Qwen-AgentWorld 공개, 에이전트가 먼저 연습할 7개 환경
Qwen-AgentWorld는 터미널·웹·MCP 등 7개 실행 환경을 언어로 예측해 에이전트 학습과 평가 비용을 낮추려는 공개 모델입니다.
- 무슨 일: Qwen 팀이
Qwen-AgentWorld-35B-A3B가중치와AgentWorldBench를 공개했습니다.- arXiv 제출은 2026년 6월 23일, GitHub 공개 공지는 6월 24일입니다.
- 의미: 실제 터미널·웹·안드로이드에 들어가기 전에 실패를 연습하는 구조입니다.
- 주의점: 최고 점수 주장은 새 벤치마크 기준이며, HN에서도 그림 표기 오류와 재현성 검증을 지적했습니다.
Qwen 팀이 2026년 6월 23일 arXiv에 Qwen-AgentWorld: Language World Models for General Agents를 올렸습니다. 다음 날 GitHub와 Hugging Face에는 Qwen-AgentWorld-35B-A3B 가중치와 AgentWorldBench가 공개됐습니다. 이름에 월드 모델이 들어가지만 이번 이야기는 영상 생성이나 3D 공간이 아닙니다. Qwen-AgentWorld가 예측하려는 세계는 터미널 출력, 검색 결과, MCP 도구 응답, 웹 페이지의 HTML, 안드로이드 화면, OS 작업 결과처럼 에이전트가 실제 업무 중 만나는 실행 환경입니다.
개발자 관점에서 이 발표가 눈에 띄는 이유는 모델 점수보다 학습장의 위치입니다. 코딩 에이전트와 웹 에이전트는 점점 더 많은 실제 행동을 합니다. 명령을 실행하고, 파일을 고치고, 브라우저를 클릭하고, API를 부릅니다. 이런 행동을 매번 실제 환경에서 반복하면 비용이 큽니다. 외부 서비스 요금, 샌드박스 유지비, 보안 위험, 느린 피드백이 모두 따라옵니다. Qwen-AgentWorld는 이 실행 표면을 언어 모델 안에서 먼저 흉내 내고, 그 결과를 에이전트 학습과 평가에 쓰겠다는 제안입니다.
공식 논문은 월드 모델을 현재 관측과 행동을 바탕으로 환경 동역학을 예측하는 모델로 정의합니다. Qwen 팀은 이 정의를 로보틱스나 비디오 공간 대신 언어 기반 에이전트 환경에 적용했습니다. 에이전트가 ls를 실행하면 다음 터미널 출력이 무엇인지, 브라우저에서 버튼을 누르면 DOM과 접근성 트리가 어떻게 바뀌는지, MCP 도구를 호출하면 어떤 응답이 돌아오는지 예측하는 방식입니다. 그래서 이번 모델은 "답변을 잘하는 챗봇"보다 "행동 뒤의 다음 관측값을 만들어내는 시뮬레이터"에 가깝습니다.
7개 환경을 한 모델에 넣은 이유
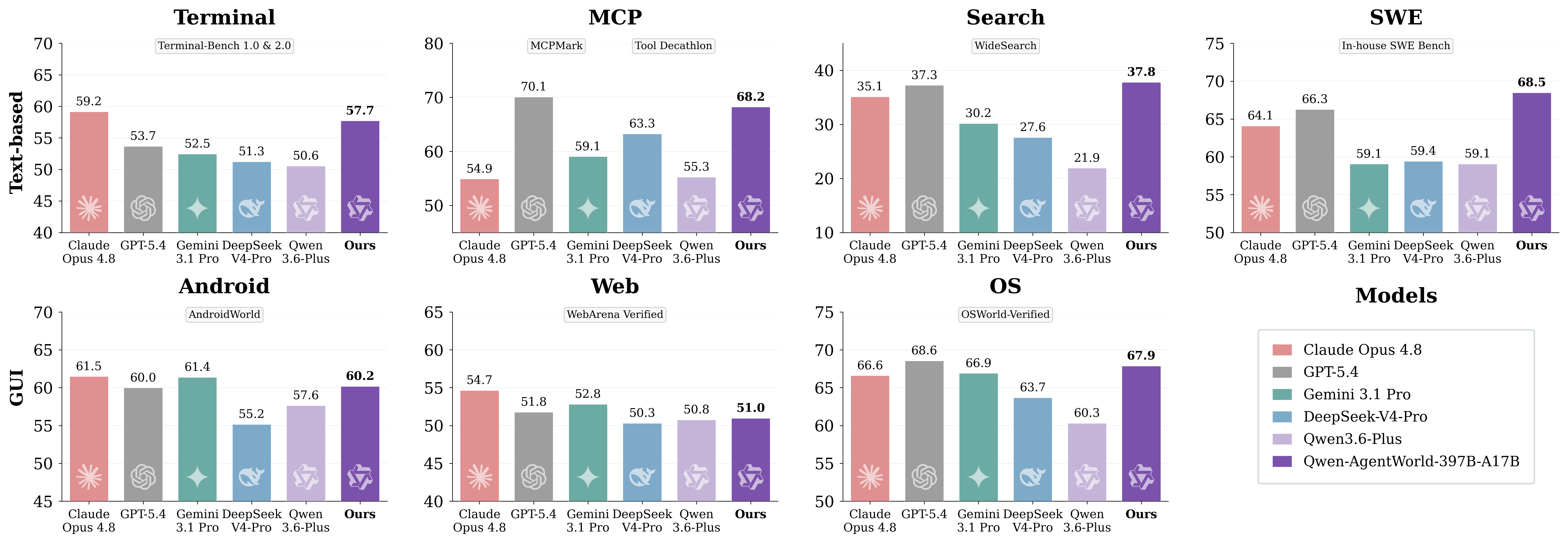
GitHub README는 Qwen-AgentWorld가 MCP, 검색, 터미널, 소프트웨어 엔지니어링, 안드로이드, 웹, OS까지 7개 영역을 하나의 모델로 다룬다고 설명합니다. 이 목록은 에이전트 제품이 실제로 부딪히는 표면과 거의 겹칩니다. 코딩 에이전트는 터미널과 저장소를 봅니다. 업무 에이전트는 검색과 웹 앱을 오갑니다. 모바일 에이전트는 안드로이드 화면과 접근성 정보를 읽습니다. 도구형 에이전트는 MCP 서버의 입력과 출력을 다룹니다.
중요한 부분은 "한 모델"이라는 설계입니다. 기존 벤치마크는 대체로 환경마다 분리됩니다. 터미널은 Terminal-Bench, 코드 수정은 SWE-Bench, 웹 조작은 WebArena나 OSWorld처럼 나뉩니다. Qwen 팀은 에이전트가 실제 제품에서 이런 경계를 매끄럽게 넘나든다고 봅니다. 사용자가 "웹에서 문서를 찾고, 저장소를 고친 뒤, 테스트를 돌리고, 결과를 보고하라"고 요청하면 검색, 웹, 파일, 터미널, 코드 이해가 한 작업 안에서 섞입니다. Qwen-AgentWorld는 그 혼합 환경의 다음 상태를 하나의 언어 모델이 예측하도록 훈련합니다.
학습 규모도 작지 않습니다. 논문 초록과 README는 7개 실제 환경에서 수집한 상호작용 궤적 1000만 건 이상을 사용했다고 밝힙니다. Hacker News의 한 사용자는 이 지점을 짚었습니다. 합성 데이터만 만든 것이 아니라 실제 물리 호스트, 가상 머신, 브라우저, 안드로이드 환경에서 에이전트 시스템을 계속 실행하고, 그 상호작용을 기록했다는 반응입니다. 이 설명이 맞다면 Qwen-AgentWorld의 재료는 단순 문서 말뭉치가 아니라 "행동과 관측의 로그"입니다.
사후 미세조정이 아니라 처음부터 환경 예측
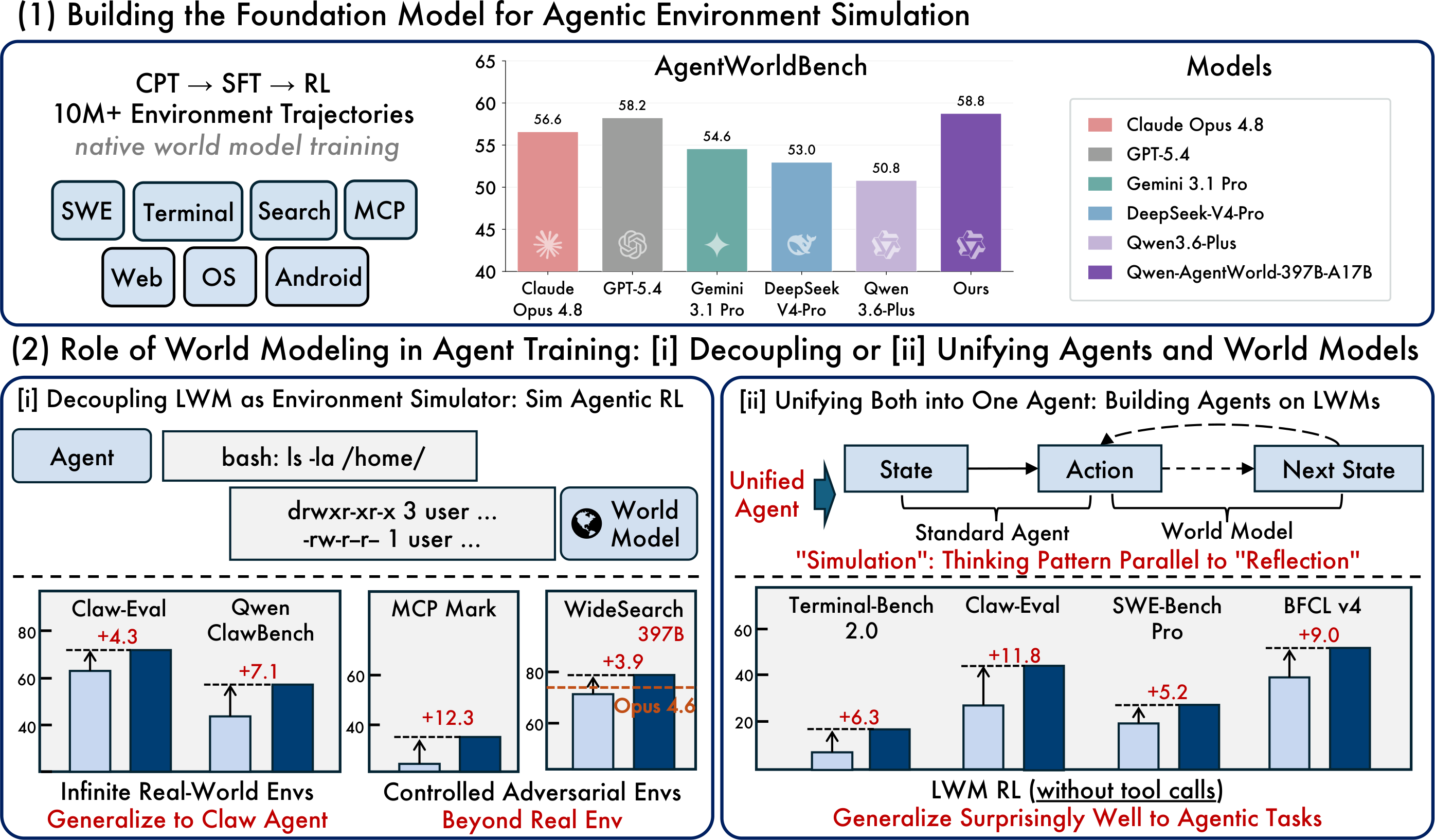
Qwen 팀은 Qwen-AgentWorld를 "native language world model"이라고 부릅니다. 여기서 native는 일반 LLM을 만든 뒤 조금 고쳐서 시뮬레이터로 쓰는 방식이 아니라, 계속 사전학습 단계부터 환경 모델링을 목표로 넣었다는 뜻입니다. 공식 설명의 파이프라인은 CPT, SFT, RL 세 단계입니다. CPT는 상태 전이 동역학과 전문 말뭉치로 환경 지식을 주입하고, SFT는 다음 상태 예측 추론을 활성화하며, RL은 규칙과 평가 기준을 섞은 보상으로 시뮬레이션 충실도를 높입니다.
이 차이는 실무에서 꽤 큽니다. 일반 챗봇에게 "터미널을 흉내 내라"고 시키면 그럴듯한 출력은 만들 수 있습니다. 그러나 에이전트 학습에 필요한 출력은 그럴듯함만으로 부족합니다. 명령 결과의 형식이 맞아야 하고, 이전 파일 상태와 모순되지 않아야 하며, 여러 단계 뒤에도 같은 환경으로 남아야 합니다. 브라우저 환경에서는 더 까다롭습니다. 버튼을 누른 뒤 접근성 트리와 URL, 보이는 텍스트, 다음 가능한 행동이 서로 맞아야 합니다. 환경 예측을 학습 목표로 일찍 넣었다는 주장은 이런 장기 일관성을 겨냥합니다.
공개된 35B 모델은 MoE 구조입니다. Hugging Face 모델 카드는 총 35B 파라미터 중 3B가 활성화되고, 컨텍스트 길이는 262,144 토큰이라고 적습니다. Qwen 팀은 128K 이상 컨텍스트를 유지하라고 권장합니다. 긴 상호작용 기록을 넣어야 다음 관측값을 일관되게 예측할 수 있기 때문입니다. vLLM과 SGLang 예시가 함께 제공되지만, 이 컨텍스트 길이는 작은 실험용 GPU 한 장으로 가볍게 다루기 어렵습니다. 공개 모델이라는 장점과 운영 비용이라는 질문이 함께 붙습니다.
점수보다 봐야 할 것은 평가 방식
Qwen 팀은 새 벤치마크 AgentWorldBench도 함께 공개했습니다. 이 벤치마크는 5개 프런티어 모델이 9개 기존 벤치마크에서 만든 실제 상호작용을 바탕으로 구성됐고, 예측된 환경 관측값을 형식, 사실성, 일관성, 현실성, 품질 다섯 축으로 평가합니다. README의 표에 따르면 Qwen-AgentWorld-397B-A17B는 전체 58.71점으로 GPT-5.4의 58.25점을 조금 앞섭니다. 공개된 Qwen-AgentWorld-35B-A3B는 56.39점으로, 같은 크기 기반 모델인 Qwen3.5-35B-A3B의 47.73점보다 8.66점 높다고 설명합니다.
이 숫자는 헤드라인으로 쓰기 쉽지만, 그대로 과장하면 안 됩니다. 첫째, 397B 모델은 현재 공개 가중치가 아니라 평가에 포함된 큰 모델입니다. 일반 개발자가 바로 내려받아 돌릴 수 있는 것은 35B-A3B입니다. 둘째, AgentWorldBench는 Qwen 팀이 함께 제안한 새 벤치마크입니다. 같은 팀이 만든 모델과 평가셋이기 때문에 독립 재현이 중요합니다. 셋째, 전체 점수 차이는 매우 작습니다. 58.71과 58.25의 차이는 "프런티어 모델을 압도했다"보다 "새 평가 축에서 비슷한 구간에 들어왔다"에 가깝게 읽어야 합니다.
HN 반응도 이 조심스러운 독해를 뒷받침합니다. 한 댓글은 논문 첫 그림의 막대 델타 표기가 잘못된 것처럼 보인다고 지적했습니다. 다른 사용자는 어느 표기인지 되물었고, 이어진 답변은 특정 막대의 증가 폭과 빨간 델타 수치가 맞지 않는다고 설명했습니다. 이것이 모델 자체를 무효화한다는 뜻은 아닙니다. 다만 방금 나온 논문과 저장소의 수치, 그림, 벤치마크 주장은 독립 실험과 수정 이력을 거쳐야 합니다. 개발자가 가져갈 결론은 "점수 1위"보다 "에이전트 환경 예측을 어떻게 평가할 것인가"입니다.
왜 실제 환경 대신 언어 환경인가
에이전트 학습에서 실제 환경은 가장 정확하지만 가장 비쌉니다. 웹 에이전트를 훈련하려면 실제 사이트 상태가 자주 바뀝니다. 로그인, 쿠키, 속도 제한, 개인정보, 봇 차단이 따라옵니다. 터미널과 OS 환경은 재현성이 낫지만, 악성 명령이나 파일 삭제 같은 위험을 막아야 합니다. 안드로이드 환경은 에뮬레이터와 앱 버전, 접근성 트리 변화가 문제입니다. MCP 도구는 서버마다 스키마와 실패 방식이 다릅니다. 실제 환경만 쓰면 학습 비용과 운영 위험이 학습 속도를 제한합니다.
언어 월드 모델은 이 병목을 줄이려 합니다. 에이전트가 어떤 행동을 했을 때 다음 관측값을 모델이 만들어주면, 수천 개 환경을 동시에 돌리는 것처럼 학습 데이터를 만들 수 있습니다. Qwen 팀은 OpenClaw의 out-of-distribution 환경 4000개에서 시뮬레이션 RL을 적용했을 때 Claw-Eval과 QwenClawBench가 각각 4.3점, 7.1점 올랐다고 설명합니다. MCP 영역에서도 통제된 시뮬레이션을 넣으면 Tool Decathlon과 MCPMark가 각각 3.7점, 12.3점 개선됐다고 주장합니다.
여기서 통제 가능성이 중요합니다. 실제 웹사이트나 터미널은 실패 조건을 마음대로 주입하기 어렵습니다. 반대로 언어 시뮬레이터는 "도구 응답이 느리다", "검색 결과가 일부 틀렸다", "권한 오류가 난다", "파일 시스템이 예상과 다르다" 같은 변형을 의도적으로 만들 수 있습니다. 좋은 에이전트는 정상 경로만 잘 따라가는 모델이 아니라, 실패한 도구 호출과 모순된 관측값을 만났을 때 안전하게 멈추거나 재시도하는 모델입니다. Qwen-AgentWorld의 실무 가치는 이런 실패 연습을 얼마나 현실적으로 만들 수 있느냐에 달려 있습니다.
에이전트 제품팀의 체크리스트
이 모델을 당장 제품에 붙이려는 팀은 세 가지를 먼저 봐야 합니다. 첫째, 출력 형식입니다. 터미널 출력, HTML, 접근성 트리, MCP 응답은 모두 후속 에이전트가 읽는 입력입니다. 한 글자만 틀려도 파서가 깨지거나, 다음 행동 선택이 달라질 수 있습니다. Qwen의 평가 축에 Format이 들어간 이유도 여기에 있습니다. 둘째, 장기 일관성입니다. 20턴 뒤에도 같은 파일이 같은 위치에 있어야 하고, 이전 클릭 결과가 다음 화면에 반영돼야 합니다. 단기 예측 점수만으로는 이 문제를 충분히 보장하지 못합니다.
셋째, 실제 환경과의 차이입니다. 시뮬레이터는 비용을 줄이지만, 시뮬레이터가 배운 편향도 함께 전달합니다. 언어 모델이 자주 본 터미널 관용 출력은 잘 흉내 낼 수 있어도, 회사 내부 CLI나 레거시 웹 앱의 이상한 오류는 틀릴 수 있습니다. Qwen-AgentWorld가 공개 모델과 벤치마크를 제공했다는 점은 연구와 실험에는 장점입니다. 그러나 사내 도구를 대상으로 쓰려면 자체 궤적 수집, 검증셋, 실패 케이스 주입이 필요합니다. "언어로 만든 샌드박스"는 실제 샌드박스를 완전히 대체하기보다, 위험한 시행착오를 줄이는 중간층으로 보는 편이 맞습니다.
이 발표는 최근 코딩 에이전트 경쟁과도 맞물립니다. OpenAI Codex, Claude Code, Jules, Copilot 계열 제품은 모두 실행 환경을 더 오래 붙잡고, 사용자가 돌아오기 전에 작업을 진행하려 합니다. 그럴수록 학습과 평가의 병목은 모델 답변 품질에서 실행 로그 품질로 옮겨갑니다. 어떤 명령을 실행했는지, 결과가 무엇이었는지, 실패를 어떻게 복구했는지, 테스트를 어떻게 믿었는지가 제품 신뢰를 좌우합니다. Qwen-AgentWorld는 그 로그를 단순 기록물이 아니라 다음 세대 에이전트를 훈련시키는 환경 모델 재료로 읽습니다.
월드 모델이라는 단어를 좁혀 읽기
올해 "월드 모델"이라는 말은 너무 넓게 쓰이고 있습니다. SANA-WM은 카메라 궤적을 따라 1분짜리 720p 비디오 세계를 만들려 했고, Reactor는 실시간 생성 비디오 API를 내세웠고, Google Genie 계열은 탐험 가능한 시각 공간을 이야기했습니다. Qwen-AgentWorld의 세계는 그보다 건조합니다. 색과 질감보다 JSON, HTML, 터미널 출력, 접근성 트리, 도구 응답이 중요합니다. 그렇지만 에이전트 개발자에게는 이 건조한 세계가 더 직접적일 수 있습니다. 오늘의 에이전트는 대부분 픽셀 공간보다 소프트웨어 표면에서 일하기 때문입니다.
따라서 이번 뉴스의 질문은 "Qwen이 가장 강한 모델을 냈나"가 아닙니다. 더 정확한 질문은 "에이전트가 실패를 배우는 장소를 실제 환경 밖에도 만들 수 있나"입니다. 답이 예라면 개발팀은 더 많은 실패 케이스를 싸게 만들 수 있습니다. 답이 아니라면 에이전트는 여전히 비싼 실제 샌드박스에서 부딪히며 배워야 합니다. Qwen-AgentWorld는 그 사이의 첫 공개 실험 중 하나입니다. 모델 가중치와 벤치마크가 같이 나왔으니, 이제 필요한 것은 독립 재현, 다른 환경에서의 실패 사례, 그리고 실제 에이전트 제품에 넣었을 때 비용이 얼마나 줄어드는지에 대한 숫자입니다.