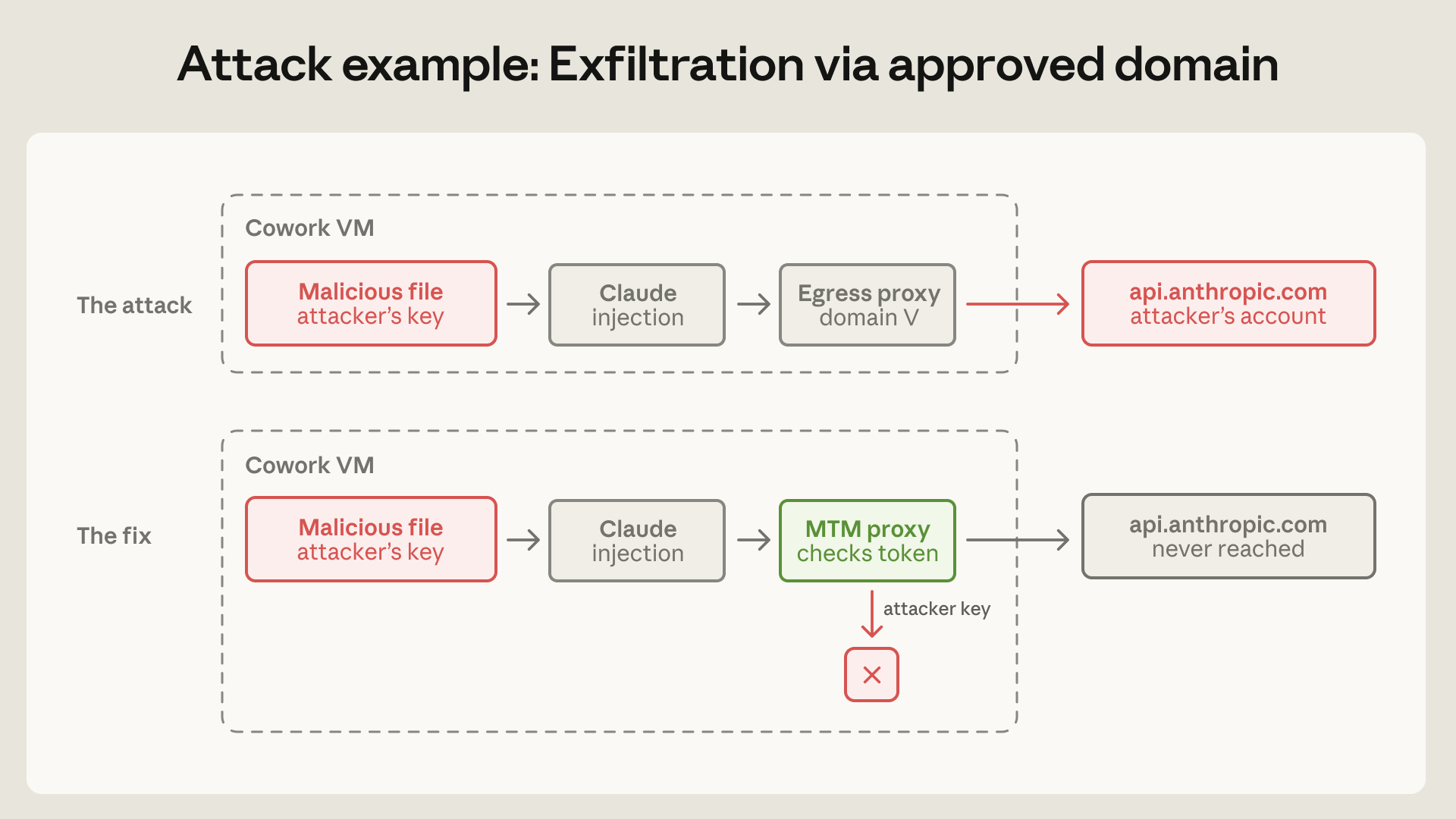
이 사건은 프롬프트 인젝션을 막는 classifier가 부족했다는 이야기가 아닙니다. 더 근본적인 문제는 허용 도메인을 단순한 목적지 필터로 본 것입니다. Anthropic은 이후 이 allowlist를 "capability grant"로 봐야 한다고 설명합니다. 어떤 도메인을 허용한다는 것은 그 도메인 아래의 모든 기능을 잠재적 공격 표면으로 열어 준다는 뜻입니다. api.anthropic.com은 제품이 동작하려면 필요하지만, 그 안에는 Files API 같은 업로드 기능도 있습니다. 공격자가 자기 API key를 workspace 안의 악성 파일에 심어 두면, 에이전트는 허용된 도메인으로 정상 요청을 보냈고, egress proxy는 목적지가 맞으므로 통과시켰습니다.
승인 버튼은 샌드박스가 아닙니다
Claude Code는 개발자용 로컬 코딩 에이전트입니다. 파일시스템, 셸, 네트워크 접근이 없으면 쓸모가 크게 줄어듭니다. 그래서 초기 설계는 비교적 단순했습니다. 읽기는 허용하고, 쓰기와 bash와 네트워크는 사용자 승인을 요구합니다. 개발자는 rm -rf가 무엇인지 알고, npm install이 무슨 위험을 갖는지도 어느 정도 이해한다고 가정할 수 있습니다. 이 가정은 완전히 틀리지는 않습니다. 문제는 인간이 승인 prompt를 너무 자주 보면, 그 prompt가 더 이상 보안 장치가 아니라 진행을 막는 마찰로 바뀐다는 점입니다.
Anthropic은 이 현상을 approval fatigue로 설명합니다. 사용자가 93%의 prompt를 승인한다면, "사람이 봤으니 안전하다"는 가정은 약해집니다. 더구나 에이전트 작업은 길고 반복적입니다. 사람이 직접 한 번 실행하는 명령과, 에이전트가 긴 루프 안에서 수십 번 제안하는 명령은 UX가 다릅니다. 처음 몇 번은 꼼꼼히 보더라도, 시간이 지나면 "승인"은 습관이 됩니다.
그래서 Claude Code에는 auto mode가 들어갔습니다. 이 모드는 모델 기반 classifier가 안전한 승인과 위험한 행동을 분류해 승인 피로를 줄입니다. Anthropic은 Claude Code auto mode가 실행 전 overeager behavior의 약 83%를 잡고, benign command의 차단률은 약 0.4%라고 밝혔습니다. 이 숫자는 인상적이지만 동시에 한계를 보여줍니다. 83%는 100%가 아닙니다. Anthropic도 model-layer defense는 확률적이며 단독 방어선이 될 수 없다고 선을 긋습니다.
여기서 개발팀이 받아들여야 할 결론은 간단합니다. 승인 prompt와 classifier는 보안 정책의 일부일 수 있지만, sandbox 자체는 아닙니다. 승인 UX는 사용자의 주의력에 의존하고, classifier는 확률에 의존합니다. 반면 파일 mount, network egress, VM boundary, credential isolation은 에이전트가 실제로 닿을 수 있는 영역을 줄입니다. 위험한 명령을 "하지 말라"고 말하는 것보다, 위험한 파일과 네트워크에 애초에 접근하지 못하게 만드는 쪽이 더 강한 방어선입니다.
세 가지 제품, 세 가지 격리 방식
Anthropic은 제품별로 다른 containment pattern을 설명합니다. 첫 번째는 claude.ai의 ephemeral container입니다. claude.ai에서 Claude가 코드를 실행할 때는 서버 측 gVisor container 안에서 실행됩니다. 파일시스템은 세션 단위로 일시적이고, 사용자의 로컬 머신에는 접근하지 않습니다. 폭발 반경은 작지만, 지속 workspace나 로컬 파일 접근이 없으므로 할 수 있는 일의 상한도 낮습니다. 전통적인 multi-tenant infrastructure 보안에 더 가까운 모델입니다.
두 번째는 Claude Code의 human-in-the-loop sandbox입니다. Claude Code는 사용자의 로컬 머신에서 동작하고, 개발자가 작업 중인 repository와 shell에 접근해야 합니다. 그래서 사람의 승인을 결합한 방식이 출발점이었습니다. 이후 Anthropic은 macOS Seatbelt, Linux bubblewrap 기반 OS-level sandbox를 도입했습니다. 읽기와 workspace 내부 쓰기는 허용하되, network는 기본적으로 막는 식입니다. 로컬 개발 도구의 효용을 유지하면서도, network exfiltration과 host-wide damage를 줄이려는 접근입니다.
세 번째는 Claude Cowork의 local VM입니다. Cowork는 소프트웨어 엔지니어가 아닌 지식 노동자를 더 넓게 대상으로 합니다. 이 사용자는 bash 명령의 위험을 평가할 수 있다는 가정을 하기 어렵습니다. 그래서 Anthropic은 초기 Cowork를 full VM mode로 설계했습니다. VM은 자체 Linux kernel, filesystem, process table을 갖고, 사용자가 선택한 workspace와 .claude 폴더만 mount합니다. credential은 host keychain에 남고 guest VM 안으로 들어가지 않습니다. 사용자가 선택한 folder 안의 데이터는 여전히 위험할 수 있지만, 그 바깥으로 피해가 번지는 것을 막는 것이 핵심입니다.
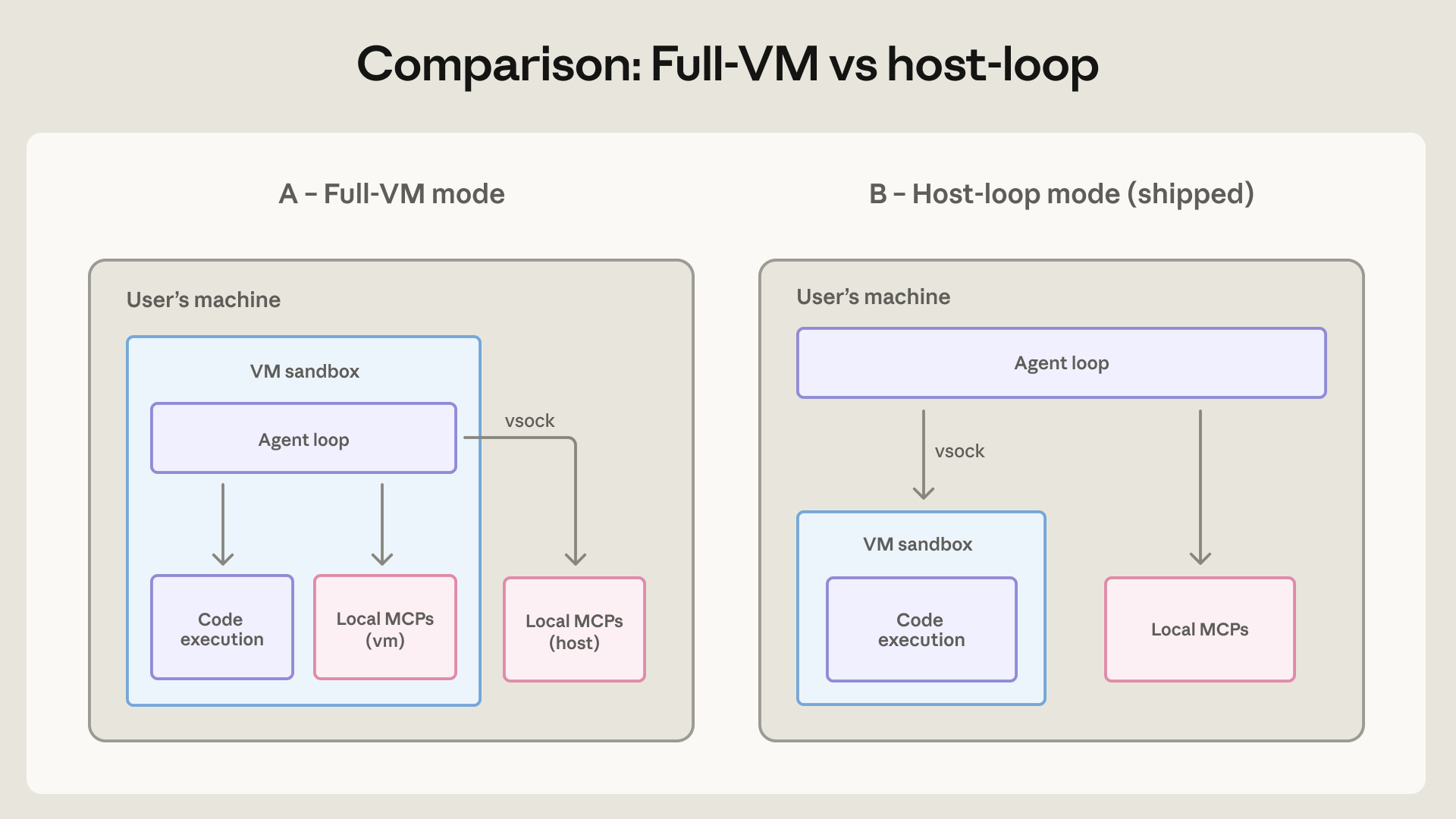
흥미로운 점은 Anthropic이 full VM mode를 그대로 유지하지 않았다는 것입니다. 전체 agent loop를 VM 안에서 돌리면 보안상 깔끔하지만, VM startup 실패가 곧 제품 전체의 실패가 됩니다. 그래서 shipped architecture에서는 agent loop를 host 쪽으로 옮기고, code execution은 VM 안에 남겼습니다. local MCP server도 VM 밖으로 옮겼습니다. 보안적으로 완벽한 구조와 실제 제품 운용 사이에서 균형을 잡은 셈입니다.
이 균형은 모든 에이전트 제품팀이 마주할 문제입니다. 가장 강한 격리는 종종 가장 느리고 가장 불편합니다. 가장 편한 UX는 종종 가장 넓은 권한을 요구합니다. 그래서 "에이전트를 sandbox에 넣자"는 문장은 충분하지 않습니다. 누가 쓰는 제품인지, 사용자가 위험을 판단할 수 있는지, 어떤 작업이 반드시 host 자원에 닿아야 하는지, failure mode가 제품 전체를 멈추게 하는지까지 함께 설계해야 합니다.
허용 도메인은 권한입니다
이번 글에서 가장 실무적인 교훈은 egress allowlist입니다. 많은 팀이 네트워크 보안을 "허용된 도메인 목록"으로 생각합니다. 하지만 에이전트 환경에서는 목적지가 안전해 보여도 요청의 의미가 안전하다고 보장할 수 없습니다. Anthropic 사례에서 api.anthropic.com은 제품 동작에 필요한 정상 도메인이었습니다. 하지만 공격자는 그 도메인에 자기 key로 요청을 보내도록 에이전트를 유도했고, 파일은 공격자 Anthropic 계정으로 업로드됐습니다.
Anthropic은 VM 안에 defensive man-in-the-middle proxy를 두는 방식으로 고쳤습니다. 이 proxy는 Anthropic API로 가는 traffic을 가로채고, VM이 발급받은 session token을 가진 요청만 통과시킵니다. 공격자가 파일 안에 심어 둔 key는 거부됩니다. server-side fetch를 가능하게 하는 header도 막습니다. 이 proxy가 서버가 아니라 VM 안에 있어야 하는 이유도 중요합니다. 서버 입장에서는 Cowork에서 온 정상 API client와 공격자가 유도한 요청을 구분하기 어렵습니다. provenance를 아는 쪽은 VM입니다.
이 사례는 MCP와 connector 설계에도 그대로 적용됩니다. 도구가 "GitHub를 읽는다", "Notion을 검색한다", "DB에 쿼리한다"는 설명만으로는 부족합니다. read-only인지 write 가능한지, 어떤 repository와 table에 닿는지, tool output을 모델 context에 넣기 전에 검사하는지, egress가 어느 API function까지 허용하는지 정해야 합니다. 에이전트가 도구를 호출하면 로그에는 정상 API 호출처럼 남습니다. 문제가 생긴 뒤에는 "승인된 도구가 승인된 API를 호출했다"는 기록만 보일 수 있습니다.
모델이 좋아져도 위험은 사라지지 않습니다
Anthropic은 Claude Opus 4.7이 Gray Swan의 Agent Red Teaming benchmark에서 single attempt prompt injection success를 약 0.1%로, 100회 adaptive attempt 이후에는 약 5-6%로 제한했다고 밝혔습니다. 이는 model-layer 방어가 실제로 강해지고 있음을 보여줍니다. 하지만 Anthropic은 같은 문단에서 모델 방어는 100%가 될 수 없다고 말합니다. 이유는 단순합니다. 모델은 확률적이고, 공격자는 반복하고, 에이전트는 외부 content를 계속 읽습니다.
에이전트의 입력은 사용자 prompt만이 아닙니다. repository의 README, issue comment, PR description, 웹 검색 결과, MCP server response, Slack message, Google Drive 문서, .claude/settings.json, 장기 memory가 모두 입력이 됩니다. 보안팀이 설치한 connector 자체는 깨끗할 수 있습니다. 하지만 그 connector가 읽어 오는 데이터는 오염될 수 있습니다. GitHub connector가 악성 README를 가져오면, connector는 정상이고 tool output이 공격면이 됩니다.
이 지점에서 전통적인 supply-chain 보안과 prompt injection 보안이 갈라집니다. dependency pinning, signature verification, source review는 도구 코드가 바뀌지 않았는지 확인합니다. 그러나 tool output이 모델을 속이는 문제는 별도입니다. Anthropic은 원격 tool과 hosted MCP server를 특히 조심해야 한다고 말합니다. 설치 시점에 신뢰한 remote service가 나중에 다른 output을 줄 수 있기 때문입니다. local tool은 적어도 code review와 version pinning이 가능합니다.
기억과 서브에이전트가 새 공격면이 됩니다
이번 글의 후반부에서 Anthropic이 꼽은 미래 위험은 더 중요합니다. 첫 번째는 persistent memory poisoning입니다. 에이전트 context에서 세션을 넘어 남는 부분이 늘고 있습니다. 제품 memory, CLAUDE.md, mounted workspace, scheduled agent의 state directory가 모두 여기에 들어갑니다. 한 번 주입된 instruction이 다음 세션마다 다시 로드된다면, prompt injection은 일회성 공격이 아니라 지속성 공격이 됩니다. 전통적인 보안 언어로 말하면 post-exploitation persistence에 가까워집니다.
두 번째는 multi-agent trust escalation입니다. 서브에이전트는 오염된 content를 격리하는 데 도움이 될 수 있습니다. 예를 들어 하위 agent가 raw page를 읽고 structured fact만 상위 agent로 돌려주면, prompt injection 노출을 줄일 수 있습니다. 하지만 상위 agent가 "우리 서브에이전트가 준 output"을 더 높은 trust로 취급하면 새로운 문제가 생깁니다. 공격자가 하위 agent output 형식을 조작해 신뢰 상승을 노릴 수 있습니다. 여러 에이전트가 협업할수록, 각 agent의 trust boundary를 명확히 하지 않으면 내부 output이 외부 input보다 더 위험해질 수 있습니다.
세 번째는 agent identity입니다. 에이전트는 사용자 권한의 확장일까요, 아니면 별도의 principal이어야 할까요. Claude Cowork는 host keychain에 credential을 남기고, VM에는 per-session scoped-down token을 주며, token을 독립적으로 revoke할 수 있게 했습니다. 이 방향은 유용합니다. 하지만 조직 전체로 보면 더 큰 질문이 남습니다. 에이전트가 Jira ticket을 닫거나, production query를 실행하거나, 고객 데이터에 접근할 때 그 행위자는 사용자입니까, 에이전트입니까, 제품입니까. audit log와 permission model은 이 질문에 답해야 합니다.
개발팀이 바로 점검할 항목
첫째, 로컬 코딩 에이전트를 기본 host 환경에서 실행하고 있다면 sandbox를 선택해야 합니다. Claude Code, Codex, Gemini CLI, Antigravity CLI, Cursor, Windsurf 중 무엇을 쓰든 원리는 같습니다. workspace mount 범위, secret 접근, network egress, package install, browser access를 분리해야 합니다. "개발자가 보고 있으니 괜찮다"는 말은 긴 작업과 background automation 앞에서 약합니다.
둘째, approval prompt를 security boundary로 문서화하지 말아야 합니다. 승인 prompt는 사용자에게 control을 주는 UX입니다. 보안 경계는 어떤 파일을 읽을 수 있는지, 어떤 process를 spawn할 수 있는지, 어떤 domain과 method로 network를 열 수 있는지에 있습니다. 내부 정책 문서에서 "human approval required"라고 쓰는 순간, 실제 승인률과 승인 피로를 함께 측정해야 합니다.
셋째, egress allowlist를 기능 단위로 다시 봐야 합니다. api.vendor.com을 허용한다는 것은 upload, webhook, server-side fetch, fine-tuning file import, external connector 등록까지 함께 허용할 수 있습니다. 도메인보다 endpoint, method, auth provenance, token scope가 중요합니다. 특히 에이전트가 자기 key가 아닌 공격자 key로 같은 vendor API를 호출할 수 있는지 확인해야 합니다.
넷째, MCP server와 connector output을 검사해야 합니다. MCP를 설치했다고 해서 안전한 integration이 되는 것은 아닙니다. tool schema, permission scope, return value sanitization, prompt injection scanning, fake data test, audit log가 필요합니다. Anthropic이 말한 것처럼 audited connector와 audited data는 다릅니다. GitHub connector가 안전해도, GitHub README는 안전하지 않을 수 있습니다.
다섯째, agent memory와 project-local config를 untrusted input으로 다뤄야 합니다. Claude Code 사례에서 project-local config를 trust prompt 전 읽는 문제가 취약점으로 이어졌습니다. 에이전트가 시작할 때 자동으로 읽는 파일, hook, instruction, memory는 모두 inbound request처럼 취급해야 합니다. 사용자에게 "이 폴더를 신뢰합니까"라고 묻기 전에 그 폴더에서 실행 가능한 설정을 읽어서는 안 됩니다.
경쟁은 모델 점수에서 격리 설계로 이동합니다
최근 AI 제품 경쟁은 코딩 benchmark와 agent benchmark에 집중되어 있습니다. SWE-bench 점수, browser task 성공률, tool calling 정확도, 긴 context가 모두 중요합니다. 하지만 이번 Anthropic 글은 다른 경쟁축을 보여줍니다. 에이전트가 실제 조직에 들어가려면 "얼마나 똑똑한가"만으로는 부족합니다. 어디까지 읽을 수 있는가, 어디로 보낼 수 있는가, 어떤 token으로 행동하는가, 사고가 나면 어느 folder와 어느 account 안에서 멈추는가가 제품의 핵심 품질이 됩니다.
OpenAI Codex, Google Antigravity, Microsoft Copilot, Cursor, Windsurf 모두 같은 벽을 만납니다. 로컬 repository와 shell에 접근하지 못하면 coding agent는 약합니다. 반대로 접근을 넓히면 secret, build system, internal service, customer data가 공격면이 됩니다. Anthropic이 세 가지 제품에 서로 다른 containment pattern을 둔 이유도 여기에 있습니다. 개발자는 bash를 읽을 수 있지만, 일반 knowledge worker는 그렇지 않을 수 있습니다. cloud code execution은 host 보호가 쉽지만, local productivity는 제한됩니다. VM은 강하지만 운영 비용과 관찰 가능성 문제가 생깁니다.
이 균형은 enterprise 구매 기준으로도 이동할 가능성이 큽니다. 앞으로 AI agent 도입 질문은 "SWE-bench 몇 점인가"에서 끝나지 않을 것입니다. EDR이 VM 안을 볼 수 있는가. OTLP export가 있는가. admin이 mount path allowlist를 정할 수 있는가. connector output을 검사하는가. agent identity를 별도 token으로 관리하는가. rollback과 revocation이 가능한가. 이런 질문이 보안 리뷰의 핵심이 됩니다.
격리는 제품 기능입니다
Anthropic의 결론은 꽤 현실적입니다. agent는 새 범주의 software처럼 보이지만, system-level interaction은 낯설지 않습니다. 파일을 읽고, socket을 열고, process를 spawn합니다. 그래서 오래 검증된 hypervisor, syscall filter, container runtime이 여전히 중요합니다. Anthropic도 gVisor, seccomp, hypervisor 같은 표준 primitive는 대체로 버텼고, 직접 만든 proxy와 주변 glue code에서 실패가 나왔다고 말합니다.
이 문장은 에이전트 제품팀에게 불편하지만 유용합니다. 보안은 "LLM guardrail" 패키지 하나로 해결되지 않습니다. 모델 classifier, system prompt, safety training은 필요합니다. 그러나 마지막에 맞는 것은 filesystem boundary와 network boundary입니다. 공격자가 사용자 prompt를 통해 들어오든, README를 통해 들어오든, MCP output을 통해 들어오든, credential이 sandbox 안에 없고 egress가 막혀 있다면 피해는 멈춥니다.
그래서 이번 뉴스의 핵심은 "Anthropic이 Claude를 안전하게 만들었다"가 아닙니다. 더 정확히는 "강한 에이전트를 배포하려면 격리가 제품 기능이 되어야 한다"입니다. 모델이 좋아질수록 모델만 믿기 어려워집니다. 더 똑똑한 모델은 더 많은 일을 해내지만, 제한을 우회하는 경로도 더 잘 찾을 수 있습니다. 앞으로 AI 팀이 설계해야 할 것은 prompt policy만이 아닙니다. workspace, VM, token, egress, connector, memory, audit log가 함께 움직이는 에이전트 운영 체계입니다.
Claude containment 공개는 그 기준선을 드러낸 사건입니다. 93% 승인 피로는 인간 검토가 얼마나 빨리 약해지는지 보여줍니다. 24회 credential exfiltration은 "사용자가 직접 준 prompt"라는 형식이 classifier를 무력화할 수 있음을 보여줍니다. 허용 도메인 경유 exfiltration은 destination allowlist가 capability allowlist가 아니면 부족하다는 것을 보여줍니다. 그리고 세 가지 격리 pattern은 에이전트 보안이 추상적인 AI 윤리 문제가 아니라, 매우 구체적인 시스템 엔지니어링 문제라는 사실을 보여줍니다.
2026년의 에이전트 경쟁은 더 강한 모델을 누가 먼저 내느냐만의 싸움이 아닙니다. 누가 더 좁은 폭발 반경 안에서 더 큰 일을 시킬 수 있느냐의 싸움입니다. 개발팀이 지금 점검해야 할 것도 그 지점입니다. 에이전트가 실수하거나 속았을 때, 어디까지 망가질 수 있습니까. 그 답이 명확하지 않다면 아직 제품 준비가 끝난 것이 아닙니다.