100개 모델이 Pixel TPU로 간다, 온디바이스 AI의 좁은 문
Google Tensor SDK Beta는 Pixel 10 TPU를 LiteRT와 100개 이상 모델 정원으로 열며 온디바이스 AI 배포 병목을 겨냥합니다.
- 무슨 일: Google Tensor ML SDK가
Beta로 올라가며 Pixel 10 TPU용 LiteRT 배포 경로가 열렸습니다.- 지원 기기는 Pixel 10, 10 Pro, 10 Pro XL, 10 Pro Fold이며 Google은 100개 이상 모델과 Gemma 3 1B를 함께 제시했습니다.
- 의미: 온디바이스 AI가 OS 기본 기능을 넘어 외부 Android 앱의 제품 기능으로 들어갈 수 있는 첫 공개 통로입니다.
- 주의점: Pixel 10 한정, 모델별 라이선스, TPU fallback, Play 배포 체계가 실제 도입의 병목입니다.
- 핵심은 "모델을 폰에서 돌릴 수 있다"가 아니라 컴파일, 배포, 실행, 대체 경로를 앱 운영 흐름에 넣는 일입니다.
2026년 5월 19일 Google Developers Blog에 올라온 Google Tensor SDK Beta with LiteRT 발표는 Google I/O의 거대한 Gemini 뉴스들 사이에서는 비교적 작게 보일 수 있습니다. 하지만 Android 앱 개발자와 온디바이스 AI 팀에게는 꽤 직접적인 변화입니다. Google Tensor ML SDK가 Experimental Access Program에서 Beta로 올라가면서, 외부 개발자가 Pixel 10 계열 기기의 Tensor TPU를 겨냥해 모델을 변환하고, 컴파일하고, 배포하고, 실행하는 공식 경로가 더 넓게 열렸기 때문입니다.
이 발표의 핵심은 단순히 "Pixel에서도 AI 모델을 돌릴 수 있다"가 아닙니다. Google은 이미 Pixel 안에 Pro Zoom, Add Me, Voice Translate, Call Notes 같은 온디바이스 AI 기능을 넣어 왔습니다. 차이는 누가 그 하드웨어를 쓸 수 있느냐입니다. 지금까지 Pixel의 AI 기능은 대체로 Google이 직접 만든 제품 경험에 가까웠습니다. 이번 베타는 외부 앱이 Pixel의 TPU를 제품 기능의 일부로 다루기 시작할 수 있는 경로를 제시합니다.
Google은 이번 베타가 두 가지를 연다고 설명합니다. 첫째는 LiteRT와 연결된 통합 개발 워크플로입니다. 둘째는 Tensor TPU에서 최적 실행하도록 준비된 100개 이상의 모델 정원입니다. 여기에 Gemma 3 1B 같은 생성형 모델, Function Gemma와 EmbeddingGemma 같은 작은 언어 모델 계열, vision과 audio 모델이 붙습니다. 이 조합은 온디바이스 AI가 단순 데모가 아니라 앱 기능의 배포 단위로 이동하고 있다는 신호입니다.
왜 Pixel TPU 접근이 뉴스인가
온디바이스 AI는 오래된 약속입니다. 개인정보를 서버로 보내지 않고, 네트워크 지연 없이 반응하고, 사용자가 비행기 모드에 있어도 기능이 동작한다는 장점은 명확합니다. 문제는 늘 개발자 경험이었습니다. 모델은 PyTorch에서 훈련되고, 모바일 앱은 Kotlin이나 Java, Swift로 배포되며, 실제 실행은 CPU, GPU, NPU, TPU, Neural Engine처럼 각기 다른 가속기 위에서 일어납니다. 이 사이를 연결하는 컴파일러, 런타임, 드라이버, 모델 포맷, 앱 배포 정책이 조금만 어긋나도 제품 기능은 깨집니다.
Google은 LiteRT를 이 간극을 줄이는 공통 프레임워크로 밀고 있습니다. 공식 발표에 따르면 LiteRT는 고성능 온디바이스 ML 배포를 위한 Google의 edge framework이며, 저수준의 벤더별 SDK, 컴파일러, 런타임을 개발자-facing API로 추상화합니다. Tensor ML SDK가 LiteRT와 통합되면서 개발자는 PyTorch 또는 TFLite 모델을 LiteRT Torch로 변환하고, Tensor TPU용 binary로 컴파일하고, Play Feature Delivery와 Play for On-device AI의 AI Packs를 통해 runtime과 모델 파일을 배포하고, LiteRT Runtime으로 TPU inference를 호출하는 흐름을 갖게 됩니다.
이 흐름은 복잡해 보이지만, 복잡함 자체가 뉴스입니다. 클라우드 API를 부르는 AI 기능은 서버 쪽 모델 엔드포인트와 인증, 과금, latency budget을 관리하면 됩니다. 온디바이스 AI 기능은 앱 패키징, 기기별 가속기, 런타임 호환성, 모델 크기, 배터리, fallback, Play 배포 정책까지 함께 다룹니다. Google이 이번 베타에서 컴파일, 배포, 실행을 한 문단으로 묶어 설명한 것은 온디바이스 AI가 "모델 파일 하나 넣기" 수준을 넘어섰다는 뜻입니다.
100개 모델보다 중요한 것은 모델 정원의 성격입니다
Google AI Edge의 Model Garden 문서는 이 발표를 더 구체적으로 보여줍니다. 문서는 vision, text, audio 기능을 위한 machine learning 모델 모음을 제공하며, Google Tensor SDK와 함께 Pixel 기기에서 온디바이스 성능을 내도록 최적화됐다고 설명합니다. 나열된 범위는 depth estimation, face reconstruction, image and text understanding, image classification, image segmentation, object detection, pose estimation, speech recognition, super resolution, text classification까지 넓습니다.
개발자가 여기서 봐야 할 것은 "100개 이상"이라는 숫자만이 아닙니다. 모델 정원에는 classic ML 모델과 생성형 모델이 섞여 있습니다. 예를 들어 이미지 분류에는 EfficientNet, MobileNet, ResNet 계열이 보이고, speech recognition에는 wav2vec2 같은 계열이 등장합니다. 발표문은 생성형 AI 모델로 Gemma 3 1B를 언급하고, 앱 interaction을 위한 Function Gemma와 semantic feature를 위한 EmbeddingGemma도 예로 듭니다.
이 조합은 온디바이스 AI 앱의 실제 구조와 맞닿아 있습니다. 사용자는 "휴대폰 안에서 챗봇 하나 돌리기"만 원하는 것이 아닙니다. 카메라 프레임에서 물체를 알아보고, 이미지를 분할하고, 음성을 낮은 지연으로 받아 적고, 짧은 로컬 명령을 function call로 바꾸고, 사용자의 콘텐츠를 의미 벡터로 정리하는 기능이 섞입니다. 큰 LLM 하나가 모든 일을 하는 클라우드 설계와 달리, 모바일 온디바이스 AI는 작은 모델 여러 개가 feature pipeline을 이룹니다.
| 계층 | Google이 제시한 구성 | 제품 의미 |
|---|---|---|
| 모델 | 100+ classic ML, Gemma 3 1B, Function Gemma, EmbeddingGemma | 챗봇보다 작은 기능 모델이 앱 곳곳에 들어갑니다. |
| 컴파일 | LiteRT Torch로 PyTorch 또는 TFLite 모델 변환 | 연구 모델을 Pixel TPU용 binary로 옮기는 통로입니다. |
| 배포 | Play Feature Delivery, Play for On-device AI, AI Packs | 모델과 runtime이 앱 릴리스 운영의 일부가 됩니다. |
| 실행 | LiteRT Runtime, TPU 우선, CPU/GPU fallback | 기기 상태와 호환성에 따라 서비스 품질을 관리해야 합니다. |
이 표에서 가장 실무적인 줄은 fallback입니다. Google은 LiteRT Runtime에서 CPU 또는 GPU를 secondary option으로 지정할 수 있고, TPU availability에 따라 자동으로 사용한다고 설명합니다. 좋은 제품은 최고 사양에서만 돌아가지 않습니다. TPU가 사용 중이거나, 특정 모델이 TPU 경로와 맞지 않거나, 배터리와 thermal 상태가 나쁠 때도 기능이 적어도 예측 가능하게 동작해야 합니다. 온디바이스 AI의 신뢰성은 모델 정확도만큼 fallback 정책에 달려 있습니다.
Google이 늦게 푼 병목
이번 베타가 의미 있는 이유는 Google이 이 문제를 이미 오래 알고 있었기 때문입니다. Pixel은 Google Tensor라는 이름의 SoC를 쓰고, Google은 LiteRT와 Gemma, AI Edge Gallery를 갖고 있습니다. 그런데 외부 개발자가 "Pixel의 TPU를 공식적으로 쉽게 쓰는가"라는 질문에는 명확한 대답이 부족했습니다. 2026년 4월 Beebom은 Pixel 10 계열에서 Google 자체 Tensor SDK가 experimental access로 묶여 있었고, 공개 TPU plugin 경로가 부족해 실제 테스트가 CPU 또는 GPU 중심으로 흐른다고 비판했습니다.
그 비판을 그대로 받아들일 필요는 없습니다. 모바일 온디바이스 AI는 칩, 런타임, 앱 배포, 보안, 라이선스가 모두 얽힌 영역이라 Google이 조심스럽게 문을 여는 것도 이해할 수 있습니다. 하지만 개발자 입장에서는 하드웨어가 존재한다는 사실보다 접근 가능한 API와 샘플, 모델, 배포 문서가 더 중요합니다. 이번 베타는 바로 그 점에서 분기점입니다. Google은 더 이상 "Pixel 안에서 Google 기능이 잘 돈다"만 보여주는 것이 아니라, "외부 앱도 Pixel TPU를 대상으로 모델을 준비해 보라"고 말합니다.
다만 이 문은 아직 좁습니다. 지원 기기는 Pixel 10, Pixel 10 Pro, Pixel 10 Pro XL, Pixel 10 Pro Fold로 제한됩니다. Android 생태계 전체를 생각하면 Pixel은 reference device에 가깝고, 실제 시장에는 Qualcomm, MediaTek, Samsung 계열 NPU가 섞여 있습니다. LiteRT가 추상화를 제공하더라도, Tensor SDK 베타의 직접적인 가치는 Pixel 10 family에서 시작합니다. 앱 팀은 Pixel용 고급 기능을 만들지, 더 넓은 Android 기기군을 위해 보수적인 CPU/GPU 경로를 유지할지 결정해야 합니다.
클라우드 에이전트와 다른 제품 감각
최근 AI 개발 뉴스의 중심은 코딩 에이전트, managed agents, cloud sandbox, long-running workflow였습니다. 이런 흐름에서 온디바이스 AI는 작은 이야기처럼 보일 수 있습니다. 하지만 제품 경험의 관점에서는 반대일 수도 있습니다. 사용자가 매일 만지는 AI 기능 상당수는 서버의 긴 reasoning 작업보다 카메라, 음성, 입력, 알림, 접근성, 개인 데이터 위에서 일어납니다. 이런 기능은 클라우드 왕복이 아니라 기기 안의 즉시성에 더 민감합니다.
예를 들어 접근성 도구가 음성을 받아 적고, 카메라 앱이 프레임을 이해하고, 사진 앱이 배경을 분할하고, 생산성 앱이 로컬 문서를 의미 검색한다면 사용자는 "AI가 생각하는 중"이라는 화면을 기다리고 싶지 않습니다. 지연 시간은 기능의 성격을 바꿉니다. 개인정보도 마찬가지입니다. 일부 데이터는 클라우드로 보내면 편하지만, 보내지 않아야 제품 신뢰가 생기는 데이터도 있습니다. Google이 발표문에서 interactive, realtime, private이라는 단어를 함께 둔 이유가 여기에 있습니다.
그러나 온디바이스 AI가 늘 더 안전하거나 더 싸다는 식으로 단순화하면 안 됩니다. 모델을 앱 안에 넣으면 업데이트 주기가 느려질 수 있고, 모델 파일 크기가 앱 배포와 저장 공간에 영향을 주며, 기기별 성능 차이를 QA해야 합니다. 모델 라이선스도 확인해야 합니다. Google AI Edge Model Garden의 각 항목은 Apache-2.0, MIT, BSD, GPL, AI-HUB-MODELS, No license file 등 서로 다른 라이선스 상태를 보입니다. 기업 앱에서는 "Model Garden에 있다"와 "우리 제품에 넣어도 된다"를 같은 말로 취급하면 위험합니다.
Hugging Face가 들어간 이유
Google이 Model Garden과 함께 Hugging Face LiteRT community를 언급한 점도 중요합니다. 공식 발표는 precompiled model library를 LiteRT Hugging Face community에서 직접 받을 수 있다고 설명합니다. 실제 Hugging Face의 litert-community 모델 페이지에는 Gemma3-1B-IT, Whisper, MobileNet, EfficientNet, ResNet 등 LiteRT compatible 모델이 업데이트된 상태로 노출됩니다.
이는 온디바이스 AI 배포가 단일 벤더 문서 안에 갇히지 않는다는 뜻입니다. 모델 발견과 배포 생태계는 이미 Hugging Face 중심으로 움직입니다. Google이 Pixel TPU와 LiteRT라는 하드웨어/런타임 경로를 열더라도, 개발자가 모델을 찾고 비교하고 가져오는 표면은 Hugging Face가 될 가능성이 큽니다. Google 입장에서는 모델 생태계를 넓히는 장점이 있고, 개발자 입장에서는 Google이 고른 샘플만이 아니라 더 많은 모델 변형을 시험할 수 있습니다.
반대로 이 구조는 책임도 분산시킵니다. 모델이 어디에서 왔는지, 어떤 license와 quantization을 갖는지, 어떤 Pixel 기기에서 어떤 latency와 memory footprint를 보이는지, fallback 때 품질이 얼마나 달라지는지 확인해야 합니다. 클라우드 모델 API에서는 provider가 많은 책임을 추상화합니다. 온디바이스 모델 생태계에서는 앱 팀이 더 많은 운영 판단을 가져갑니다.
Android 팀이 확인해야 할 것
Android 앱 팀이 이번 베타를 바로 제품 계획에 넣는다면 먼저 기능 범위를 좁혀야 합니다. 좋은 후보는 클라우드 왕복이 UX를 해치는 기능입니다. 카메라 프리뷰 기반 segmentation, 오프라인 음성 명령, 접근성 transcription, 로컬 문서 embedding, 사용자의 앱 내 행동을 빠르게 function call로 바꾸는 기능이 여기에 들어갑니다. 반대로 거대한 reasoning, 최신 지식 검색, 장문 생성, 복잡한 coding assistant 같은 기능은 여전히 클라우드 모델이 더 자연스러울 수 있습니다.
두 번째는 배포 단위입니다. Google은 Play Feature Delivery와 AI Packs를 언급했습니다. 이것은 모델을 앱 binary에 고정해 끝내는 방식보다 유연하지만, 제품팀과 릴리스팀이 모델 파일을 어떻게 버전 관리할지 정해야 한다는 뜻입니다. 모델 업데이트가 앱 업데이트와 같은 주기를 따르는지, 특정 기기군에만 내려가는지, 실패 시 어떤 fallback UI를 보여줄지, A/B test와 crash reporting이 어떻게 연결되는지 설계해야 합니다.
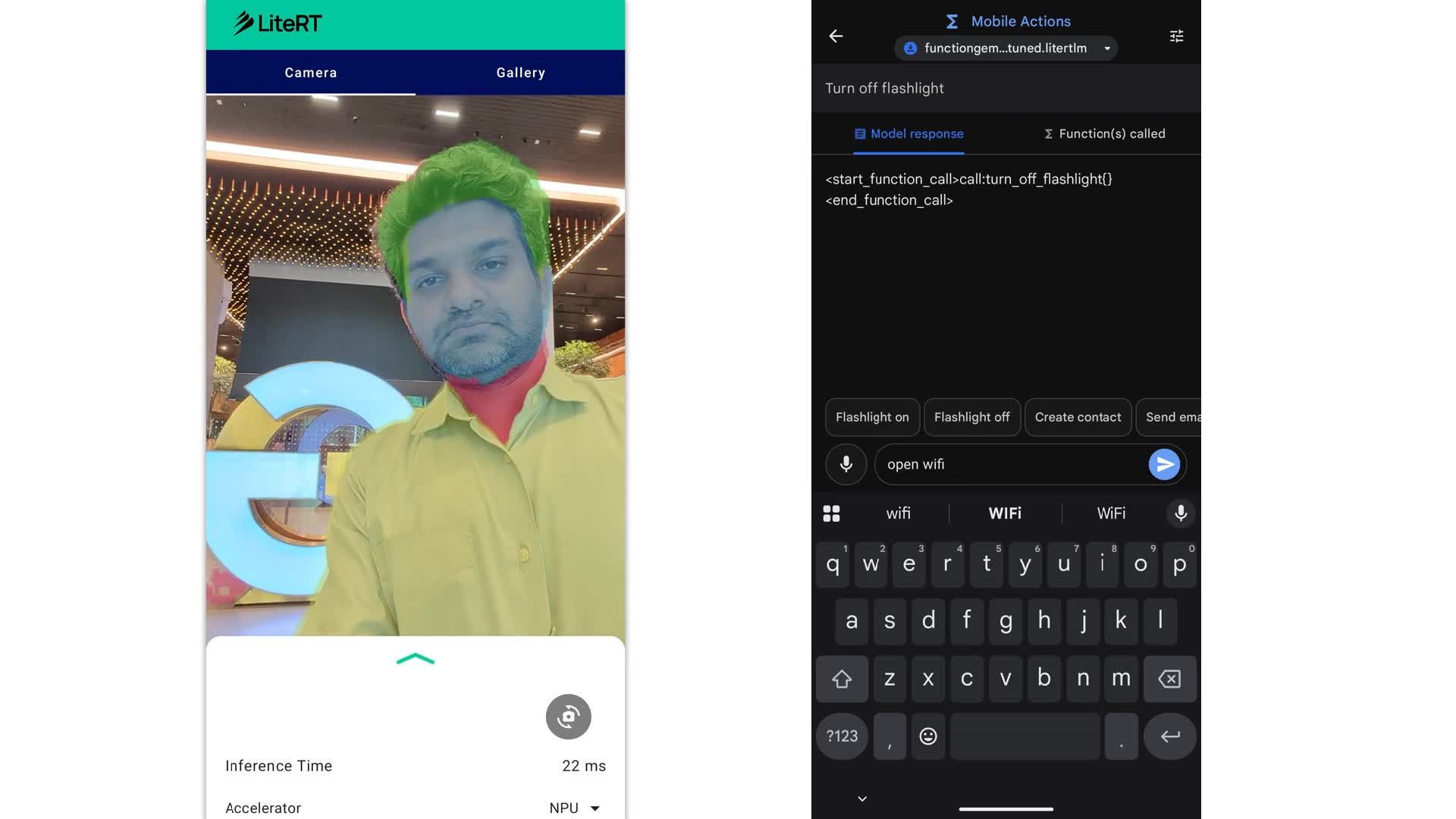
세 번째는 성능 측정입니다. Pixel TPU에서 빨라지는 모델이라도 앱 전체 UX가 빨라진다는 보장은 없습니다. 카메라 프레임 전처리, 모델 로딩, warm-up, memory pressure, 배터리, thermal throttling, fallback 전환 시간까지 봐야 합니다. Google의 공식 데모가 image segmentation sample app과 Function Gemma mobile actions를 보여주는 것도 의미가 있습니다. 둘 다 사용자가 latency를 직접 느끼는 기능입니다.
네 번째는 멀티벤더 전략입니다. Pixel TPU만 보고 기능을 만들면 Android 전체 시장에서 coverage가 제한됩니다. LiteRT가 vendor-specific SDK를 추상화한다고 해도, Tensor SDK 베타의 가장 직접적인 타깃은 Pixel 10 family입니다. 제품팀은 Pixel에서만 premium feature를 제공할지, 다른 Android 기기에서는 CPU/GPU 또는 다른 NPU 경로로 degrade할지, iOS에서는 Core ML로 별도 구현할지 결정해야 합니다.
경쟁 구도: 모델보다 배포 체계
Apple은 Core ML과 Neural Engine을 오랫동안 밀어 왔고, Qualcomm은 AI Engine Direct와 AI Hub를 통해 Snapdragon NPU 경로를 제시합니다. Meta와 PyTorch 진영은 ExecuTorch로 모바일과 edge 실행을 밀고 있습니다. Google의 차별점은 Android, Play, Pixel, LiteRT, Gemma, Hugging Face community를 한 흐름으로 묶을 수 있다는 데 있습니다. 특히 Play Feature Delivery와 AI Packs까지 발표문에 함께 들어간 점은 Google이 모델 실행을 앱 배포 체계와 연결하려 한다는 신호입니다.
하지만 이 장점은 곧 잠금 효과이기도 합니다. Pixel TPU에 맞춰 최적화한 모델과 배포 체계는 Pixel에서는 좋은 경험을 만들 수 있지만, Android 전체와 iOS까지 넓히려면 추상화 비용이 생깁니다. 온디바이스 AI의 장기 승부는 "어느 모델이 가장 똑똑한가"보다 "어느 배포 체계가 가장 많은 기기에서 안정적으로 돌아가는가"에 가까워질 가능성이 큽니다.
Google이 이번에 발표한 것은 그 승부의 Pixel 쪽 첫 공개 베타입니다. 아직은 좁고, Pixel 10 family 중심이며, 모델과 라이선스와 runtime 상태를 개발자가 직접 봐야 합니다. 그래도 의미는 분명합니다. 온디바이스 AI가 OS 제조사의 데모 기능에서 외부 앱의 기능 단위로 넘어가기 시작했습니다.
결론: 작은 모델의 배포 문제가 커집니다
AI 뉴스는 보통 더 큰 모델, 더 긴 context, 더 강한 agent를 향합니다. Google Tensor SDK Beta with LiteRT는 반대 방향의 뉴스입니다. 더 작은 모델을, 더 가까운 기기에서, 더 낮은 지연과 더 많은 개인정보 통제 아래 실행하려는 뉴스입니다. 그리고 그 작은 모델의 배포 문제는 생각보다 큽니다.
이번 베타가 성공하려면 Google은 문서와 샘플을 넘어 실제 앱 운영에서 필요한 답을 줘야 합니다. 어떤 모델이 어떤 Pixel에서 어느 정도 latency를 내는지, fallback 때 품질이 얼마나 떨어지는지, Play 배포와 모델 업데이트가 얼마나 예측 가능한지, 라이선스와 보안 검토가 얼마나 명확한지가 중요합니다. 개발자는 "100개 모델"이라는 숫자보다, 그중 하나를 앱 기능으로 넣었을 때 다음 분기에도 안정적으로 유지할 수 있는지를 봅니다.
그래도 방향은 선명합니다. Google은 Pixel의 Tensor TPU를 더 이상 내부 기능만을 위한 칩으로 두지 않으려 합니다. LiteRT, Model Garden, Hugging Face community, Play 배포 경로를 묶어 외부 개발자가 온디바이스 AI 기능을 만들 수 있는 통로를 열고 있습니다. 클라우드 AI가 agent와 대규모 reasoning으로 커지는 동안, 모바일 AI는 사용자의 손 안에서 작은 모델 여러 개가 조용히 돌아가는 쪽으로 자리를 잡을 수 있습니다. 이번 Tensor SDK 베타는 그 좁은 문이 열린 첫 신호입니다.