Krea 2 오픈 웨이트, RAW로 학습하고 Turbo로 추론
Krea가 12B 이미지 모델 Krea 2를 공개했습니다. RAW/Turbo 체크포인트, 8스텝 추론, 라이선스 경계를 개발자 관점에서 봅니다.
- 무슨 일: Krea가 Krea 2 기술보고서와 오픈 웨이트 릴리스를 공개했습니다.
- 공개 버전은 미세조정용
RAW와 빠른 추론용Turbo두 체크포인트로 나뉩니다.
- 공개 버전은 미세조정용
- 개발자 포인트:
RAW에서LoRA를 학습하고Turbo에서 실행하는 운영 경로가 전면에 섰습니다. - 주의점: 오픈 웨이트와 자유 소프트웨어는 다릅니다. 상업 이용과 재배포 조건은 Krea 라이선스를 따로 확인해야 합니다.
Krea가 6월 23일 Krea 2 Technical Report를 공개했습니다. 같은 날 오픈 버전 릴리스 페이지와 GitHub 저장소도 함께 열었습니다. 겉으로는 새 이미지 생성 모델 출시입니다. 개발자 관점에서 더 눈에 띄는 부분은 모델을 하나의 파일로 던지는 방식이 아니라, 미세조정용 RAW와 빠른 추론용 Turbo를 분리해 배포했다는 점입니다.
Krea의 설명대로라면 Krea 2 RAW는 미증류 기반 체크포인트입니다. 미세조정, 후훈련, LoRA 학습에 쓰는 쪽입니다. Krea 2 Turbo는 8스텝 증류 체크포인트입니다. 저장소 예시는 --steps 8, --cfg 0.0, --width 2048, --height 2048 설정으로 2K 이미지를 생성하는 명령을 제시합니다. 이 분리는 이미지 생성 모델을 "써 보는 모델"과 "내 제품에 맞게 다시 다듬는 모델"로 나누는 실무적 제안입니다.
좁아진 기본 미학에 대한 반응
Krea 기술보고서의 문제 제기는 명확합니다. 최근 이미지 생성 모델은 고해상도, 사실적 질감, 안정적인 구조, 이미지 안 텍스트 렌더링에서 빠르게 좋아졌습니다. 하지만 Krea는 많은 시스템이 제품 사용에 맞춘 좁은 기본 미학으로 수렴했다고 봅니다. 사용자가 원하는 것은 매번 하나의 반짝이는 기본 결과물이 아니라, 여러 스타일과 분위기, 구도 사이를 탐색할 수 있는 공간이라는 주장입니다.
이 주장은 제품 포지셔닝에 가깝지만, 모델 설계 선택과도 연결됩니다. Krea 2는 창작 탐색을 위해 넓은 스타일 분포와 제어 가능성을 같이 밀고 있습니다. 기술보고서는 간단한 프롬프트를 더 풍부한 시각 방향으로 확장하는 프롬프트 확장기와, 참고 이미지의 스타일·분위기를 주입하는 스타일 참조 시스템을 설명합니다. 단순히 모델 하나가 더 똑똑해졌다는 이야기가 아니라, 사용자의 불완전한 의도를 모델 조건 공간에 맞추는 보조 시스템을 함께 놓은 발표입니다.
Krea는 Krea 2가 Artificial Analysis 텍스트-투-이미지 리더보드 상위 10위 안에 있고 독립 랩 모델 중 2위라고 기술보고서에 적었습니다. GitHub README는 Krea 2를 Artificial Analysis 기준 독립 랩 텍스트-투-이미지 모델 1위라고 설명합니다. 리더보드 순위는 측정 시점과 평가 항목에 따라 움직이므로, 이번 글에서 더 중요한 숫자는 순위 자체보다 공개된 실행 경로입니다. Krea는 모델을 API 제품으로만 묶지 않고, 체크포인트와 추론 코드를 같이 내놨습니다.
RAW와 Turbo를 나눈 이유
이미지 모델을 제품에 넣는 팀은 보통 두 요구를 동시에 갖습니다. 하나는 빠른 추론입니다. 사용자에게 결과를 보여주는 화면에서는 지연시간과 비용이 품질만큼 중요합니다. 다른 하나는 재학습 가능성입니다. 브랜드 스타일, 상품 사진, 게임 원화, 건축 시각화처럼 특정 도메인에 맞추려면 기반 모델을 다시 다룰 수 있어야 합니다.
RAW와 Turbo 분리는 이 두 요구를 같은 체크포인트에 억지로 넣지 않습니다. Krea GitHub README는 RAW를 기반 미증류 모델로 설명하고, Turbo를 8스텝 빠른 추론용 모델로 설명합니다. 또 RAW에서 LoRA를 학습한 뒤 Turbo에 적용하는 방식을 권장합니다. 학습은 조정 여지가 큰 기반 모델에서 하고, 배포는 지연시간이 낮은 증류 모델에서 하라는 뜻입니다.
uv run inference.py "a fox walking in the snow" \
--checkpoint oss_turbo --steps 8 --cfg 0.0 --mu 1.15 --width 2048 --height 2048
이 명령은 저장소 README가 제시한 Turbo 사용 방식입니다. CFG를 끄고 8스텝으로 돌리는 경로는 빠른 서비스를 겨냥합니다. 반대로 RAW 예시는 52스텝과 --cfg 3.5를 씁니다. 같은 Krea 2라도 어떤 체크포인트를 고르느냐에 따라 "훈련 실험"과 "사용자 응답"의 비용 구조가 달라집니다.
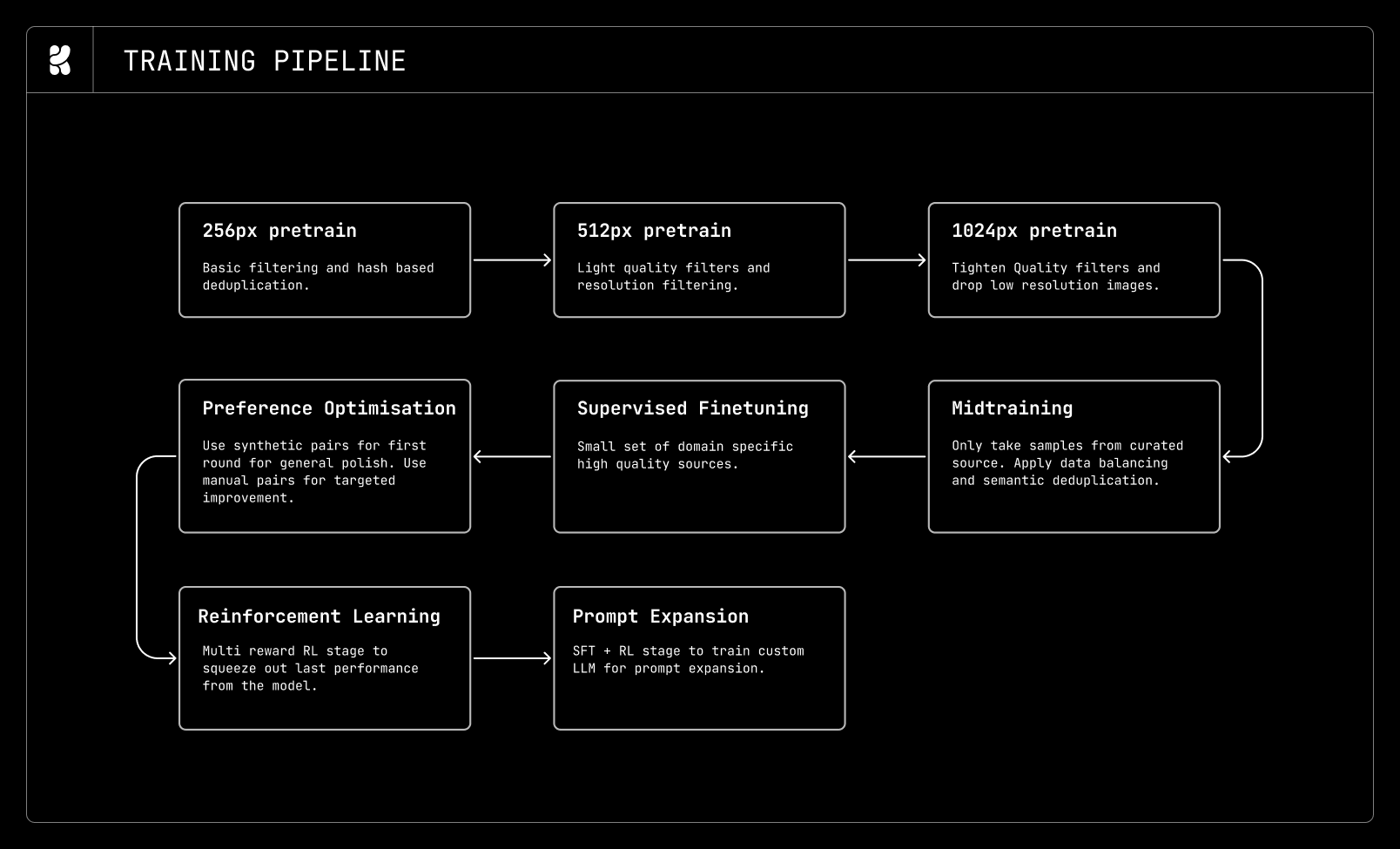
이미지 모델이 LLM 훈련 문법을 빌려온다
Krea 2 기술보고서에서 눈에 띄는 부분은 이미지 모델 설명에 LLM 훈련 문법이 자주 등장한다는 점입니다. 보고서는 사전학습, 중간학습, 지도 미세조정, 선호 최적화, 강화학습, 타임스텝 증류로 이어지는 다단계 파이프라인을 설명합니다. 구조도 단순한 확산 모델 구현 소개가 아니라, 데이터 선별과 보상 모델, 프롬프트별 평가 기준까지 포함합니다.
데이터 쪽에서 Krea는 사전학습 데이터에 AI 생성 이미지를 쓰지 않았다고 명시합니다. 이유도 단순한 원칙론이 아닙니다. 보고서는 합성 이미지가 모델 출력 분포에 편향을 넣고, 모델 품질의 상한을 만들 수 있다고 설명합니다. 그래서 자체 분류기를 만들어 AI 생성 이미지를 걸러냈다고 합니다. 이 대목은 이미지 모델 경쟁에서 데이터 출처와 필터링이 계속 제품 차별점으로 남는다는 신호입니다.
캡션 파이프라인도 별도 사건입니다. Krea는 OCR로 이미지 안 텍스트를 뽑고, 메타데이터와 함께 캡션 모델에 넣어 긴 자연어 캡션을 만든 뒤, 더 저렴한 LLM으로 여러 길이와 형식의 프롬프트로 다시 바꿉니다. 보고서는 긴 프롬프트가 더 촘촘한 감독 신호를 주지만, 실제 사용자 입력은 짧고 모호하므로 다양한 프롬프트 스타일을 학습에 섞는다고 설명합니다. 이미지 모델의 품질이 픽셀 데이터만이 아니라 텍스트 조건의 품질에 묶여 있다는 뜻입니다.
12B DiT, Qwen3-VL, 그리고 단순한 블록 설계
Krea 2 오픈소스 페이지 FAQ는 공개 모델의 구조를 Qwen Image VAE, 12B dense DiT backbone, Qwen3-VL 텍스트 인코더와 다층 특징 집계로 요약합니다. DiT는 확산 트랜스포머 계열을 가리키고, Qwen3-VL은 텍스트뿐 아니라 이미지 입력까지 다룰 수 있는 비전-언어 모델입니다. Krea가 텍스트 인코더로 일반 텍스트 모델 대신 비전-언어 모델을 택한 이유는 이미지 참조와 다국어 일반화까지 조건 공간에 넣으려는 선택으로 읽힙니다.
보고서의 아키텍처 절은 GQA, gated sigmoid attention, SwiGLU, RMSNorm, 3D axial RoPE 같은 선택지를 다룹니다. 이 이름들은 LLM 개발자에게 익숙합니다. Krea는 이미지 생성 모델에서도 이미 검증된 커널과 최적화를 활용할 수 있는 구조를 선호했다고 설명합니다. 이미지 모델 훈련이 고립된 그래픽스 연구가 아니라, LLM 인프라와 커널 생태계를 공유하는 방향으로 가고 있다는 의미입니다.
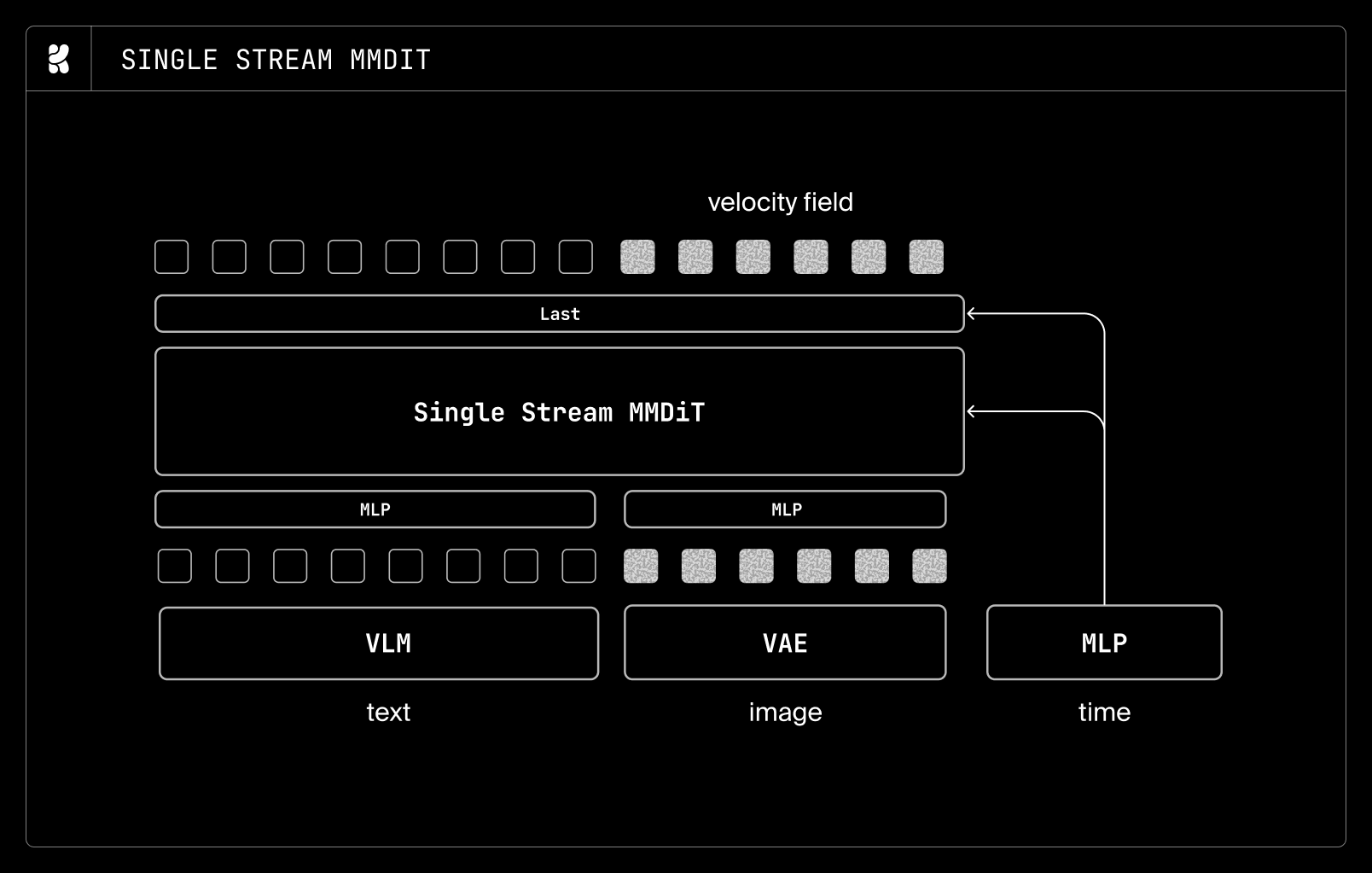
흥미로운 선택은 복잡성을 끝까지 늘리지 않았다는 점입니다. 보고서는 단일 스트림, 이중 스트림, 혼합 스트림 설계를 비교했고, 혼합 스트림이 약간 나았지만 단순성을 위해 최종 구조는 단일 스트림을 쓴다고 설명합니다. Krea가 이 결정을 공개한 이유는 모델 품질만큼 유지보수와 추론 구현의 단순함도 중요하다는 메시지로 보입니다.
개발팀에게 생기는 실제 선택지
Krea 2가 개발팀에 주는 선택지는 세 가지입니다. 첫째, Krea API를 쓰는 경로입니다. 제품팀이 자체 GPU를 운영하지 않고 이미지 생성 기능을 붙일 때 가장 빠른 방식입니다. 둘째, 오픈 웨이트를 내려받아 자체 추론을 돌리는 경로입니다. 데이터 경계, 비용 예측, 지연시간 제어가 중요한 팀은 이 경로를 검토할 수 있습니다. 셋째, RAW에서 도메인 LoRA를 학습하고 Turbo에 얹어 빠르게 서비스하는 경로입니다.
세 번째 경로가 이번 발표의 실무적 중심입니다. 예를 들어 패션 전자상거래 팀은 특정 브랜드의 조명과 룩북 구도를 반영한 LoRA를 학습할 수 있습니다. 게임 스튜디오는 캐릭터 콘셉트와 배경 스타일을 분리해 학습할 수 있습니다. 건축 시각화 팀은 내부 무드보드와 소재 표현을 맞춘 뒤, 실제 사용자 요청은 Turbo에서 빠르게 처리할 수 있습니다. 이 구조가 잘 작동한다면 오픈 웨이트 모델은 연구 데모가 아니라 제품 파이프라인의 구성요소가 됩니다.
다만 자체 운영은 무료가 아닙니다. 12B dense 이미지 모델은 작은 장난감 모델이 아닙니다. 저장소 README는 ComfyUI, Fal, SGLang 같은 실행 경로를 언급하지만, 팀마다 필요한 GPU 메모리, 배치 처리, 큐잉, 안전 필터, 저장소 비용, 관측성은 따로 계산해야 합니다. 폐쇄형 API 비용이 불편해서 오픈 웨이트로 옮겼다가, 운영 비용과 장애 대응을 새로 떠안는 경우도 충분히 생깁니다.
라이선스는 품질만큼 중요합니다
Krea는 기술보고서에서 모델 웨이트와 추론이 permissive license 아래 공개됐다고 표현합니다. GitHub README의 FAQ는 두 모델 웨이트가 Krea community license 아래에 있고, 상업 라이선스 구매는 Krea에 문의하라고 설명합니다. 따라서 이 릴리스를 "완전한 자유 소프트웨어"로 읽으면 안 됩니다. 오픈 웨이트라는 말은 가중치 접근이 가능하다는 뜻이지, 모든 사용·재배포·상업화가 조건 없이 허용된다는 뜻이 아닙니다.
개발팀은 세 가지를 확인해야 합니다. 첫째, 생성물의 상업 이용 조건입니다. 둘째, 모델을 미세조정한 파생 체크포인트를 내부·외부에 배포할 수 있는지입니다. 셋째, 고객 데이터로 학습한 LoRA와 Krea 원 웨이트가 법적으로 어떻게 분리되는지입니다. 이미지 모델은 결과물이 외부 고객에게 바로 노출되므로, 라이선스 문구를 나중에 보는 방식은 위험합니다.
데이터 투명성도 남는 질문입니다. Krea는 AI 생성 이미지를 사전학습에서 제외했다고 설명하고, 캡션·필터링·중복 제거 전략을 길게 공개했습니다. 그러나 전체 데이터셋 자체를 공개한 것은 아닙니다. 저작권, 인물권, 브랜드 이미지, 지역별 규제는 실제 제품 도입에서 계속 검토해야 합니다. 기술보고서가 자세하다는 점과 법무·보안 검토가 끝났다는 점은 같은 말이 아닙니다.
폐쇄형 이미지 제품과 다른 경쟁 축
Krea 2는 Midjourney, OpenAI, Google, Adobe 같은 폐쇄형 이미지 제품과 같은 방식으로만 경쟁하지 않습니다. 폐쇄형 제품은 앱 경험, 편집 UI, 브랜드 안전성, 워크스페이스 통합에서 강합니다. Krea 2 오픈 웨이트의 강점은 모델을 제품 내부 부품으로 가져와 조정할 수 있다는 점입니다. 이 차이는 디자이너 한 명이 웹앱에서 이미지를 뽑는 상황보다, 개발팀이 이미지 생성 기능을 자체 서비스에 넣는 상황에서 더 크게 드러납니다.
Krea가 공개한 오픈 버전은 API와 대체 관계이면서 보완 관계입니다. 많은 팀은 처음에는 API로 품질을 확인하고, 일정 규모를 넘으면 특정 도메인 LoRA와 자체 추론을 검토할 것입니다. 반대로 자체 운영을 하다가도 피크 트래픽이나 일부 고품질 요청은 API로 보내는 혼합 구조를 만들 수 있습니다. 이때 중요한 것은 모델 이름보다 라우팅 기준입니다. 어떤 요청은 빠른 Turbo, 어떤 요청은 더 긴 샘플링, 어떤 요청은 사람 검토가 필요합니다.
커뮤니티 반응도 이 지점에 모입니다. Krea 기술보고서가 직접 링크한 Hacker News 토론에서 발표자는 최신 텍스트-투-이미지 모델의 웨이트와 훈련 설명을 공개한다고 소개했습니다. 토론의 관심은 "예쁜 샘플"만이 아니라 훈련·데이터 인프라, 라이선스, 실제 실행 조건으로 이어졌습니다. 오픈 웨이트 이미지 모델은 공개되는 순간부터 사용자가 벤치마크, 프롬프트, 부정 사례, 하드웨어 비용을 다시 검증하는 대상이 됩니다.
지금 확인할 체크리스트
Krea 2를 실험하려는 팀은 먼저 목적을 나눠야 합니다. 단순한 시안 생성이면 Turbo와 API가 출발점입니다. 특정 스타일을 반복해야 한다면 RAW에서 LoRA를 학습하고 Turbo에 적용하는 경로를 검증해야 합니다. 연구팀이 보상 모델, 증류, 캡션 파이프라인을 비교하려면 RAW가 더 적합합니다.
두 번째는 품질 평가 데이터입니다. 이미지 모델 평가는 텍스트 모델보다 팀별 차이가 큽니다. 제품 사진, 인물, UI 목업, 건축, 자동차, 포스터, 한국어 텍스트 렌더링은 서로 다른 실패 양상을 가집니다. Krea 2가 리더보드에서 높은 순위를 받았다는 사실은 출발점일 뿐입니다. 팀 내부 프롬프트 100개, 실패 유형 태깅, 사람 선호 평가, 재생성 비용을 함께 봐야 실제 도입 판단이 가능합니다.
세 번째는 안전 장치입니다. 이미지 생성 제품은 저작권 스타일 모방, 유명인 얼굴, 브랜드 로고, 성적·폭력적 콘텐츠, 정치 광고 같은 위험을 다룹니다. Krea 2를 자체 운영하면 이런 필터와 정책도 자체 책임이 됩니다. 폐쇄형 API의 정책이 불편해서 오픈 웨이트로 옮기는 순간, 정책 설계와 로그 감사는 더 자유로워지는 동시에 더 무거워집니다.
Krea 2 발표가 남긴 실무적 메시지는 간단합니다. 이미지 모델의 오픈 웨이트 경쟁은 "누가 더 예쁜 샘플을 보여줬나"에서 끝나지 않습니다. 학습 가능한 기반 체크포인트, 빠른 추론 체크포인트, 라이선스, 실행 코드, 도메인 LoRA, 평가 데이터가 한 묶음으로 평가됩니다. Krea가 RAW와 Turbo를 나눠 공개한 것은 그 묶음을 제품 팀 언어로 다시 정리한 사건입니다.