에이전트 흔적 1,781개 분석, 모델보다 7배 큰 하네스 효과
Braintrust와 Hugging Face가 공개 에이전트 흔적 1,781개를 분석했습니다. 성공률과 비용은 모델명보다 하네스와 작업 유형에 더 민감했습니다.

- 무슨 일: Braintrust와 Hugging Face 커뮤니티가 Exgentic의 공개 에이전트 실행 흔적 1,781개를 분석했습니다.
- 데이터는 SWE-bench, AppWorld, BrowseComp+, TAU2 계열 벤치마크와 여러 하네스·모델 조합을 포함합니다.
- 숫자: 조건을 통제한 회귀 분석에서 하네스는 성공률 변동을 5.3%, 모델은 0.7% 추가 설명했습니다.
- 실무 영향: 코딩 에이전트 평가는 모델 순위표보다 성공당 비용, 실패 토큰, 도구 실행층을 함께 봐야 합니다.
Braintrust와 Hugging Face 커뮤니티 글이 2026년 6월 하순 공개 에이전트 실행 흔적 1,781개를 다시 분석했습니다. 제목만 보면 평가 도구 회사의 블로그처럼 보이지만, 개발팀이 코딩 에이전트를 고를 때 자주 놓치는 숫자가 들어 있습니다. 같은 모델과 같은 벤치마크를 고정해도 하네스가 바뀌면 성공률이 12%에서 92%까지 움직였습니다. 회귀 분석에서는 하네스가 성공률 차이를 모델보다 약 7배 더 많이 설명했습니다.
여기서 하네스는 모델을 감싸는 실행층입니다. 모델은 다음 토큰을 예측하지만, 하네스는 작업 설명과 도구 목록을 프롬프트에 넣고, 모델 출력을 명령으로 파싱하고, 파일 읽기와 코드 실행을 수행하고, 결과를 다시 모델에 넘기고, 재시도와 종료 조건을 관리합니다. Claude Code, smolagents_code, 단순 tool_calling 같은 이름은 모델명이 아니라 이 실행층의 차이를 가리킵니다. 개발자가 체감하는 "에이전트가 일을 잘한다"는 경험은 모델 능력과 이 실행층이 붙어 나온 결과입니다.
이번 분석의 원자료는 Exgentic/agent-llm-traces 데이터셋입니다. Hugging Face 데이터셋 설명에 따르면 이 자료는 1,781개 실행 흔적과 6개 벤치마크를 담고 있습니다. 각 흔적에는 전체 대화, 토큰 사용량, 시작·종료 시각, 도구 호출과 결과, 도구 정의, 모델 정보, 오류 상태가 들어 있습니다. Braintrust 글은 이 자료에서 약 49,000개 하위 span을 다뤘고, 실행 하나가 평균 약 27번의 LLM 호출을 포함했다고 설명합니다.
벤치마크도 하나가 아닙니다. SWE-bench는 실제 GitHub 이슈를 고치는 소프트웨어 엔지니어링 작업입니다. AppWorld는 Venmo, Gmail, Spotify, Splitwise, Todoist 같은 앱 API를 엮어 개인 비서 작업을 끝내는 과제입니다. BrowseComp+는 웹 조사형 질문에 답하는 과제이고, TAU2 Airline·Retail·Telecom은 고객지원 도구 사용을 평가합니다. 이 구성이 중요합니다. 코딩과 고객지원은 같은 "에이전트"라는 말로 묶이지만, 실패 방식과 비용 구조가 반대로 움직입니다.
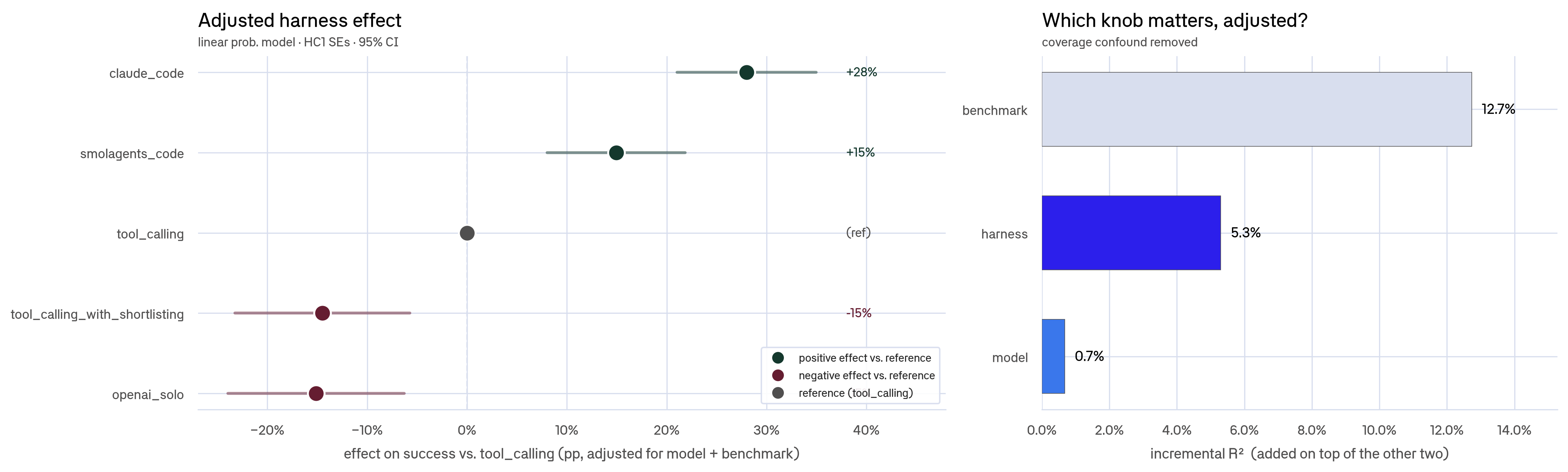
가장 강한 숫자는 하네스 효과입니다. Braintrust는 모델과 벤치마크를 고정하고 하네스만 바꿨을 때 성공률 차이가 최대 81%포인트까지 벌어졌다고 밝혔습니다. 예를 들어 SWE-bench에서 Claude는 claude_code 하네스로 100%, 단순 tool_calling 하네스로 14%를 보였습니다. AppWorld에서 Kimi는 smolagents_code로 92%, 단순 tool_calling으로 12%였습니다. 같은 모델을 두고도 작업 루프, 도구 호출, 재시도, 종료 판단이 바뀌면 결과가 완전히 달라진다는 뜻입니다.
이 주장이 단순 표본 차이인지 확인하기 위해 Braintrust는 성공 여부를 종속변수로 두고 벤치마크, 모델, 하네스를 설명변수로 넣은 선형확률모형을 돌렸습니다. 전체 1,781개 중 점수 없는 1개를 제외한 1,780개 행이 대상이었습니다. 결과에서 벤치마크는 추가 설명력 12.7%로 가장 컸고, 하네스는 5.3%, 모델은 0.7%였습니다. 작업 종류가 가장 중요하고, 그다음은 실행층이며, 모델 선택은 그 뒤라는 순서입니다.
이 숫자는 "모델은 중요하지 않다"는 뜻이 아닙니다. 오히려 모델 평가가 실행 조건과 분리되면 실제 제품 선택에 약하다는 뜻입니다. SWE-bench에서 claude_code 하네스를 쓴 결과만 보면 Claude Opus 4.5는 100%, DeepSeek V3.2는 96%, Kimi K2.5는 94%, GPT-5.2는 93%, Gemini 3 Pro는 87%였습니다. 닫힌 모델과 오픈 웨이트 모델이 같은 하네스 안에서 거의 붙어 있습니다. 이 결과만으로 모든 작업에서 오픈 웨이트가 이긴다고 말할 수는 없지만, 코딩 작업에서는 자체 호스팅 모델이 이미 실무 후보에 들어왔다는 신호로 읽을 수 있습니다.
데이터셋에 포함된 하네스 이름을 보면 왜 이런 차이가 생기는지도 보입니다. claude_code는 파일 탐색, 편집, 실행, 검증을 장시간 루프로 묶는 코딩 에이전트형 하네스입니다. smolagents_code는 Python 코드 실행 중심으로 도구를 조합합니다. 단순 tool_calling은 모델이 도구 호출을 고르는 구조에 더 가깝습니다. 세 방식은 같은 "도구 사용"이라는 말로 묶이지만, 실패 뒤에 다시 볼 파일을 찾는 방식, 테스트 결과를 다음 행동으로 바꾸는 방식, 중간 산출물을 보존하는 방식이 다릅니다.
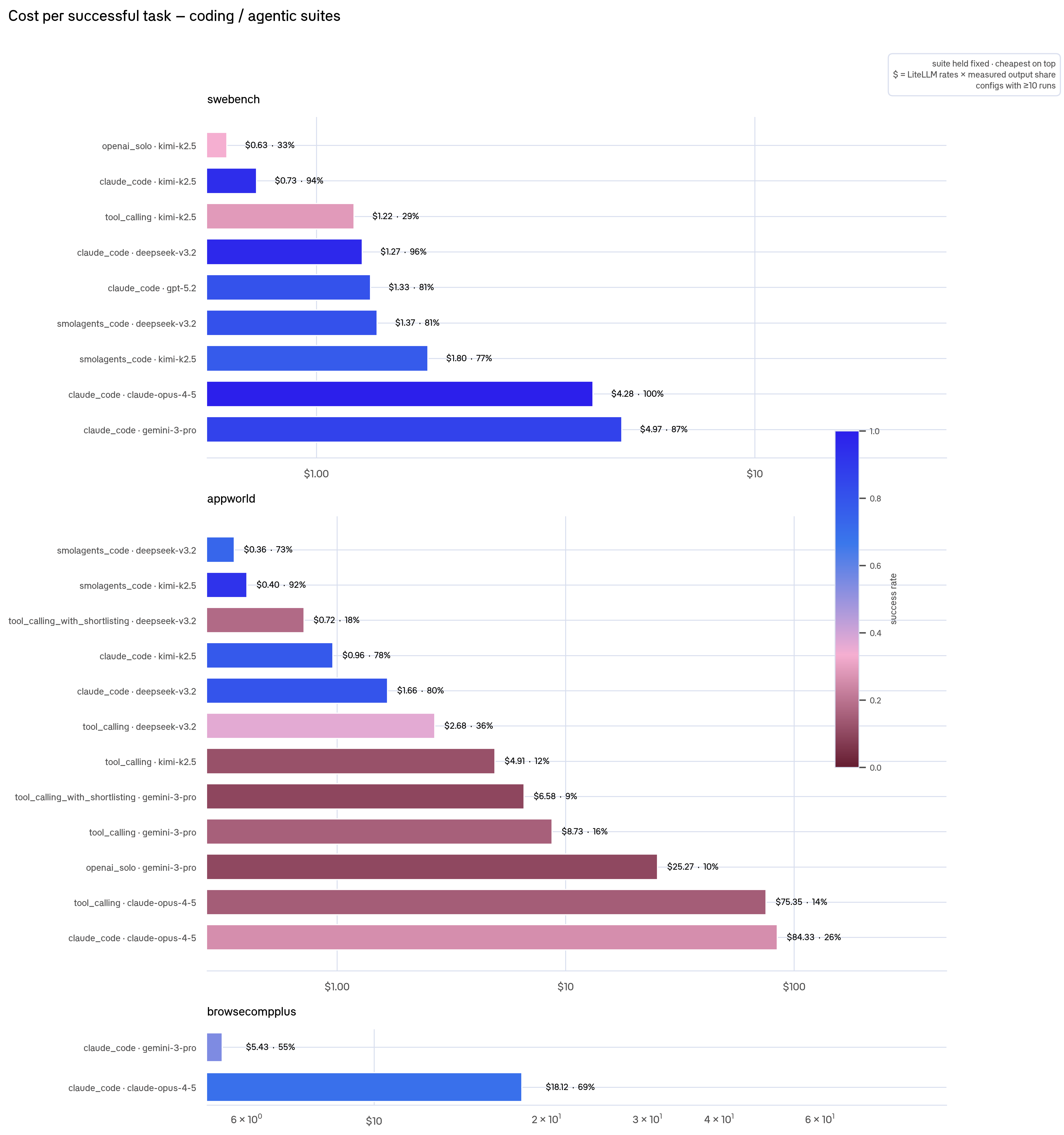
비용표를 보면 순위가 더 흔들립니다. Braintrust는 LiteLLM의 토큰 단가를 기준으로 실행별 비용을 계산했습니다. 글은 코딩과 에이전트 작업에서 성공 1건당 비용이 모델 선택의 핵심 지표라고 봅니다. SWE-bench에서 claude_code · Kimi-K2.5는 성공 1건당 0.73달러와 성공률 94%로 제시됐습니다. DeepSeek-V3.2는 1.27달러와 96%, claude-opus는 4.28달러와 100%, gemini-3-pro는 4.97달러와 87%였습니다. 성공률 100%라는 숫자를 상한으로 보더라도, 비용당 성공에서는 오픈 웨이트 조합이 앞쪽에 놓입니다.
AppWorld에서는 차이가 더 큽니다. 글은 smolagents_code · Kimi-K2.5가 성공 1건당 0.40달러와 92% 성공률을 보였고, claude_code · claude-opus는 성공 1건당 84.33달러와 26% 성공률을 보였다고 적었습니다. 이 비교는 모델만의 비교가 아닙니다. 하네스가 다르고 작업 구성도 다릅니다. 그래서 해석은 "Kimi가 언제나 Claude보다 낫다"가 아니라 "성공당 비용은 작업군과 하네스까지 묶어 계산해야 한다"에 가깝습니다.
| 작업군 | 유리했던 조합 | 운영자가 봐야 할 지표 |
|---|---|---|
| SWE-bench | claude_code 안의 Claude, DeepSeek, Kimi | 성공률, 성공당 비용, 실행 시간 |
| AppWorld | smolagents_code와 Kimi/DeepSeek 조합 | API 오케스트레이션 성공률, 재시도 비용 |
| TAU2 고객지원 | 작업별로 Gemini, Claude, GPT-4.1이 갈림 | 짧은 실패, 잘못된 완료, 검증 루브릭 |
실패 패턴도 작업군에 따라 갈립니다. 코딩 작업, AppWorld, BrowseComp+에서 실패는 대체로 더 많은 호출과 토큰을 태우는 형태였습니다. 파일을 읽고, 수정하고, 테스트하고, 다시 고치다가 루프에 빠지는 식입니다. 반대로 TAU2 같은 대화형 고객지원 작업에서 실패는 더 짧고 싸게 끝나는 경향이 있었습니다. 에이전트가 답을 냈다고 믿고 일찍 종료하지만, 실제로는 잘못된 조치나 답변을 남기는 구조입니다.
이 차이는 운영 경보 규칙을 바꿉니다. 코딩 에이전트에는 "토큰이 비정상적으로 많이 타면 멈춘다"는 규칙이 필요할 수 있습니다. 같은 규칙을 고객지원 에이전트에 그대로 쓰면 실패를 놓칠 수 있습니다. 고객지원에서는 너무 짧고 싼 실행이 오히려 위험 신호일 수 있기 때문입니다. Braintrust 글은 하나의 토큰 한도 규칙이 한 작업군에는 도움이 되고 다른 작업군에는 해가 될 수 있다고 적었습니다.
이번 분석이 유용한 또 다른 이유는 공개 흔적의 형식입니다. Hugging Face의 Agent Traces 문서는 Claude Code, Codex, Pi Agent 세션을 Hub 데이터셋이나 Storage Bucket에 올리면 전용 trace viewer에서 볼 수 있다고 설명합니다. 세션 타임라인, 프롬프트, assistant 메시지, 도구 호출, 결과를 행 단위로 열어 보는 방식입니다. 이제 에이전트 평가는 최종 답변만 모으는 방식에서 실행 과정 자체를 비교하는 방식으로 이동하고 있습니다.
개발팀 입장에서는 이 변화가 비용 관리와 품질 관리 양쪽에 걸립니다. 모델 API 비용만 추적하면 "싼 모델"을 고르게 됩니다. 하지만 성공률이 낮아 재시도가 늘거나 실패를 사람이 다시 처리하면 성공당 비용은 올라갑니다. 반대로 비싼 모델이 높은 성공률로 빨리 끝내면 실제 비용은 더 낮을 수 있습니다. 이번 글에서 GPT-4.1이 일부 어려운 작업에서 10~100배 싸게 보였지만, 실제로는 빨리 실패했기 때문에 싸게 보였다는 지적이 바로 이 함정입니다.
하네스 투자는 모델 교체보다 덜 화려합니다. 프롬프트 구성, 파일 탐색, 도구 스키마, 실행 로그, 테스트 호출, 재시도 조건, diff 검증, 중단 기준 같은 항목을 다룹니다. 그런데 이번 숫자는 이 항목들이 성공률을 바꿀 수 있다는 증거입니다. 코딩 에이전트가 같은 모델을 쓰는데 한 제품에서는 유능하고 다른 제품에서는 불안정해 보이는 이유도 여기서 설명됩니다. 모델의 능력이 실행층을 통과하면서 보존되거나 망가집니다.
사내 평가를 설계할 때는 trace 스키마부터 정해야 합니다. 최소한 작업 ID, 저장소 또는 앱 이름, 모델, 하네스, 도구 목록, 토큰 사용량, 실행 시간, 종료 사유, 테스트 결과, 사람 검수 결과가 같은 행에 있어야 합니다. 그래야 "이번 모델은 싸다"가 아니라 "이 하네스에서 이 작업군을 통과한 성공 1건의 비용이 얼마인가"를 계산할 수 있습니다. Braintrust 글이 SQL 예시로 benchmark, harness, model, tokens, task_success를 묶은 이유도 이 때문입니다.
이 관점은 보안에도 닿습니다. 에이전트가 어떤 파일을 읽었는지, 어떤 셸 명령을 실행했는지, 어떤 API를 호출했는지 trace에 남지 않으면 사후 감사가 어렵습니다. Cloudflare OAuth나 Mistral 커넥터 제어 같은 최근 발표가 권한 경계를 다뤘다면, 이번 분석은 그 권한이 실제 실행에서 어떤 결과를 냈는지 보는 계측 문제를 다룹니다. 권한 정책과 trace 분석은 따로 놓을 수 없습니다. 권한을 좁혀도 실패율이 올라가면 하네스가 보완해야 하고, 권한을 넓혀도 성공당 비용이 줄지 않으면 위험만 커질 수 있습니다.
다만 이 분석을 그대로 벤더 순위표로 쓰면 안 됩니다. Braintrust 글은 한계를 꽤 명확히 적었습니다. Exgentic 데이터셋에는 원래 정답 라벨이 없었고, Braintrust가 성공 지표를 새로 만들었습니다. BrowseComp+는 정답이 고정돼 있지 않아 판단이 약합니다. SWE-bench는 실제 GitHub 이슈 기반이라 모델이 학습 중 해답을 봤을 가능성이 있습니다. 일부 조합은 실행 수가 10~15개라 통계적으로 거칠 수 있습니다. Claude의 SWE-bench 100%도 확정값이 아니라 상한으로 보라고 덧붙였습니다.
그래도 이 한계가 결론을 약하게 만들지는 않습니다. 오히려 실무 평가의 요구사항을 분명하게 만듭니다. 첫째, 모델 평가는 자기 팀 작업과 비슷한 벤치마크로 나눠야 합니다. 둘째, 하네스 이름과 설정을 결과 표에 함께 적어야 합니다. 셋째, 토큰당 비용이 아니라 성공당 비용과 실패 복구 비용을 기록해야 합니다. 넷째, 실패가 "오래 헤맨 실패"인지 "빨리 포기한 실패"인지 분리해야 합니다.
최근 AI 개발 도구 시장은 새 모델, 새 코딩 에이전트, 새 MCP 커넥터 발표가 이어졌습니다. devlery에서도 Copilot for Jira, GitHub Desktop 3.6, Google A2UI, Cloudflare OAuth, Hugging Face 릴리스 자동화 같은 실행 환경 변화를 다뤘습니다. 이번 Braintrust/Hugging Face 분석은 그 발표들을 비교할 때 필요한 기준을 줍니다. 어느 제품이 어떤 모델을 쓴다는 설명만으로는 부족합니다. 어떤 하네스가 작업을 어떻게 쪼개고, 어떤 도구를 호출하며, 실패를 어떤 신호로 감지하는지가 같이 공개돼야 합니다.
에이전트 도입을 검토하는 팀이라면 구매 질문도 바꿔야 합니다. "어떤 모델을 쓰나요?" 다음에는 "우리 저장소에서 실패 trace를 내보낼 수 있나요?", "성공당 비용을 볼 수 있나요?", "도구 호출과 테스트 실행 로그를 보존하나요?", "토큰 한도는 작업 유형별로 다르게 둘 수 있나요?"를 물어야 합니다. 모델명은 시작점입니다. 운영 비용과 품질은 하네스, 데이터셋, trace, 평가 루브릭에서 결정됩니다.
이번 분석의 가장 실용적인 문장은 "가장 싼 모델을 고르라"가 아닙니다. "품질 기준을 넘는 가장 싼 구성"을 찾으라는 것입니다. 그 구성은 코딩, 웹 조사, 고객지원, 사내 API 오케스트레이션마다 달라집니다. 1,781개 흔적은 모델 순위표를 끝내는 자료가 아니라, 에이전트 평가표에 새 열을 추가하라는 자료입니다. 그 새 열에는 하네스, 벤치마크, 성공당 비용, 실패 패턴이 들어가야 합니다.