vLLM Micro-Agent 공개, 모델 API 안으로 들어간 라우터 루프
vLLM Semantic Router가 Micro-Agent를 공개했습니다. OpenAI 호환 API 뒤에서 라우터가 비용·품질·관측성을 제어하는 방식입니다.
- 무슨 일: vLLM Semantic Router 팀이 2026년 6월 29일
Micro-Agent레시피를 공개했습니다.- 사용자는
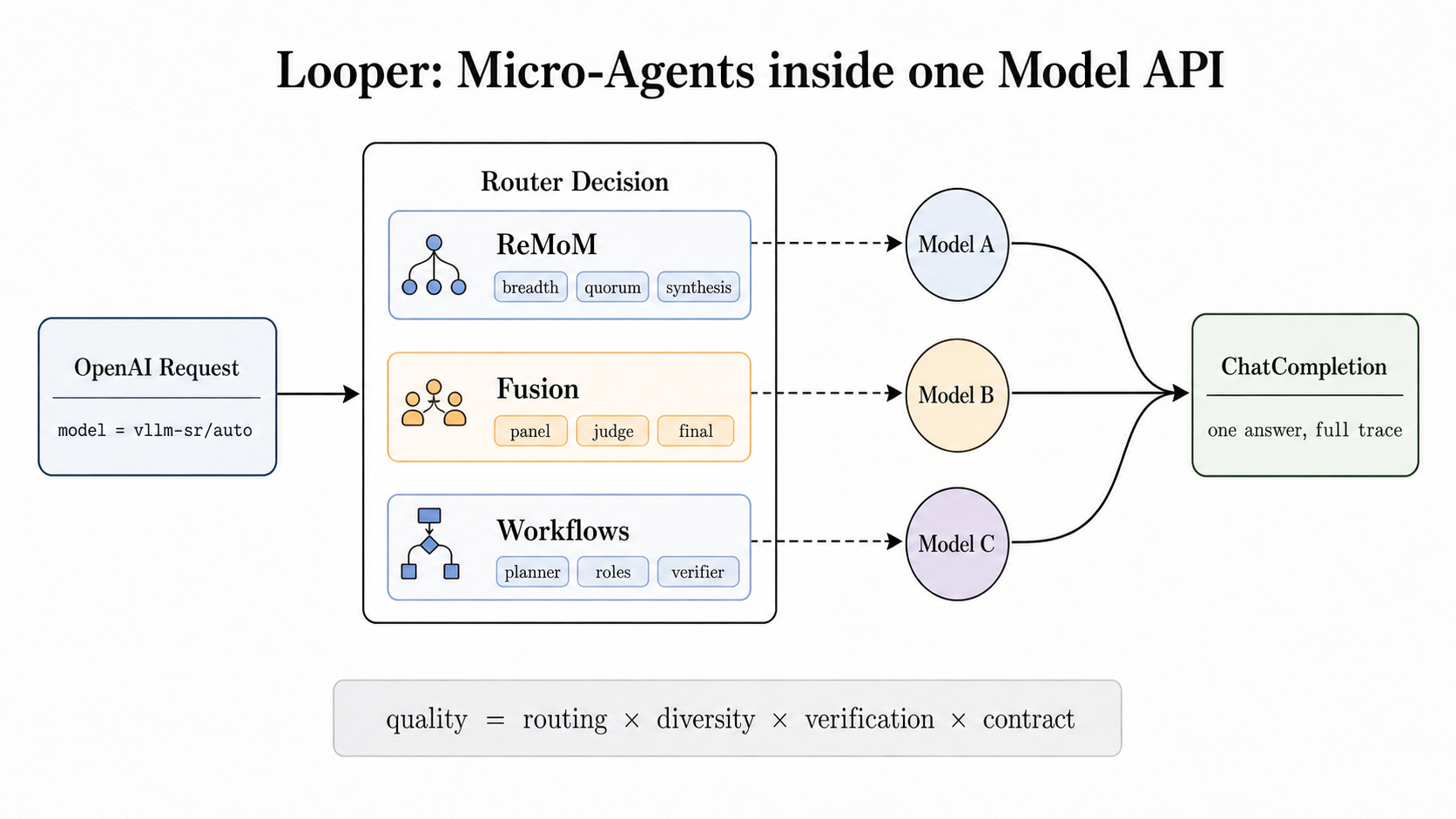
vllm-sr/auto라는 모델 하나를 호출하지만, 내부 라우터는 작업 모양에 맞춰 여러 모델 호출과 검증 루프를 실행합니다.
- 사용자는
- 숫자: 공식 scorecard에서
VSR Closed는 LiveCodeBench 92.6, GPQA-Diamond 96.0, Humanity's Last Exam 50.0을 기록했습니다. - 주의점: 라우터가 품질을 만들수록 trace, 비용 한도, 실패 정책이 모델 선택만큼 중요한 운영 항목이 됩니다.
vLLM Semantic Router 팀이 2026년 6월 29일 Micro-Agent를 공개했습니다. 제목에는 "프런티어 모델을 이긴다"는 표현이 붙었지만, 이 글을 단순 벤치마크 발표로 읽으면 핵심을 놓칩니다. vLLM의 주장은 새 체크포인트가 아니라 라우터입니다. 사용자는 OpenAI 호환 API에 vllm-sr/auto라는 모델 이름을 넣고, 라우터는 그 뒤에서 작업 신호, 위험도, 비용, 지연 시간, 출력 계약을 보고 작은 협업 루프를 고릅니다.
전날 devlery는 Sakana Fugu Ultra를 다뤘습니다. Sakana는 여러 프런티어 모델과 전문 에이전트 조율을 하나의 상용 모델 표면 뒤에 숨겼습니다. vLLM 글은 같은 사건을 다른 방향에서 잡습니다. 모델 선택과 합성을 특정 상용 엔드포인트 안에 넣는 대신, 오픈 서빙 계층이 실행할 수 있는 레시피로 만들자는 제안입니다. 이 차이 때문에 이번 뉴스는 또 다른 모델 출시가 아니라, 모델 API와 에이전트 하네스의 경계가 움직이는 사건입니다.
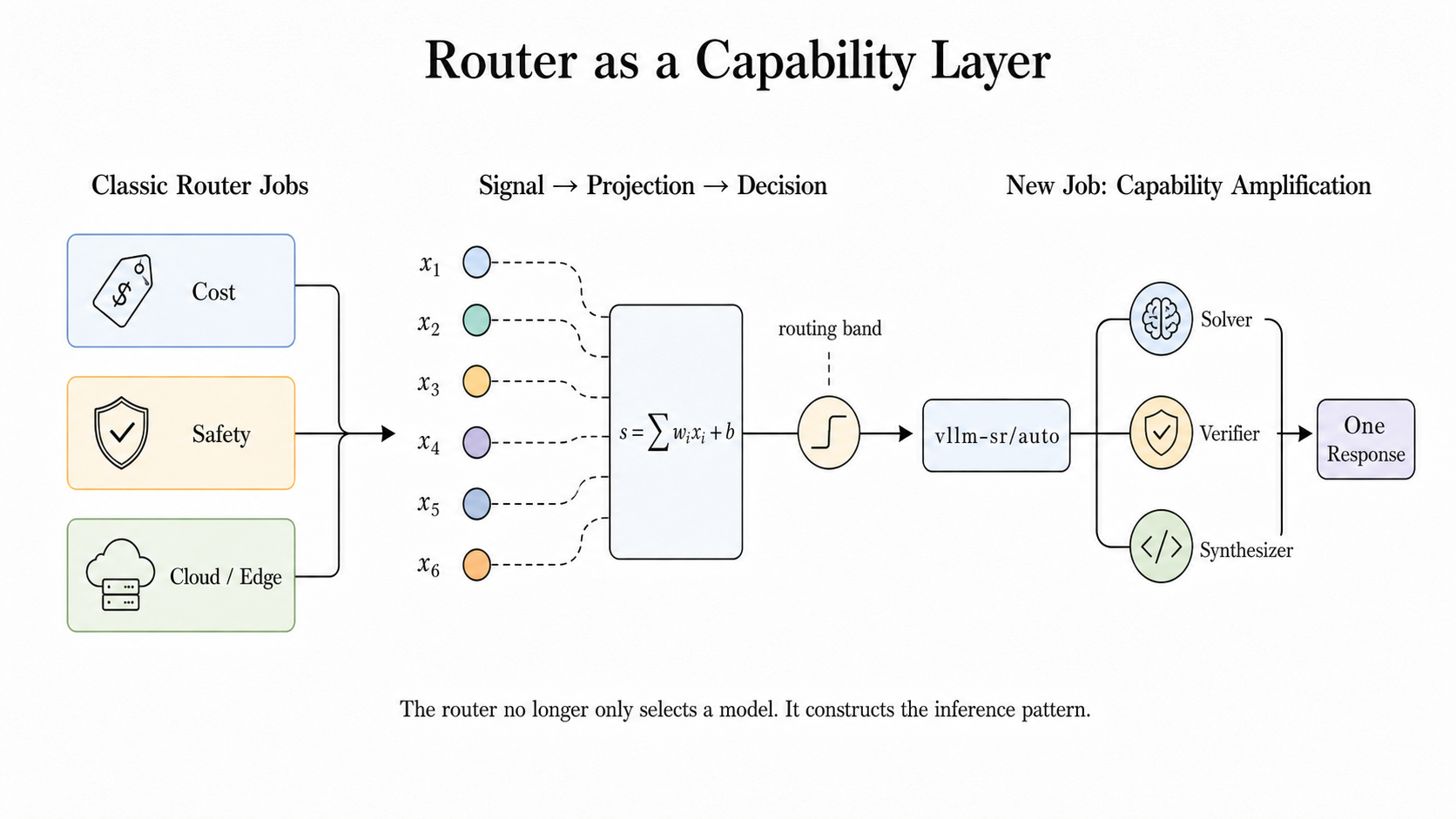
vLLM이 말하는 라우터의 첫 역할은 익숙합니다. 요청을 싼 모델로 보낼지, 강한 모델로 보낼지, 로컬 모델로 둘지, 클라우드 모델로 올릴지 결정합니다. 운영자는 이 계층에서 비용, 지연 시간, 안전 정책, 제공자 장애 대응을 다뤄 왔습니다. 이번 글은 그 역할을 한 단계 밀어 올립니다. 라우터가 모델을 고르는 데서 멈추지 않고, 여러 호출을 묶어 하나의 더 강한 응답을 만들 수 있다는 주장입니다.
공식 글은 이 구조를 "bounded collaboration inside the serving layer"라고 부릅니다. 한국어로 풀면 서빙 계층 안의 제한된 협업입니다. 제한이라는 단어가 중요합니다. vLLM이 공개한 Micro-Agent는 자유롭게 셸을 열고 파일을 수정하는 범용 자율 에이전트가 아닙니다. 라우터가 정한 후보 모델, 동시성 한도, 정족수, timeout, 오류 정책, 출력 형식 안에서만 움직입니다. 그래서 애플리케이션이 거대한 에이전트 그래프를 직접 만들지 않아도, 서빙 계층에서 작은 협업을 실행할 수 있다는 설명입니다.
기본 호출 표면은 그대로입니다. 공식 예시는 model 값에 vllm-sr/auto를 넣고 messages를 보내는 일반 채팅 완성 요청입니다. 라우터는 내부에서 요청을 분류하고, 단일 모델 경로로 끝낼지, Confidence, Ratings, ReMoM, Fusion, Workflows 중 하나를 실행할지 결정합니다. 응답은 다시 하나의 OpenAI 호환 응답으로 접힙니다. 클라이언트 입장에서는 모델 이름 하나를 호출했지만, 운영자는 그 모델 이름 뒤의 레시피를 바꿀 수 있습니다.
Confidence는 비용을 아끼는 순차 승격 루프입니다. 먼저 더 작거나 싼 후보에게 질문하고, confidence 신호가 기준을 넘으면 즉시 반환합니다. 점수가 낮으면 더 강한 후보로 승격합니다. 이때 confidence는 토큰 수준 로그확률, margin, 자기 검증, entailment verifier 같은 신호에서 올 수 있습니다. 기존 애플리케이션 코드에서도 비슷한 재시도를 만들 수 있지만, vLLM은 threshold, stopping condition, failure behavior를 라우터 정책으로 드러내겠다고 말합니다.
Ratings는 병렬 실행을 통제합니다. 여러 후보를 동시에 실행하되 max_concurrent 같은 한도로 fan-out을 막고, 성공 응답을 rating-aware weight로 집계합니다. 운영자가 이미 후보별 품질 신호를 갖고 있거나, A/B 평가와 앙상블 전략을 서빙 경로에 붙이고 싶을 때 맞는 패턴입니다. 모든 요청을 무제한으로 여러 모델에 보내는 방식이 아니라, 동시성 한도와 실패 정책을 가진 실행 레시피라는 점이 제품 운영에서 중요합니다.
ReMoM은 추론 분산이 큰 작업을 겨냥합니다. 여러 reasoning attempt를 펼치고, 최소 성공 정족수를 기다린 뒤, 합성 모델이 증거를 합쳐 출력 계약을 복구합니다. synthesis가 실패해도 앞선 worker가 유효한 증거를 만들었다면 최선의 유효 증거로 fallback할 수 있습니다. 긴 수학 추론, 정확한 답 형식, 코드 출력처럼 마지막 형식이 무너지면 전체 요청이 실패하는 작업에서 쓸 수 있는 설계입니다.
Fusion은 평균 답변보다 불일치를 신호로 봅니다. 독립 모델 응답을 panel evidence로 모으고, judge가 일치, 충돌, 고유 통찰을 본 뒤 finalizer가 하나의 답을 만듭니다. 어려운 객관식, 장문 전문가 판단, 정답 형식이 엄격한 문제에서 단일 모델의 자신감 있는 오답을 줄이는 방식입니다. 최근 OpenRouter도 Fusion router를 공개했기 때문에, 이 패턴은 vLLM만의 고립된 아이디어라기보다 라우터 시장의 공통 실험으로 볼 수 있습니다.
Workflows는 가장 에이전트에 가깝습니다. planner가 허용된 worker 모델만 고르고, 계획은 검증되며, 각 단계는 최대 단계 수, 병렬성, timeout, 오류 정책으로 묶입니다. SWE 계열 작업에서는 planner, patcher, verifier, finalizer를 표현할 수 있습니다. 다만 vLLM 글이 강조하는 부분은 "무제한 자율 에이전트"가 아니라 "인프라가 지배하는 제한형 역할 시스템"입니다. 이 구분은 프로덕션에서 중요합니다.
| 레시피 | 실행 방식 | 운영자가 보는 항목 |
|---|---|---|
| Confidence | 싼 후보부터 시작해 낮은 점수에서만 승격 | threshold, 승격 비용, 조기 종료율 |
| Ratings | 정해진 동시성 안에서 후보를 병렬 평가 | 동시성 한도, 후보별 품질 신호, 실패 집계 |
| ReMoM | 여러 추론 시도와 정족수 뒤 최종 합성 | 정족수, synthesis 실패, 출력 계약 보존 |
| Fusion | 불일치를 judge와 finalizer의 증거로 사용 | panel 구성, judge 편향, trace 압축 방식 |
| Workflows | planner와 worker 역할을 제한된 단계로 실행 | 허용 모델, 최대 단계, timeout, 오류 정책 |
공식 scorecard는 이 주장을 숫자로 보여주려는 장치입니다. vLLM은 VSR Closed가 LiveCodeBench 2025년 1-4월 세트에서 92.6, GPQA-Diamond에서 96.0, Humanity's Last Exam에서 50.0을 기록했다고 적었습니다. 같은 표의 reference row에는 Fugu Ultra가 각각 92.0, 95.5, 50.0으로 놓였습니다. VSR Hybrid는 Humanity's Last Exam에서 47.1을 기록했고, GLM-5.2 40.5, Qwen3.7 Max 41.4, GPT-5.5 41.4와 비교됐습니다.
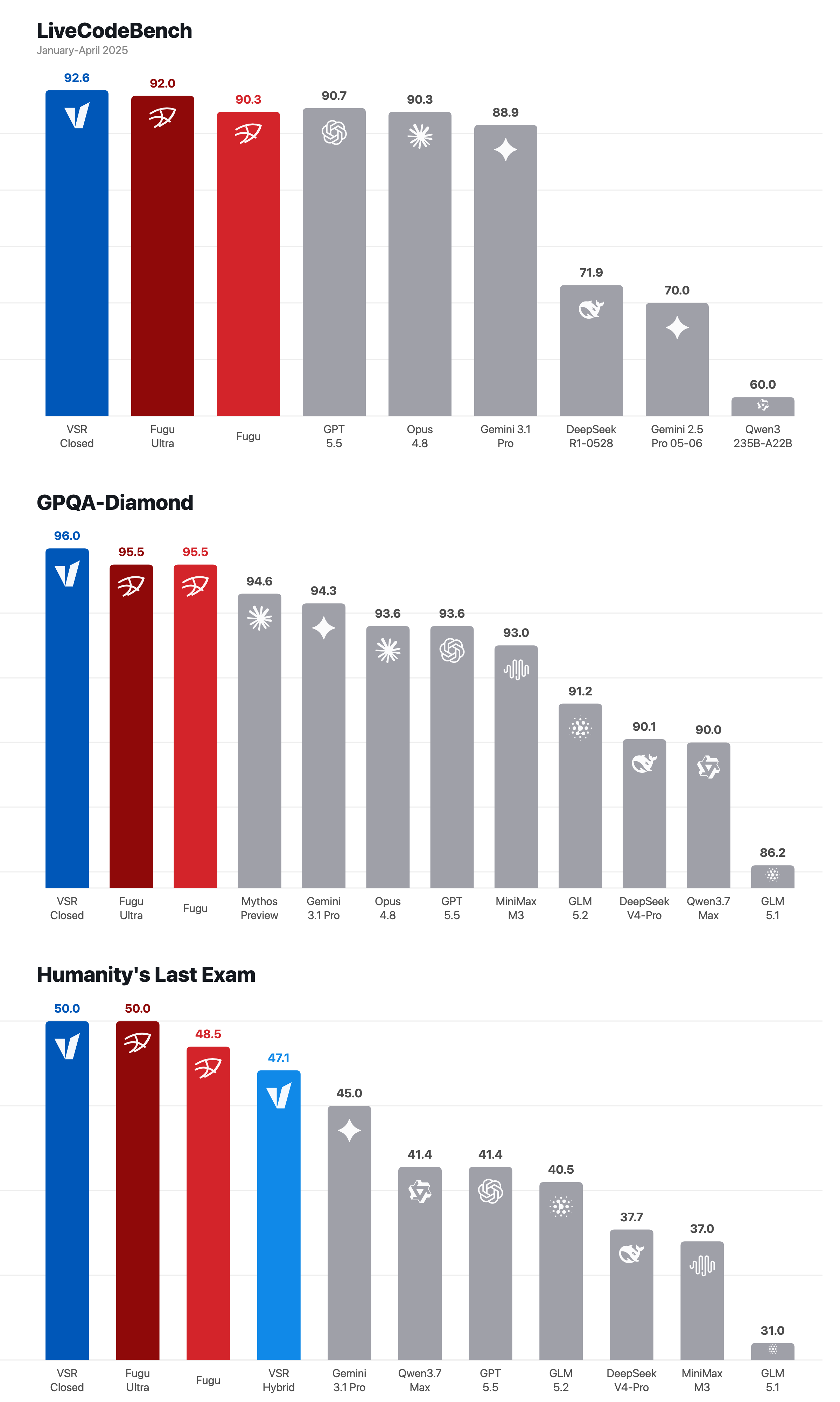
이 숫자는 조심해서 읽어야 합니다. vLLM 글도 scorecard를 "proof, not the whole story"라고 설명합니다. 모든 요청에 가장 큰 closed-model 루프를 돌리라는 뜻이 아닙니다. 제품 주장은 더 좁습니다. 라우터가 owned collaboration을 실행하면, 그 아래 개별 모델 호출보다 강한 모델 identity를 만들 수 있고, 클라이언트 통합은 그대로 둘 수 있다는 것입니다. 따라서 비교 대상은 특정 체크포인트 하나가 아니라, 라우터 레시피와 관측 가능한 운영 정책입니다.
이번 발표가 개발팀에 주는 첫 질문은 비용입니다. Confidence처럼 저렴한 모델에서 시작해 어려운 요청만 승격하는 구조는 매력적입니다. 하지만 실제 비용은 threshold가 얼마나 보수적인지, confidence 신호가 얼마나 잘 보정됐는지, fallback이 얼마나 자주 일어나는지에 따라 바뀝니다. 단일 모델 가격표만 보면 계산이 쉽지만, 라우터 루프에서는 "성공한 요청 1건당 비용"과 "실패 후 재시도 비용"을 함께 봐야 합니다.
두 번째 질문은 지연 시간입니다. Ratings와 Fusion은 여러 후보를 병렬로 실행하므로 품질을 올릴 수 있지만, 가장 느린 후보와 judge, finalizer가 꼬리 지연 시간을 만들 수 있습니다. ReMoM은 최소 성공 정족수를 기다리고 합성을 거칩니다. Workflows는 단계 수와 timeout이 늘어날 수 있습니다. 모델 API가 하나의 응답으로 보인다고 해서, 내부 실행 시간이 단일 모델 호출과 같다는 뜻은 아닙니다. 운영자는 route label별 p95와 p99를 따로 봐야 합니다.
세 번째 질문은 관측성입니다. 라우터가 어떤 레시피를 골랐는지, 어떤 후보가 실패했는지, finalizer가 어떤 증거를 썼는지 trace가 남지 않으면 장애 분석은 어려워집니다. HN 댓글에서도 비슷한 우려가 나왔습니다. 모델이 next token을 고르는 대상이라면 호출자가 어느 정도 행동을 추론할 수 있지만, 더 많은 판단이 facade 뒤로 들어가면 더 큰 추상화에 합성하기 어려워진다는 지적입니다. vLLM 글은 trace를 라우터가 이미 갖고 있는 자산으로 말하지만, 실제 도입에서는 trace export와 보존 정책이 구매 질문이 됩니다.
이 지점에서 전날 Sakana Fugu와 차이가 분명해집니다. Sakana는 조율 자체를 상용 모델의 차별점으로 팔고, 어떤 기초 모델을 골랐는지와 조율 방식은 공개하지 않는다고 설명했습니다. vLLM은 조율을 서빙 레시피와 라우터 정책으로 옮기려 합니다. 물론 vLLM 레시피도 실제 운영에서 모든 내부 판단을 완전히 투명하게 만들지는 못합니다. 그러나 추상화의 위치가 다릅니다. 한쪽은 모델 제공자 제품이고, 다른 쪽은 모델 제공자들을 감싸는 인프라입니다.
에이전트 제품을 만드는 팀에는 책임 경계가 달라집니다. 지금까지 많은 팀은 애플리케이션 코드에서 planner, tool caller, verifier, retry loop를 직접 만들었습니다. 그 방식은 세밀한 통제를 주지만, 모델별 가격, timeout, credentials, provider failure, trace schema가 애플리케이션으로 흘러들어옵니다. vLLM Micro-Agent 접근은 이 일부를 라우터로 옮깁니다. 앱은 여전히 업무 로직과 사용자 권한을 소유하지만, 모델 협업의 예산과 실패 정책은 인프라가 맡을 수 있습니다.
다만 라우터가 에이전트 루프를 맡는다고 해서 애플리케이션 책임이 사라지지는 않습니다. 출력 계약은 여전히 제품 쪽 요구사항입니다. 코드 생성이면 테스트가 필요하고, 고객지원 답변이면 정책 검사가 필요하며, 보안 분석이면 민감 정보 처리 기준이 필요합니다. 라우터가 finalizer를 돌려도 최종 산출물이 업무 정책을 통과했는지는 애플리케이션이 검증해야 합니다. Micro-Agent는 제품 검증을 대체하는 기능이 아니라, 모델 호출을 더 구조적으로 실행하는 계층입니다.
보안팀은 credentials와 data boundary를 봐야 합니다. 라우터는 모델 alias, provider policy, credentials, cost metadata를 알고 있어야 합니다. 여러 제공자를 섞는 순간 민감 데이터가 어느 백엔드로 갔는지, 어떤 provider failure에서 fallback이 작동했는지, 어떤 route가 더 강한 필터를 탔는지 기록해야 합니다. 안전 정책을 라우터에서 실행한다는 말은 좋아 보이지만, 감사 로그 없이 실행된 정책은 사후 설명이 어렵습니다.
오픈소스 생태계에는 다른 함의도 있습니다. vLLM은 이미 추론 서빙에서 널리 쓰이는 기반입니다. Semantic Router가 성숙하면, 모델 제공자별 SDK를 애플리케이션마다 바꾸는 대신, 라우터 쪽에서 모델 풀, 레시피, provider fallback을 바꾸는 운영 방식이 더 자연스러워질 수 있습니다. 이 경우 "어떤 모델이 최고인가"보다 "어떤 라우터 설정이 우리 작업군에서 성공당 비용을 낮추는가"가 더 중요한 질문이 됩니다.
HN의 초기 반응도 이 축을 건드립니다. Algolia API 기준 글은 2026년 6월 30일 00:59:25Z 조회 시점에 50점과 댓글 17개를 기록했습니다. 한 댓글은 이 접근이 이기종 추론 하드웨어를 더 잘 쓰게 할 수 있다고 봤습니다. 다른 댓글은 LLM이 점점 상품화되고, harness와 router의 결합이 중요해진다고 읽었습니다. 반대로 facade 뒤로 판단이 들어가면 모델 행동을 충분히 이해하고 합성하기 어렵다는 우려도 있었습니다. OpenRouter Fusion과 Sakana Fugu를 비교하는 반응도 나왔습니다.
이 논쟁은 용어 문제로도 이어집니다. vLLM 글은 "frontier model"이 체크포인트와 시스템 경계라는 두 뜻을 갖기 시작했다고 말합니다. 표현은 다소 과감하지만, 시장의 방향은 실제로 그쪽으로 움직입니다. 사용자가 보는 모델 이름은 하나인데, 그 뒤에는 라우터, 캐시, 필터, judge, verifier, fallback, trace가 붙습니다. 제품이 좋아질수록 "모델명"은 더 적은 정보를 주고, 운영자가 관리하는 레시피와 정책이 더 많은 정보를 줍니다.
벤치마크 수치도 그 관점에서 봐야 합니다. LiveCodeBench 92.6이나 GPQA-Diamond 96.0은 강한 홍보 숫자입니다. 그러나 실제 제품 도입에서는 같은 레시피가 우리 입력 분포에서 어떤 실패를 내는지가 더 중요합니다. 공식 표는 닫힌 모델 백엔드와 혼합 백엔드의 가능성을 보여주지만, 각 작업군의 표본, judge 설정, 비용 한도, 지연 시간은 별도로 확인해야 합니다. 특히 Humanity's Last Exam처럼 exact answer pressure가 큰 과제와 실제 고객지원 챗봇은 실패 비용이 다릅니다.
개발팀이 바로 해볼 수 있는 실험은 작게 시작하는 편이 낫습니다. 첫째, 기존 단일 모델 경로와 vllm-sr/auto 경로를 같은 요청 로그로 비교합니다. 둘째, route label, 레시피 이름, 후보 수, 동시성, fallback 여부, 출력 검증 결과를 한 행에 남깁니다. 셋째, 평균 토큰 비용이 아니라 성공당 비용과 p95 지연 시간을 봅니다. 넷째, 사람이 재검토한 실패를 wrong answer, format broken, timeout, policy blocked처럼 분리합니다. 그래야 라우터가 품질을 만든 것인지, 비용을 옮긴 것인지 판단할 수 있습니다.
벤더 선택 기준도 달라집니다. 모델 API 제공자에게는 "어떤 모델을 쓰나요"만 묻기 어렵습니다. "라우터가 어떤 신호로 승격하나요", "fallback 때 데이터가 어느 제공자로 가나요", "judge와 finalizer의 로그를 export할 수 있나요", "레시피별 비용 한도를 둘 수 있나요", "출력 계약 실패를 어떻게 노출하나요"가 뒤따라야 합니다. vLLM 같은 오픈 서빙 계층을 직접 운영한다면 이 질문의 답을 내부 정책으로 만들 수 있지만, 그만큼 운영 책임도 커집니다.
이번 발표의 실무 결론은 "프런티어 모델을 대체할 새 라우터가 나왔다"가 아닙니다. 더 정확한 문장은 "모델 성능 경쟁의 단위가 체크포인트에서 서빙 레시피로 넓어지고 있다"입니다. Sakana Fugu는 그 변화를 상용 모델 표면으로 보여줬고, vLLM Semantic Router는 같은 변화를 오픈 인프라 레시피로 밀어 넣습니다. 개발자에게 중요한 것은 어느 쪽이 더 멋진 이름을 붙였는지가 아닙니다. trace를 볼 수 있는지, 비용을 묶을 수 있는지, 실패를 재현할 수 있는지가 도입 기준입니다.
vLLM Micro-Agent는 에이전트가 애플리케이션 밖으로 사라진다는 뜻이 아닙니다. 오히려 에이전트 루프의 일부가 더 낮은 인프라 계층으로 내려간다는 신호입니다. 제품은 업무 맥락과 권한, 검증을 계속 소유하고, 라우터는 모델 협업의 예산과 topology, fallback을 소유합니다. 이 역할 분리가 잘 작동하면 모델 교체와 레시피 개선이 클라이언트 통합을 깨지 않습니다. 반대로 trace와 정책이 흐리면, 모델 API 하나가 더 큰 블랙박스가 됩니다.
그래서 이번 뉴스의 체크리스트는 간단합니다. vllm-sr/auto 같은 모델 이름 하나에 끌리기보다, 그 뒤에서 어떤 레시피가 언제 실행되는지 봐야 합니다. scorecard의 최고점보다 우리 작업군의 성공당 비용을 봐야 합니다. "에이전트"라는 이름보다 제한 조건, 출력 계약, 관측성을 봐야 합니다. 라우터가 모델을 고르는 계층에서 모델을 만드는 계층으로 이동한다면, 다음 AI 인프라 경쟁은 더 좋은 체크포인트뿐 아니라 더 설명 가능한 라우터에서 갈릴 것입니다.