Stripe 컴플라이언스 에이전트, 26% 빨라진 인간 검토
Stripe가 AWS에서 금융 컴플라이언스 에이전트를 운영해 검토 시간을 26% 줄였습니다. 핵심은 자동 판정이 아니라 DAG, 로그, 인간 승인입니다.

- 무슨 일: AWS와 Stripe가 2026년 6월 26일 금융 컴플라이언스용 운영 에이전트 사례를 공개했습니다.
- Stripe는 연간 1.4조 달러 결제량과 50개국 운영을 배경으로, Amazon Bedrock 기반 에이전트가 검토 시간을 26% 줄였다고 밝혔습니다.
- 핵심 설계: 에이전트가 최종 판정을 내리지 않고, 작은 질문 단위의 사전 조사 자료를 인간 검토자에게 제공합니다.
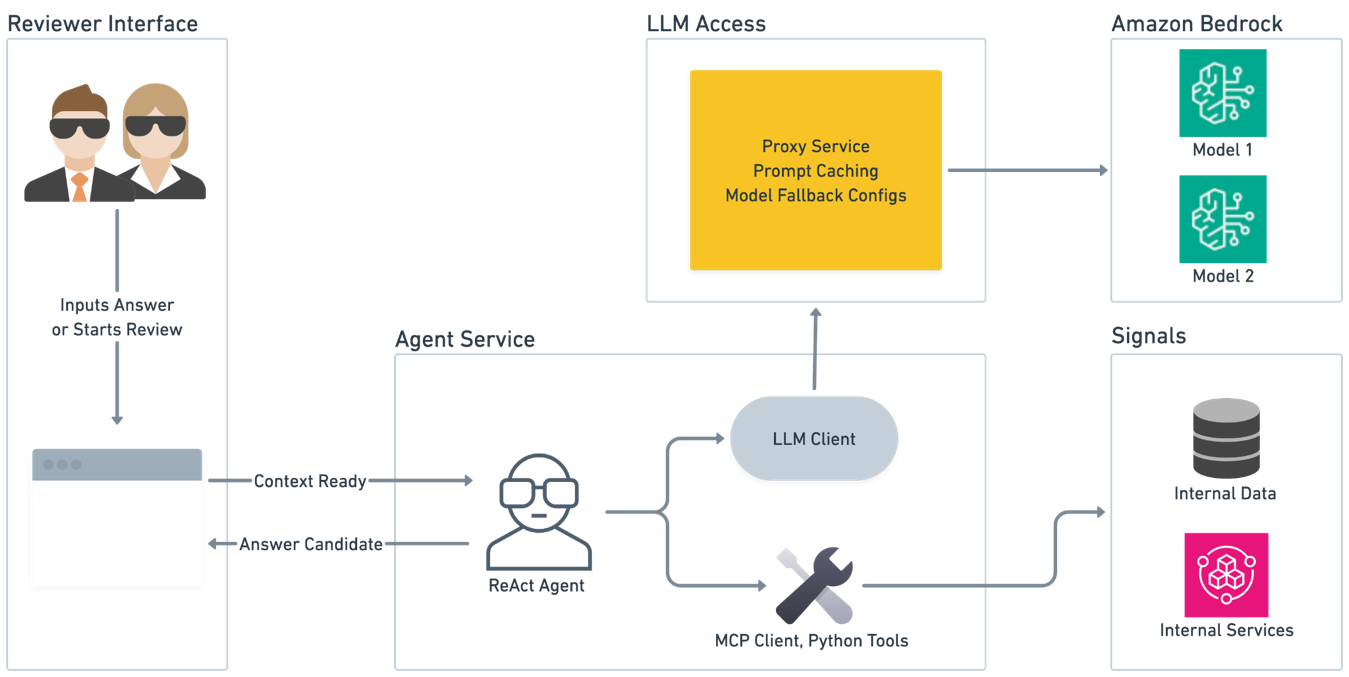
- 운영 조건: DAG orchestration, ReAct observation 로그, LLM Proxy, 별도 agent service가 감사 가능성을 만듭니다.
- AWS 글은 reviewer helpfulness 96% 이상, agent service 100개 이상 확장을 함께 제시했습니다.
- 주의점: Stripe는 위험 허용치를 높이지 않겠다고 밝히며, 실제 인간 품질 기준으로 에이전트 구성요소를 검증한다고 설명했습니다.
AWS Machine Learning Blog가 2026년 6월 26일 Stripe와 공동 작성한 글을 공개했습니다. 제목은 금융 컴플라이언스용 운영 등급 에이전트 사례입니다. 표면의 숫자는 선명합니다. Stripe는 Amazon Bedrock을 사용하는 에이전트 시스템으로 검토 처리 시간을 26% 줄였고, 검토자 유용성 평가는 96% 이상을 유지했다고 밝혔습니다. 하지만 이번 사례에서 더 중요한 문장은 “인간 전문가가 최종 결정을 계속 통제한다”는 조건입니다.
Stripe는 결제 API 회사로 시작했지만, AWS 글은 2026년 초 기준 Stripe가 50개국에서 수백만 회사를 지원하고 연간 약 1.4조 달러 결제량을 처리한다고 적었습니다. 같은 글은 이 금액을 전 세계 GDP의 약 1.3%로 환산합니다. 이 규모의 결제망에서는 금융 범죄 위험, 규제 문서, 고객 마찰, 감사 대응이 제품 기능과 같은 층에 놓입니다. 컴플라이언스 검토가 느리면 정상 고객이 막히고, 너무 느슨하면 규제 리스크가 커집니다.
문제는 분석가의 시간이었습니다. AWS 글은 숙련 컴플라이언스 분석가가 고가치 위험 판단보다 문서와 시스템을 오가며 자료를 모으는 데 최대 80%의 시간을 썼다고 설명합니다. 매일 수천 건의 거래를 검토해야 하는 조직에서 이 병목은 단순한 내부 생산성 문제가 아닙니다. 위험 검토의 속도와 품질이 결제 승인, 고객 경험, 조사 근거, 규제 대응 문서까지 연결됩니다.
이 사례를 “AI가 금융 판단을 대신했다”로 읽으면 사실과 어긋납니다. Stripe의 설계는 반대 방향에 가깝습니다. 에이전트는 판단권을 가져간 것이 아니라, 사람이 판단하기 전에 필요한 질문과 자료 수집을 작은 단위로 나눠 처리했습니다. 각 답변은 최종 판정이 아니라 검토자에게 제공되는 보조 정보입니다. 인간 검토자는 여전히 각 하위 질문에 답해야 하고, 그 답이 후속 질문의 문맥으로 들어갑니다.
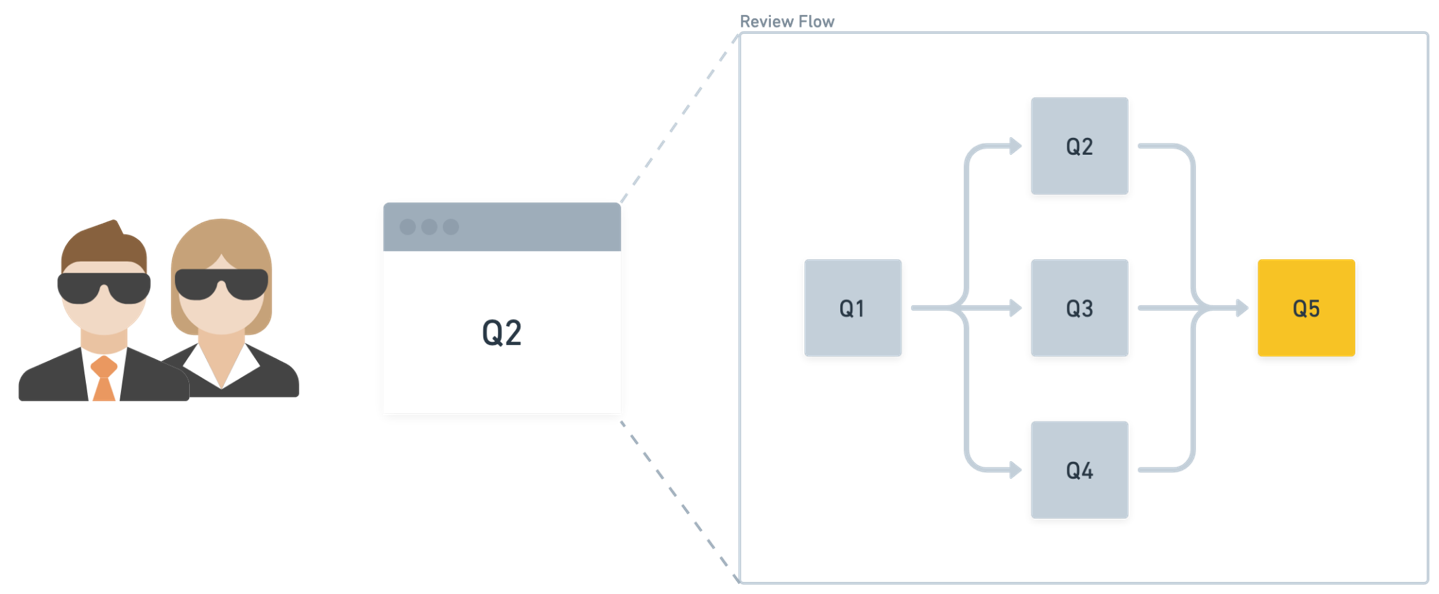
큰 검토를 작은 질문으로 쪼갠 이유
Stripe가 먼저 피한 것은 “긴 컴플라이언스 검토를 하나의 에이전트에게 통째로 맡기는 방식”이었습니다. AWS 글은 단일하고 제약 없는 에이전트가 잘못된 부분에 과하게 집중하거나 필요한 부분을 놓칠 수 있다고 설명합니다. 그래서 복잡한 검토를 조합 가능한 작은 하위 작업으로 나누고, 각 하위 작업이 다른 하위 작업의 결과에 의존할 수 있게 DAG로 구성했습니다.
DAG라는 구현 선택은 기사에서 꽤 중요합니다. 금융 검토는 독립 질문의 체크리스트가 아닙니다. 예를 들어 한 질문의 인간 검토 답변이 후속 질문의 전제나 범위를 바꿀 수 있습니다. Stripe의 검토 도구는 현재 질문과 그 답을 필요로 하는 후속 질문을 알고 있고, 검토자가 승인한 답변을 다음 프롬프트 문맥으로 전달합니다. 이 구조는 “에이전트가 끝까지 알아서 조사한다”보다 느릴 수 있지만, 어느 질문이 어떤 근거로 이어졌는지 남기기 쉽습니다.
AWS 글은 이 하위 작업을 rails라고 표현합니다. 품질 테스트로 검증된 질문에서만 에이전트 프로세스를 실행하고, 조사가 필요한 기준선을 빠뜨리지 않게 하며, 에이전트에게 충분하지만 과하지 않은 문맥을 줍니다. 이 부분은 실무적으로 중요합니다. 금융 컴플라이언스에서는 모델이 답을 잘 쓰는 것보다, 어떤 질문을 물어야 하고 어느 범위 밖으로 나가면 안 되는지가 먼저입니다.
- 26%: 중앙값 검토 처리 시간 감소입니다. 최종 판정 자동화가 아니라 검토 전 조사 비용 절감에 가깝습니다.
- 96% 이상: 검토자 유용성 평가입니다. 인간 검토자가 쓸 수 있는 보조 정보로 평가됐다는 뜻입니다.
- 100개 이상: 1년 미만에 확장된 내부 에이전트 수입니다. 단일 PoC가 아니라 agent service 운영 표면으로 커졌습니다.
- 60%: token caching 기반 비용 절감 설명입니다. 반복 문맥과 관찰 누적이 에이전트 비용의 핵심 변수입니다.
ReAct 루프가 감사 로그가 되는 순간
각 하위 질문에서 Stripe는 ReAct 방식의 에이전트 프레임워크를 사용했습니다. ReAct는 reasoning and acting의 줄임말로, 모델이 생각하고 도구를 호출하고 관찰 결과를 다시 읽는 루프입니다. AWS 글은 “10을 π로 나눈 값” 같은 단순 예시로 이 과정을 설명합니다. 모델이 답을 모르면 계산기 도구를 요청하고, 도구 결과가 observation으로 들어오며, 모델은 그 관찰 결과를 처리한 뒤 최종 답을 만듭니다.
이 구조가 금융 검토에서 중요한 이유는 도구 결과가 모델의 말로만 남지 않기 때문입니다. ReAct 프레임워크는 도구가 요청되면 LLM 실행을 멈추고, 프로그램이 도구를 실행한 뒤, 그 출력을 observation으로 다시 주입합니다. AWS 글은 이 주입 패턴을 closed-loop control mechanism이라고 설명합니다. 환각으로 도구 결과를 지어내는 것을 줄이고, 각 정보 조각을 모델이 명시적으로 처리하게 하며, tool invocation, observation, reasoning의 흔적을 남깁니다.
컴플라이언스 환경에서 이 흔적은 성능 기능이 아니라 방어 기능입니다. 규제기관이나 내부 감사인이 “왜 이 검토가 이렇게 진행됐는가”를 물을 때, 최종 요약만으로는 부족합니다. 어떤 내부 신호를 조회했는지, 어떤 도구 출력이 들어왔는지, 그 결과를 모델이 어떻게 다음 단계 판단에 썼는지 보여줘야 합니다. Stripe가 전체 agent log를 과거 실행별로 조회 가능하게 남겼다는 대목은 그래서 핵심입니다.
ReAct에도 비용과 문맥 문제가 있습니다. 작업이 길어지고 관찰 결과가 많아지면 프롬프트가 계속 커집니다. AWS 글은 하위 작업 분해가 턴 수를 줄이고, Amazon Bedrock의 prompt caching이 입력 토큰 비용을 낮추는 데 도움이 됐다고 설명합니다. 같은 글의 교훈 섹션은 token caching이 공통 프롬프트 prefix를 재사용해 비용을 60% 줄였다고 적었습니다. 이 수치는 Stripe 사례의 내부 설명이지만, 에이전트 운영비가 모델 단가보다 대화 길이와 반복 문맥에 좌우된다는 사실을 잘 보여줍니다.
기존 ML 서빙으로는 맞지 않았던 이유
Stripe가 별도 agent service를 만든 대목도 이번 글의 실무 포인트입니다. AWS 글에 따르면 Stripe는 처음에 에이전트를 전통적인 ML inference engine에 맞추려 했지만 빠르게 포기했습니다. 이유는 세 가지였습니다. 기존 ML은 GPU, 빠른 CPU, 큰 메모리 같은 compute-bound 응답에 맞춰져 있습니다. 반면 에이전트는 LLM 응답과 도구 호출을 기다리는 network-bound 작업입니다.
지연 시간도 다릅니다. XGBoost 모델은 밀리초 단위로 값을 돌려줄 수 있지만, ReAct 에이전트는 몇 번의 도구 호출을 할지 미리 알기 어렵습니다. 긴 LLM 질의나 데이터베이스 도구 호출이 있으면 한 요청이 몇 분 동안 대기할 수 있습니다. 출력 스키마도 단순한 float, Boolean, category보다 복잡합니다. 에이전트는 근거, 주석, 상태, 대화 흐름을 함께 보관해야 합니다.
그래서 Stripe는 처음에는 stateless synchronous inference endpoint와 비슷한 agent service를 세웠고, 현재는 stateful multi-turn conversational agent도 처리한다고 설명합니다. 더 눈에 띄는 수치는 성장 속도입니다. 이 서비스는 출시 시점의 몇 개 에이전트에서 1년 미만에 100개가 넘는 에이전트를 지원하는 내부 플랫폼으로 커졌습니다. 금융 컴플라이언스 사례 하나가 아니라 Stripe 내부 AI 플랫폼의 실행 표면이 된 셈입니다.
이 변화는 많은 AI 팀이 겪는 전환과 닮았습니다. 초기에는 에이전트를 “모델 호출 몇 번과 도구 함수 몇 개”로 볼 수 있습니다. 운영으로 가면 대기 중인 세션, 재시도, 동시 실행, 로그 보존, 권한, 비용 계측, 모델 fallback, privacy tier가 생깁니다. 기존 ML 플랫폼이 모델 파일과 배치 예측에 강했다면, 에이전트 플랫폼은 상태 있는 실행과 외부 도구 대기 시간을 다뤄야 합니다.
LLM Proxy가 Bedrock보다 앞에 놓인 이유
Stripe의 ReAct 에이전트는 Amazon Bedrock을 직접 호출하지 않습니다. 중간에 LLM Proxy microservice가 있습니다. AWS 글은 이 계층이 여러 팀의 LLM 사용량이 서로를 방해하지 않게 하고, 단일 API로 여러 foundation model에 접근하게 하며, resource constraint나 failure가 있을 때 default model fallback을 지정할 수 있게 한다고 설명합니다.
이 설계는 금융 조직에서 특히 자연스럽습니다. 한 팀이 모델 대역폭을 과도하게 쓰면 다른 위험 검토나 고객 지원 자동화가 느려질 수 있습니다. 모델을 바꿀 때마다 각 서비스가 별도 클라이언트를 고치면 governance가 깨집니다. 어떤 앱이 어떤 privacy 조건에서 어떤 모델을 썼는지 추적하지 못하면, 모델 선택은 기술 실험이 아니라 감사 구멍이 됩니다.
Amazon Bedrock은 이 Proxy 뒤의 공급 계층으로 들어갑니다. AWS 글은 Bedrock의 장점으로 표준화된 privacy와 security, 여러 foundation model 접근, prompt caching, fine-tuning, custom model serving을 듭니다. Stripe 입장에서 Bedrock의 가치는 특정 모델 하나보다 “기존 보안·프라이버시 검토 안에 여러 모델을 넣는 방식”에 있습니다. 모델이 바뀌어도 API와 운영 경계를 유지해야 하는 대형 결제사에는 이 지점이 중요합니다.
다만 이 구조는 단순하지 않습니다. LLM Proxy, agent service, review orchestrator, internal signals, human review interface가 모두 있어야 26%라는 수치가 나옵니다. Bedrock을 붙인다고 금융 검토가 자동으로 빨라지는 것이 아닙니다. 오히려 이번 사례는 모델 API보다 주변 시스템이 더 많은 일을 한다는 쪽에 가깝습니다.
자동화가 아니라 사전 조사 자동화입니다
이번 발표에서 가장 조심해서 읽어야 할 표현은 efficiency입니다. Stripe는 사람을 제거한 것이 아니라, 사람이 결론을 내리기 전의 조사 비용을 줄였습니다. AWS 글은 에이전트 응답이 supplementary information이라고 분명히 설명합니다. 인간 검토자는 각 하위 질문의 답을 최종적으로 작성해야 하며, 에이전트 응답은 그 과정을 빠르게 만드는 자료입니다.
이 차이는 금융 컴플라이언스에서 매우 큽니다. 에이전트가 최종적으로 “위험 없음”을 판정하고 거래를 통과시키는 구조라면, 실패는 곧 규제·금융 사고로 이어질 수 있습니다. 반대로 에이전트가 관련 문서, 내부 신호, 과거 자료, 후속 질문 후보를 미리 모아주고 인간이 승인한다면, 책임과 효율의 경계가 다르게 그려집니다. Stripe가 위험 허용치를 높이지 않겠다고 말한 것도 이 맥락입니다.
AWS 글의 다음 단계도 같은 방향입니다. Stripe는 현재 리뷰 시작 전에 답할 수 있는 질문에 먼저 집중했고, 남은 질문은 검토 중 인간이 확인한 upstream context를 필요로 한다고 설명합니다. 앞으로는 실시간 답변이 같은 검토의 문맥으로 들어가는 더 복잡한 multi-step investigation이 필요합니다. 26% 감소는 최종 목표가 아니라 초기 진전으로 제시됩니다.
품질 검증도 계속 인간 기준에 묶여 있습니다. Stripe는 agentic investigation component를 인간 품질 기준과 비교해 테스트하고, 실제 인간으로 검증한 뒤에야 production reviewer에게 정보를 제공한다고 설명합니다. LLM을 사용해 나쁜 접근을 빠르게 제거하는 방법도 탐색 중이지만, 이 역시 인간 기준을 대체한다기보다 평가 비용을 낮추려는 흐름입니다.
다른 기업 AI 팀이 가져갈 질문
Stripe 사례에서 바로 복제할 수 있는 부분은 많지 않습니다. Stripe는 자체 LLM Proxy, agent service, internal signals, review tooling, 컴플라이언스 전문가 조직을 갖고 있습니다. 하지만 가져갈 질문은 분명합니다. 첫째, 에이전트가 최종 행동을 하는지, 사전 조사만 하는지 구분해야 합니다. 둘째, 큰 업무를 작은 질문으로 나누고 각 질문의 품질을 따로 측정해야 합니다. 셋째, 도구 호출과 관찰과 추론의 로그가 나중에 감사 자료로 재구성될 수 있어야 합니다.
넷째, 기존 ML 플랫폼에 에이전트를 억지로 넣을지 별도 실행 서비스를 둘지 결정해야 합니다. tool calling이 많고 세션이 길며 외부 시스템 대기가 많은 업무라면, 밀리초 응답을 전제로 한 inference service와 맞지 않을 수 있습니다. 다섯째, 모델 공급자를 앱마다 직접 붙이지 말고, 비용·권한·fallback·privacy를 관리하는 접근 계층을 둘 필요가 있습니다. Stripe의 LLM Proxy는 이 문제에 대한 내부 답입니다.
여섯째, 비용은 출력 토큰 가격표만으로 계산하면 안 됩니다. ReAct 루프는 관찰을 계속 누적하고, 하위 질문마다 공통 지시문과 문맥을 반복할 수 있습니다. prompt caching, task decomposition, cost instrumentation이 같이 있어야 운영비를 예측할 수 있습니다. AWS 글이 token caching 비용 절감과 invocation별 비용 계측을 같은 문단에서 말한 이유도 여기에 있습니다.
이번 사례는 에이전트 시장의 과장된 주장과 거리가 있습니다. “완전 자율 금융 판정”이나 “규제 업무 대체”가 아니라, 검토자가 더 빨리 좋은 질문에 답하도록 돕는 운영 시스템입니다. 그래도 이 방향이 더 현실적입니다. 금융, 보안, 법무, 의료처럼 최종 판단권을 쉽게 자동화할 수 없는 영역에서 에이전트가 먼저 들어갈 자리는 판정 버튼이 아니라 조사, 근거 정리, 후속 질문, 감사 로그입니다.
Stripe가 보여준 26%는 모델 하나의 점수가 아닙니다. 작은 질문으로 분해한 검토 흐름, ReAct observation 로그, 인간 승인선, LLM Proxy, 별도 agent service, Bedrock의 모델 접근과 prompt caching이 합쳐진 운영 결과입니다. AI 팀이 이 사례에서 볼 부분도 수치 하나보다 그 조합입니다. 에이전트를 실제 업무에 넣으려면 모델보다 먼저 업무의 질문 구조와 책임 구조를 설계해야 합니다.