
AI
에이전트 흔적 1,781개 분석, 모델보다 7배 큰 하네스 효과
Braintrust와 Hugging Face가 공개 에이전트 흔적 1,781개를 분석했습니다. 성공률과 비용은 모델명보다 하네스와 작업 유형에 더 민감했습니다.
AI
Braintrust와 Hugging Face가 공개 에이전트 흔적 1,781개를 분석했습니다. 성공률과 비용은 모델명보다 하네스와 작업 유형에 더 민감했습니다.

AI
huggingface_hub가 4~6주 릴리스를 주간 주기로 바꿨습니다. 오픈 웨이트 모델, PR 검증, 사람 승인 구조를 짚습니다.
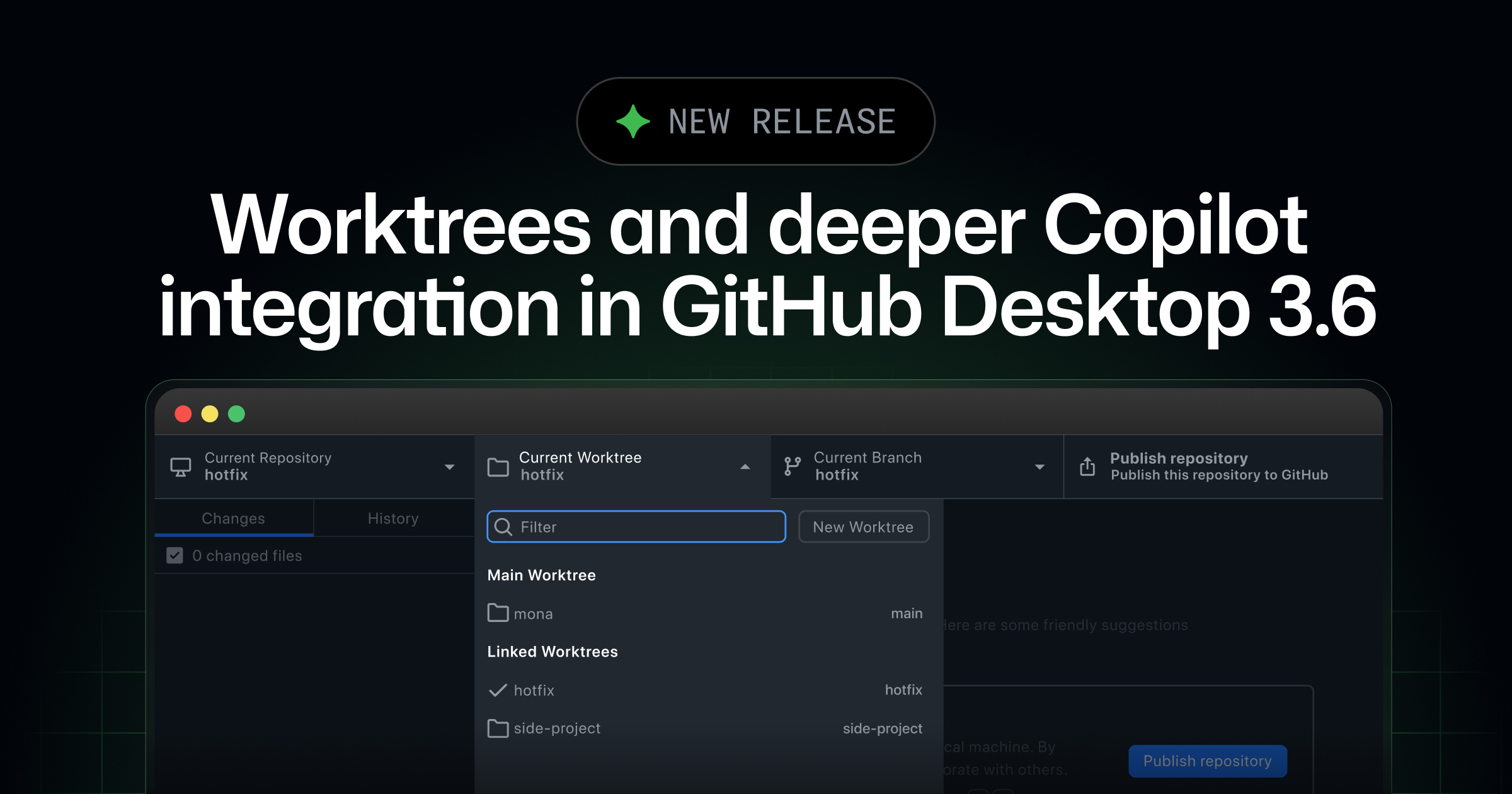
AI
GitHub Desktop 3.6이 워크트리, Copilot 커밋 작성, 병합 충돌 해결을 묶었습니다. 에이전트 병렬 작업의 Git 표면을 봅니다.

AI
Google이 A2UI와 MCP Apps를 섞는 3개 패턴을 공개했습니다. 에이전트 UI의 iframe, 보안, 네이티브 렌더 경계를 봅니다.

AI
Cloudflare가 self-managed OAuth를 모든 개발자에게 열고 임시 배포 계정과 함께 에이전트 권한 위임 경로를 정리했습니다.

AI
OpenAI GPT-5.6 Sol, Terra, Luna가 제한 프리뷰로 나왔습니다. API·Codex 승인 범위, 가격표, 보안 평가가 개발자 접근을 어떻게 바꾸는지 봅니다.

AI
Stripe가 AWS에서 금융 컴플라이언스 에이전트를 운영해 검토 시간을 26% 줄였습니다. 핵심은 자동 판정이 아니라 DAG, 로그, 인간 승인입니다.

AI
Mistral이 커넥터 권한 제어, 범위 API 키, MCP 디버거, Vibe Code 연동을 공개했습니다. 기업 에이전트 운영의 병목을 봅니다.

AI
GitHub Copilot for Jira가 GA가 되며 Jira 티켓 안에서 코딩 에이전트 진행 상황과 후속 지시를 다룹니다.
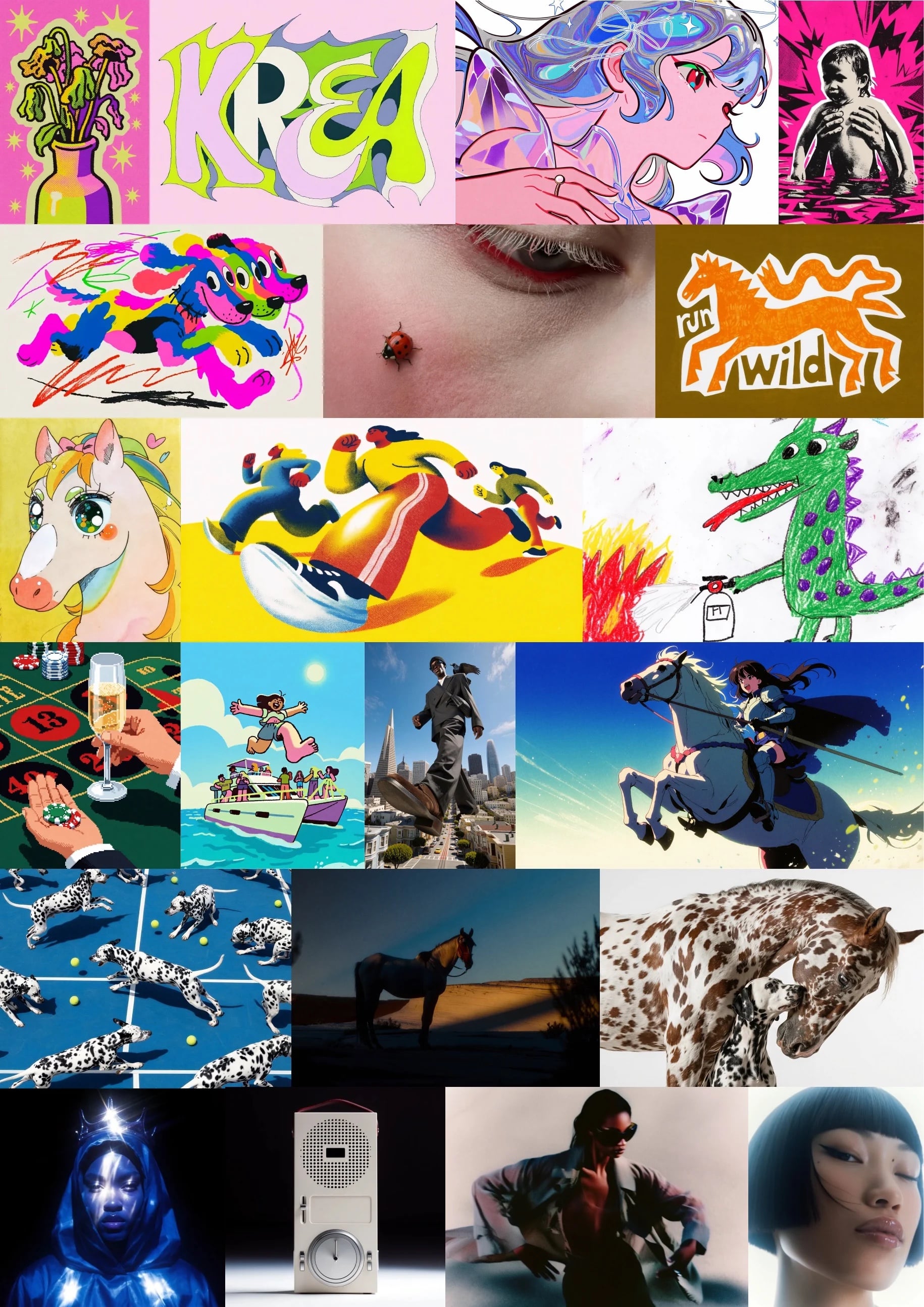
AI
Krea가 12B 이미지 모델 Krea 2를 공개했습니다. RAW/Turbo 체크포인트, 8스텝 추론, 라이선스 경계를 개발자 관점에서 봅니다.

AI
OpenAI가 Codex 사용 데이터 보고서를 공개했습니다. 30분·1시간·8시간 업무 위임, 출력 토큰 비중, 비개발자 확산의 한계를 함께 봅니다.

AI
GitHub가 Copilot Free와 Student 플랜에서 Auto를 유일한 모델 선택 경로로 바꿨습니다. 200 AI 크레딧과 비용 예측 문제를 봅니다.