Mistral OCR 4, 문서 RAG 비용을 다시 계산할 가격표
Mistral OCR 4는 170개 언어, 경계 상자, 신뢰도 점수, 자체 호스팅으로 기업 문서 RAG 인입 비용과 검증 단계를 바꿉니다.

- 무슨 일: Mistral AI가 2026년 6월 23일
OCR 4를 공개했습니다.- 문서 텍스트와 함께 경계 상자, 블록 유형, 단어 단위 신뢰도, 마크다운 구조를 반환합니다.
- 숫자: 170개 언어, 1000쪽당 4달러, Batch API 1000쪽당 2달러, Document AI 1000쪽당 5달러입니다.
- 개발 영향: PDF와 스캔 문서가 RAG, 기업 검색, 문서 에이전트의 입력 데이터로 들어가는 비용표가 바뀝니다.
- 주의점: Mistral은 의료·법률·고위험 금융 판단과 실시간 처리에는 쓰지 말라고 적었습니다.
Mistral AI가 2026년 6월 23일 공개한 Mistral OCR 4는 겉으로는 문서 OCR 발표입니다. 하지만 개발팀이 봐야 할 지점은 “글자를 얼마나 잘 읽느냐”보다 더 좁고 실무적입니다. OCR 4는 PDF, DOC, PPT, OpenDocument 같은 기업 문서를 RAG와 검색 파이프라인에 넣기 전에 어떤 단위로 자르고, 어디를 인용하고, 어떤 값은 사람에게 다시 확인시킬지 정하는 인입 모델입니다.
공식 발표에서 Mistral은 OCR 4가 추출 텍스트와 함께 경계 상자, 블록 유형, 단어 단위 신뢰도, 마크다운 구조를 반환한다고 설명했습니다. 이전 세대 OCR이 “페이지를 텍스트로 바꾼다”에 가까웠다면, 이번 발표는 문서의 위치, 역할, 신뢰도를 API 응답 안에 넣습니다. RAG 시스템 입장에서는 문서 전체를 긴 문자열로 밀어 넣는 대신 제목, 표, 방정식, 서명, 본문 블록을 다른 검색 단위로 취급할 수 있습니다.
가격표도 발표의 일부입니다. OCR 4 API는 1000쪽당 4달러, Batch API는 1000쪽당 2달러, Document AI는 1000쪽당 5달러입니다. Mistral은 Document AI가 같은 OCR 결과 위에 JSON 스키마, 이미지 주석, 사용자 지시 같은 구조화 단계를 얹는 방식이라고 설명했습니다. 대량 인입 배치는 Batch API로 낮추고, 특정 문서에서 업무 필드를 뽑아야 할 때는 Document AI 파라미터를 붙이는 구조입니다.
이번 발표가 AI 개발자에게 닿는 이유는 문서가 에이전트의 가장 흔한 입력이기 때문입니다. 계약서, 송장, 의료 서류, 연구 PDF, 회의 자료, 정책 문서는 이미 회사 안에 쌓여 있습니다. 문제는 모델이 문서를 “읽을 수 있다”는 사실만으로 업무 시스템에 바로 넣을 수 없다는 점입니다. 표의 열이 밀리거나, 숫자 한 자리가 잘못 읽히거나, 서명의 위치가 빠지면 검색 답변은 그럴듯해도 업무 결과는 틀립니다.
OCR 4가 내세우는 첫 차이는 경계 상자입니다. 경계 상자는 문서 안에서 특정 텍스트나 블록이 놓인 좌표를 알려줍니다. 이 정보가 있으면 검색 결과를 원문 위에 하이라이트하거나, 사람이 검수할 때 문제 블록으로 바로 이동할 수 있습니다. 기업 RAG에서는 “출처가 있다”는 말보다 “이 답변의 근거가 7쪽 표 3행 2열에 있다”는 링크가 더 중요합니다.
두 번째 차이는 블록 분류입니다. Mistral은 OCR 4가 제목, 표, 방정식, 서명 등 블록 유형을 분류한다고 설명했습니다. 검색 파이프라인에서는 본문 문단과 표 셀을 같은 방식으로 자르면 회수율과 정밀도가 흔들립니다. 표는 행과 열의 관계를 보존해야 하고, 방정식은 일반 문장 토큰처럼 다루면 뜻이 깨집니다. 블록 분류가 API 응답에 있으면 후처리 코드는 문서 유형별 규칙을 덜 하드코딩해도 됩니다.
세 번째 차이는 인라인 신뢰도입니다. Mistral은 OCR 4가 페이지와 단어 수준 신뢰도 점수를 낸다고 적었습니다. 이 값은 모델이 모르는 것을 인정하는 장치가 아니라, 운영자가 검수 예산을 배치하는 신호입니다. 예를 들어 송장 번호, 금액, 만기일처럼 틀리면 비용이 생기는 필드는 낮은 신뢰도일 때 사람에게 보내고, 사내 검색의 일반 본문은 자동 인입하는 식으로 파이프라인을 나눌 수 있습니다.
| 선택지 | 가격 | 쓰는 상황 |
|---|---|---|
| OCR 4 API | 1000쪽당 4달러 | 앱, 에이전트, 검색 인입 코드가 원시 응답을 직접 다룰 때 |
| Batch API | 1000쪽당 2달러 | 보관 문서, 지식베이스, 대량 PDF를 밤새 처리할 때 |
| Document AI | 1000쪽당 5달러 | JSON 스키마, 이미지 주석, 사용자 지시로 업무 필드를 만들 때 |
벤치마크 수치는 강하게 제시됐습니다. Mistral은 600개 이상 문서와 12개 이상 언어에서 독립 주석자가 OCR 4 출력을 다른 시스템과 비교했고, 평균 72% 선호율을 기록했다고 밝혔습니다. 자동 벤치마크에서는 OlmOCRBench 전체 점수 85.20을 적었습니다. 발표문은 자동 벤치마크의 형식 잡음과 채점 한계를 인정하고, 사람 평가를 함께 제시했다는 점을 강조했습니다.
이 수치를 그대로 받아들이기 전에 표본과 업무 문서를 분리해야 합니다. HN 댓글에서 한 사용자는 “1000쪽당 4달러는 싸지만, 이전 버전도 내부 벤치마크와 실제 사용 결과가 달랐다”는 취지로 경계했습니다. 다른 사용자는 발표 그래프의 y축이 50 또는 95부터 시작하는 점을 지적했습니다. Mistral이 발표한 수치는 제품 비교의 출발점이지, 각 회사의 계약서·영수증·팩스·스캔 품질을 대신 검증해 주는 것은 아닙니다.
자체 호스팅은 기업 판매에서 더 큰 훅입니다. Mistral은 OCR 4가 단일 컨테이너로 배포될 만큼 작고, 엄격한 개인정보·데이터 주권·규정 준수 요건이 있는 조직이 문서를 자체 인프라 안에 둘 수 있다고 밝혔습니다. API 전송 자체가 막히는 금융, 공공, 의료, 법무 조직에는 이 조건이 정확도 수치보다 먼저 검토됩니다.
다만 자체 호스팅이 곧 공개 가중치를 뜻하지는 않습니다. HN에서도 “가중치를 내려받는 방식이 아니라 영업 문의형 자체 호스팅으로 보인다”는 반응이 나왔습니다. Mistral은 오픈 모델 회사라는 이미지가 강하지만, OCR 4는 공식 발표와 모델 카드 기준으로 상용 서비스와 기업 배포 옵션에 가깝습니다. 오픈소스 OCR을 찾는 팀이라면 Baidu Unlimited-OCR, Marker, Tesseract 계열, LlamaParse 같은 다른 선택지도 함께 평가해야 합니다.
Mistral이 직접 적은 제한 문구도 기사에서 빼기 어렵습니다. OCR 4는 문서 이해 모델이지 의사결정 모델이 아니며, 의료 진단, 법률 조언이나 판단, 고위험 금융 의사결정, 안전 필수 시스템, 실시간 또는 지연 시간 민감 처리, 원시 오디오·비디오 같은 비문서 입력에 적합하지 않다고 설명했습니다. 이 문구는 면책 조항이면서 제품 설계 힌트입니다. OCR 결과는 판단 근거가 될 수 있지만, 판단 자체가 되면 안 됩니다.
예를 들어 금융 문서에서 9.0%가 90%로 잘못 읽히는 오류는 단순한 추출 실패가 아닙니다. 그 값이 대출 심사, 투자 위험 등급, 세금 계산으로 이어지면 손실 책임이 생깁니다. OCR 4의 신뢰도 점수와 경계 상자는 이런 오류를 줄이는 데 쓰일 수 있지만, 신뢰도 점수도 모델 출력입니다. 고위험 필드는 원문 이미지, 좌표, 규칙 기반 검증, 사람 검수, 감사 로그가 함께 있어야 합니다.
문서 에이전트 관점에서는 구조화 출력이 더 중요해집니다. 에이전트가 양식을 채우거나, 송장을 처리하거나, 규정 준수 문서를 확인하려면 “문서 전체 요약”보다 “어느 필드가 어디에 있고 어떤 근거로 추출됐는가”가 필요합니다. OCR 4가 반환하는 블록 유형과 좌표는 에이전트가 다음 행동을 정하기 전에 확인해야 할 원문 링크가 됩니다. 에이전트가 실수를 했을 때 되짚을 수 있는 최소 단위도 이 좌표와 블록입니다.
Mistral은 OCR 4를 Search Toolkit과도 연결했습니다. Search Toolkit은 Mistral이 AI Now Summit에서 공개한 오픈소스 검색 프레임워크이며, OCR 4의 구조화 출력은 인입, 검색, 평가 단계에 들어갑니다. 이 조합은 “모델 하나”보다 “문서가 검색 가능한 지식으로 바뀌는 공정”에 가깝습니다. 검색 품질은 생성 모델보다 앞단의 쪽 분할, 표 보존, 중복 제거, 인용 위치 정확도에 크게 좌우됩니다.
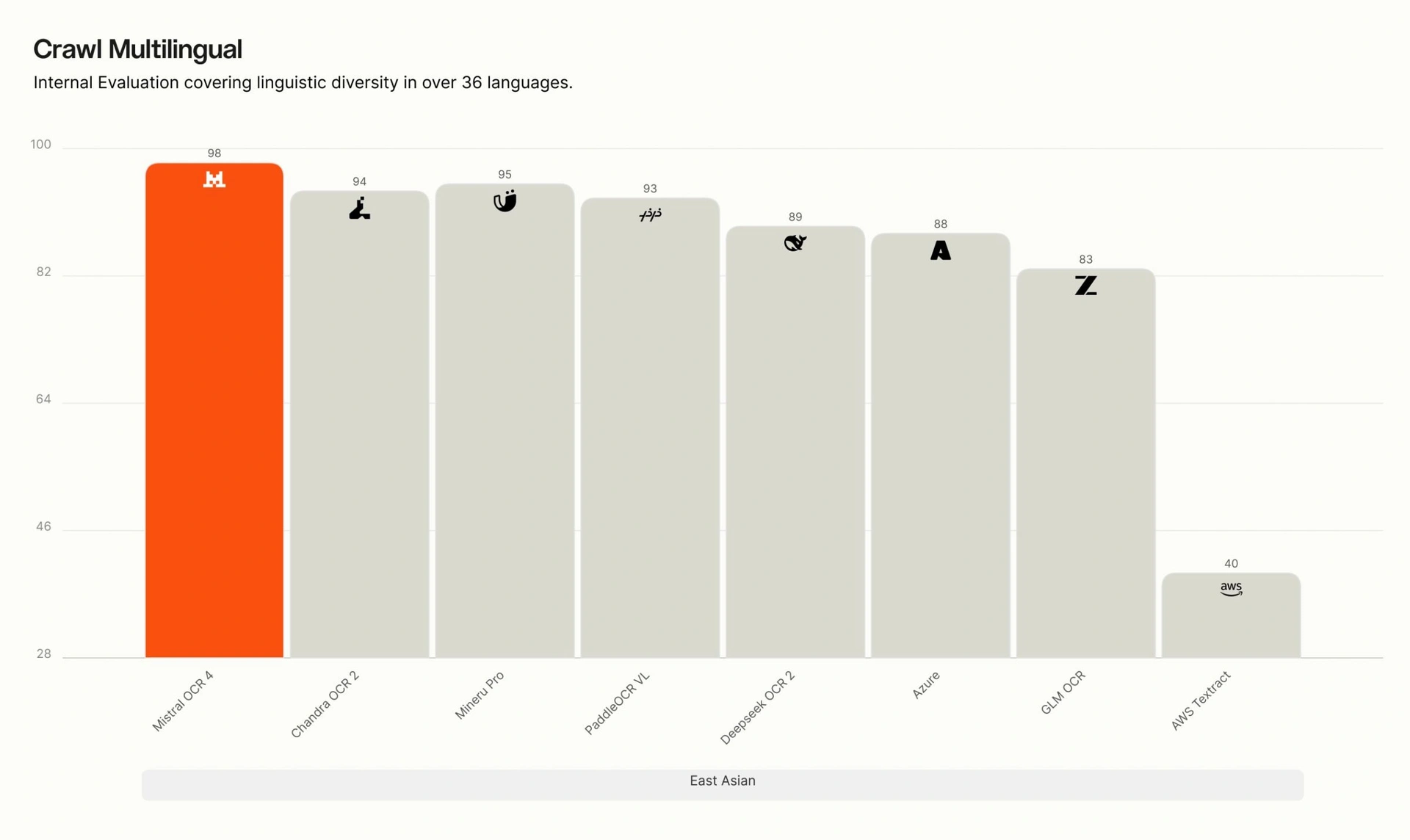
한국어 독자에게는 170개 언어 지원보다 실제 동아시아 문서 성능이 더 중요합니다. 공식 페이지는 동아시아 언어 벤치마크 이미지를 별도로 실었습니다. 한국어, 일본어, 중국어 문서는 띄어쓰기, 표기 체계, 세로쓰기, 스캔 품질, 표 구조에서 영어 문서와 다른 실패 양상을 가집니다. 발표 이미지가 이 영역을 다뤘다는 사실은 반갑지만, 국내 기업 문서와 공공 양식으로 별도 검증해야 합니다.
가격만 보면 Batch API 1000쪽당 2달러는 대량 인입 실험의 문턱을 낮춥니다. 100만 쪽 아카이브를 단순 계산하면 배치 기준 2000달러입니다. 그러나 실제 총비용에는 중복 제거, 파일 변환, 실패 재시도, 저장소 비용, 검색 색인, 사람 검수, 보안 심사, 감사 로그가 들어갑니다. OCR API 가격이 낮아질수록 병목은 추출 비용에서 운영 설계로 옮겨갑니다.
경쟁 구도는 범용 비전 모델과 전용 OCR 모델의 싸움입니다. GPT 계열, Gemini, Claude 같은 범용 모델은 화면 이해와 이미지 질의응답에서 강하지만, 대량 문서 인입에서는 쪽당 가격, 처리량, 좌표 출력, 자체 호스팅, 반복 검증이 더 중요합니다. 전용 OCR 모델은 화려한 대화 능력보다 같은 형식의 문서를 싸고 일관되게 처리하는 데 초점을 둡니다.
Mistral에게도 숙제가 있습니다. OCR 3와 비교해 가격이 올라간 만큼 경계 상자, 신뢰도, 블록 분류가 실제 업무 오류를 얼마나 줄이는지 보여줘야 합니다. HN 댓글처럼 일부 개발자는 “내부 벤치마크의 문서 수와 실제 시장 데이터가 얼마나 맞느냐”를 계속 묻습니다. Mistral이 기업 문서 AI 시장에서 신뢰를 얻으려면 공개 벤치마크 점수보다 고객별 재현 가능한 평가 절차를 제품 안에 넣어야 합니다.
개발팀이 지금 할 일은 간단한 데모를 넘는 평가표를 만드는 것입니다. 먼저 자기 회사 문서 200~500쪽을 표본으로 뽑고, 표·손글씨·저해상도 스캔·다국어·도장·서명·복잡한 레이아웃을 섞어야 합니다. 다음으로 추출 정확도, 좌표 정확도, 필드별 신뢰도, 검색 인용 정확도, 처리 시간, 쪽당 비용을 따로 기록해야 합니다. 마지막으로 낮은 신뢰도 필드가 사람 검수로 잘 넘어가는지 확인해야 합니다.
OCR 4 발표의 실질적 메시지는 “문서가 에이전트의 입력이 될 수 있다”가 아닙니다. 이미 대부분의 팀은 PDF와 스캔 문서를 모델에 넣어 보고 있습니다. 새로 계산해야 할 부분은 좌표, 신뢰도, 가격, 자체 호스팅, 검수 단계를 포함한 전체 파이프라인입니다. Mistral OCR 4는 그 계산표를 더 구체적으로 만들었습니다.
이번 제품은 AI 인프라 시장에서 작은 모델의 역할도 보여줍니다. 모든 작업을 가장 큰 범용 모델에 맡기는 대신, 문서 인입에는 전용 OCR 모델을 쓰고, 구조화 해석에는 작은 언어 모델을 얹고, 검색에는 별도 색인과 평가 도구를 붙이는 조합입니다. 에이전트가 업무 시스템에 들어갈수록 이런 조합형 스택이 늘어납니다. 사용자에게 보이는 답변은 하나지만, 뒤에서는 추출·분류·검증·검색·생성이 분리됩니다.
그래서 Mistral OCR 4는 모델 발표라기보다 문서 파이프라인의 가격표에 가깝습니다. 1000쪽당 2~5달러라는 숫자는 실험을 쉽게 만들고, 경계 상자와 신뢰도는 검수 위치를 좁힙니다. 반대로 공개 가중치가 아니고, 내부 벤치마크가 실제 문서마다 다르게 재현될 수 있으며, 고위험 의사결정에는 별도 통제가 필요합니다. 문서 RAG를 운영하려는 팀은 이 세 가지를 함께 계산해야 합니다.