The 1,000-session wall, and why agent products need analytics
Voker’s Launch HN shows how agent operations are moving beyond trace debugging toward product analytics for intents, corrections, and resolutions.

- What happened: YC S24 startup Voker launched an AI-agent product analytics platform on Launch HN.
- Its core primitives are
Intents,Corrections, andResolutions: not just what the model called, but what the user wanted and whether it was solved.
- Its core primitives are
- Why it matters: Agent operations are shifting from "which tool call happened?" to "did the user's job get done?"
- Watch: The HN thread immediately pushed on differentiation from Langfuse, LangSmith, and Amplitude, plus the reliability of intent classification and ROI at low usage.
- The hard part is not another dashboard. It is turning messy agent conversations into stable product metrics that PMs, analysts, and engineers can all trust.
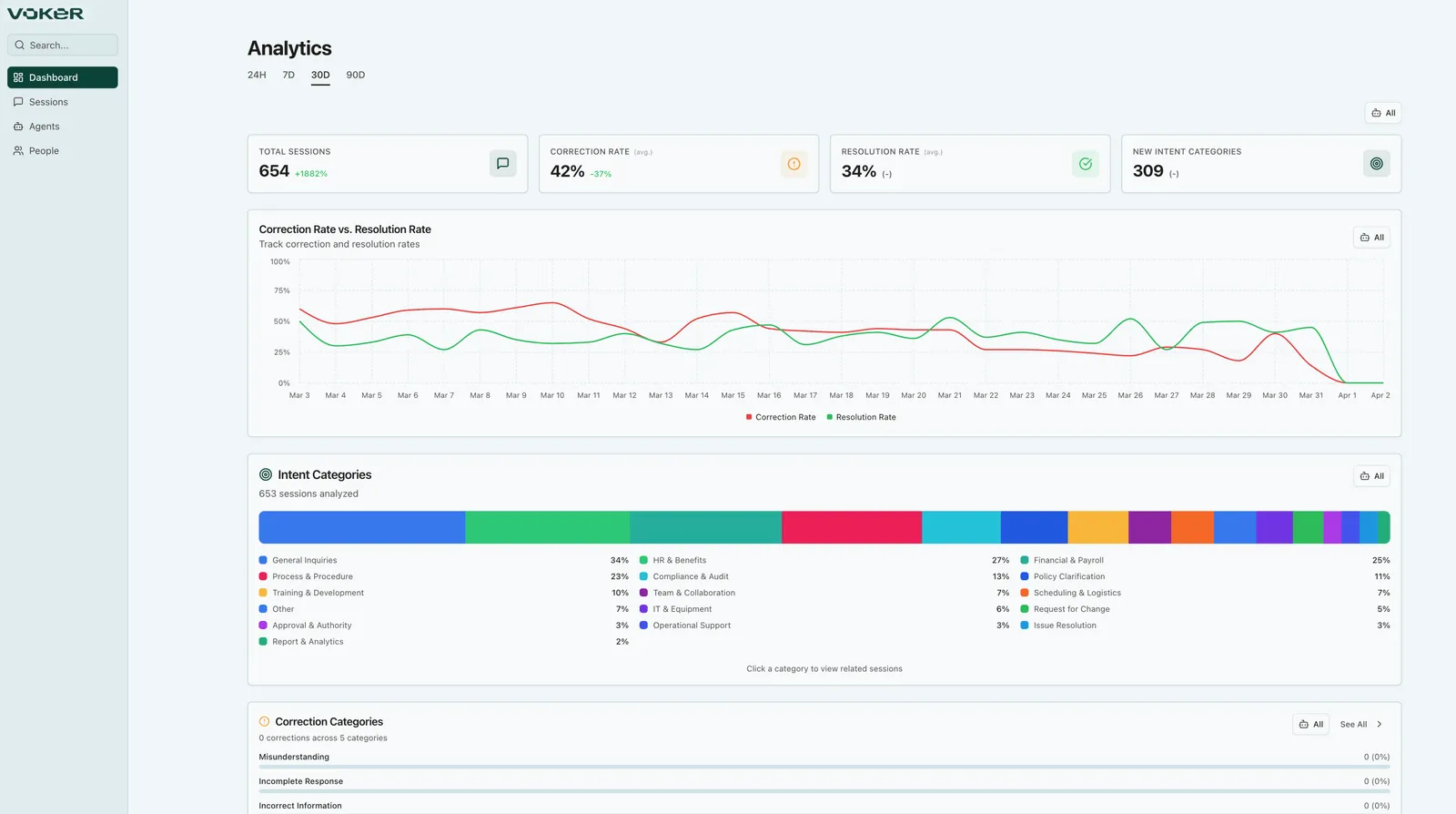
Around May 23, 2026, a small but revealing Launch HN post appeared on Hacker News: "Voker (YC S24) - Analytics for AI Agents." It was not a frontier model release, a new coding agent, or a bundle of MCP servers. Voker was pitching something quieter: an analytics layer for teams that have put AI agents in front of real users and now need to understand what is happening in production.
At first glance, that can look like another dashboard in an already crowded AI tooling market. But the launch is interesting because it exposes a bottleneck that agent builders are starting to hit. Over the past year, developers absorbed model routing, tool calling, browser control, sandboxes, MCP, permission approval, and delegated coding workflows at remarkable speed. Once those agents leave the demo and face customers, the question changes. What did the user actually ask for? Did the agent resolve it? If not, where did the experience break? Did that failure affect retention, conversion, support load, or revenue?
Voker's answer is not just a prettier trace viewer. In the Launch HN post, the founders described it as an "agent analytics platform for AI product teams." The SDK is positioned as LLM-stack neutral, with wrappers for OpenAI, Anthropic, Gemini, and related integrations. The pitch is that teams should not have to read raw logs to infer whether an agent helped users. They should be able to see what users wanted, how often they corrected the agent, and whether the work was completed.
The gap between observability and product analytics
LLM observability tools are already abundant. Langfuse describes itself as an LLM engineering platform covering traces, prompts, evaluations, and experiments. LangSmith provides tracing, evaluation, and monitoring inside the LangChain ecosystem. Datadog, Arize, Braintrust, Helicone, and others often show up in the same conversation. These tools are good at model calls, latency, token cost, retrieval steps, tool invocations, prompt versions, and error stacks.
The problem is that product teams often ask a different question. When a customer-support agent gives the wrong refund guidance, an engineer needs to inspect the failed tool call or retrieval step. A PM asks something else: how many conversations were refund-related, whether the issue repeats in a particular segment, whether a prompt change improved the resolution rate, and whether users who experienced the failure came back the next week.
Traditional product analytics only sees half of that story. It can tell whether a page was opened, a button was clicked, or a session lasted several minutes. In an agent product, a long session may be good or bad. Two minutes of conversation does not mean the user was helped. A user can restate the same request three times, give up, and still make the engagement chart look healthy.
Amplitude made a similar argument in its March 2026 Agent Analytics post. While building its own agent, Amplitude said its existing analytics stack could not easily answer whether users received useful answers after asking questions. Offline eval pass rates improved, but real customer conversations exposed different failures. Traces showed infrastructure signals, while product success and downstream business outcomes needed another layer of connection.
That is the gap Voker is targeting. A trace asks, "what happened?" An eval asks, "was this answer good under a defined rubric?" Agent analytics asks, "was the user's intent resolved, and did that change the product metric that matters?" These questions overlap, but they are not the same question.
| Layer | Primary question | Typical signals | Main users |
|---|---|---|---|
| Trace / Observability | Which calls and tool executions did the agent go through? | LLM call, latency, tokens, tool error, retrieval step | AI engineer, platform engineer |
| Eval | Did the answer or action satisfy a defined criterion? | Pass rate, judge score, regression, benchmark case | ML engineer, QA, prompt owner |
| Agent Analytics | Was the user intent resolved and tied to product outcomes? | Intent, correction, resolution, retention, conversion | PM, analyst, AI product team |
Voker's three raw primitives
The words Voker repeated in the Launch HN discussion were Intents, Corrections, and Resolutions. A user always approaches an agent with some intent. During the interaction, that user may correct the agent, reverse a misunderstanding, or add constraints that were missed. Finally, the team needs to know whether that intent was resolved. Voker treats these three signals as common analytics primitives for conversational agents.
The approach is simple, but the direction is clear. "User sent a message" is too low-level as a product event. "Assistant called a tool" is not enough either. A product team needs to know whether the user was asking to book a trip, dispute an invoice, change a delivery address, or refine a report. It also needs to know whether the user had to say "not that date" or "you misunderstood the billing period," and whether the workflow eventually reached completion.
Voker's docs point in the same direction. An event is described as a single tracked interaction for a specific agent version and person. Each LLM call or wrapped execution becomes one event. An event session groups multiple events into a conversation or workflow. Messages store user input, system prompt, and model response in order. Fingerprints capture details such as language, runtime version, SDK version, and system information so teams can diagnose reproducibility and environment differences.
The SDK integration is intentionally lightweight. The Python quick start shows pip install voker, a VOKER_API_KEY, and a provider wrapper that changes from openai import OpenAI to from voker.ai.provider_openai import OpenAI. Calls include voker_agent and voker_session. The docs also list TypeScript, OpenAI, Anthropic, Gemini, and AI SDK support.
The more important point is that Voker is not claiming LLMs should do all of the data engineering. In the HN thread, a founder said the company does not use LLMs for core event processing or statistics. Instead, it uses LLMs and hierarchical text classification for annotation and category creation, while statistical calculations run through reproducible pipelines. That is the core answer to a fair concern raised in the thread: if an LLM guesses the categories, does the whole analytics layer become garbage in, garbage out?
Why this problem is surfacing now
When an agent remains a demo, observability is manageable. If it fails, a developer can watch the run and fix the obvious issue. Once agents enter customer support, analytics assistants, coding automation, internal operations, or sales workflows, failure takes a different shape. The dangerous case is not one loud error. It is quiet, repeated failure.
Imagine a support agent that mishandles a specific refund intent. A trace can show which tool call failed in a particular session. It will not automatically tell the team whether the same intent grew over the last seven days, whether a prompt change reduced the correction rate, whether the issue only affects enterprise accounts, or whether failed sessions correlate with churn. The trace viewer is the starting point, not the conclusion.
Voker's "1,000 conversations per month" framing came up in that context. One HN commenter argued that many startups may already exceed that level, making the cutoff feel vague. Voker framed 1,000 conversations as an early estimate for the point where manual trace inspection becomes painful and recurring insight becomes necessary. The number is not a market standard. The more durable point is that the period where a team can still "just read the conversations" may end faster than expected.
Amplitude's internal example points in the same direction. Its Agent Analytics post described reviewing negative signals such as thumbs-down feedback, abandoned threads, and tool errors after offline evals began to saturate. The team then built a failure taxonomy and applied automated classification to track regressions and major error categories. Amplitude also shared internal figures including an 80% thumbs-up rate, a 90% positive signal rate, and 2.3x higher retention for users who experienced a high-quality agent session compared with users who hit task failure. Those are product-specific numbers, not universal laws. But the direction is clear: teams want to connect agent quality with business outcomes.
The questions HN asked immediately
The useful thing about Launch HN is that marketing copy does not stay protected for long. Voker's post quickly received practical questions.
The first was differentiation from Langfuse. If Langfuse already shows agentic behavior and decision traces, what is different? Voker answered that Langfuse is strong for debugging technical issues, while Voker is focused on product, business, and user outcomes. The example flow was a PM discovering a new intent category with low resolution in Voker, then an engineer using Voker and Langfuse together to identify and fix the cause.
The second question was what Voker adds for teams already using LangSmith or homegrown intent classifiers. Voker argued that "LangSmith plus internal intents" becomes hard to maintain as contributor count and agent usage grow. More dashboard requests, more data slices, too many intent categories, and self-serve needs from product and design teams can turn the internal tool into a product of its own.
The third question was classification reliability. One commenter argued that intent classification can be unstable without domain expert input. That concern is valid. If labels wobble, the insight layer wobbles too. Separating "shipping question" from "refund question" may be easy. Legal, medical, financial, and developer-support domains often need much tighter operational taxonomies. Voker mentioned hierarchical classification and customer-specific feedback adaptation, but this remains an area the product has to prove.
The fourth question was how Voker relates to Amplitude. The HN discussion referenced Amplitude's own agent analytics work. Voker drew the line by saying Amplitude is strong at web and product data analytics, while Voker specializes in tracking agent data. From a market perspective, both are converging on the same question: is an agent conversation a product event, a trace, an eval case, or all three? Whoever answers that question well may shape the default data model for agent analytics.
What changes for developers
This trend has direct consequences for developers. Code that builds agents can no longer stop at wrapping model calls. For observability and analytics, teams need consistent links among agent name, version, session, person, intent, tool result, feedback, cost, and downstream product events. A release note for an agent should move from "this prompt seems better" to "this agent version reduced the correction rate and increased the resolution rate for this intent."
First, agent versioning becomes product infrastructure. Even with the same model, a different system prompt, retrieval configuration, tool schema, safety guardrail, temperature, or model route is a different product. Voker's data model includes agent version for exactly this reason. Agent analytics should not only show global averages. It should show quality movement by version.
Second, session boundaries become a design problem. If a user mixes several intents in one chat, is that one session or several tasks? If a background agent resumes a tool execution thirty minutes later, is that the same workflow or a new event? For a coding agent, the meaningful unit might be a branch, issue, pull request, repository, or task ID rather than a person. Event, session, and person look simple on paper, but in production those boundaries determine whether the analytics are useful.
Third, privacy tiers become product requirements. Agent analytics can learn the most from prompt content, but prompt content is often the most sensitive data. Amplitude discussed content-optional analytics: a metadata-only tier can still show cost, retention segmentation, regeneration, and abandonment signals, but it limits automated failure explanation and other enrichment. Tools like Voker will face similar enterprise questions around content storage, PII redaction, retention policy, regional storage, SOC 2, and audit logs.
Fourth, the boundary between evals and analytics gets blurry. Offline evals are valuable before release because they catch regressions. Online analytics shows what happens in the real user distribution. A mature agent operations loop will probably connect the two: discover a failed production intent, promote it into an eval dataset, change the prompt or tool schema, then confirm the improvement through online resolution metrics.
The larger competition behind a small launch
Voker is still a small product. Its Launch HN post had a modest score and a limited comment count. But small launches sometimes show the direction of a larger market. In this case, the signal is not simply "agents create traces." It is that traces can accumulate and still leave product teams unsure what to fix next.
Competition can split in three directions.
The first path is observability tools moving upward. Langfuse, LangSmith, and similar tools can expand from traces and evals into product outcomes, user identity, intent clustering, and cohort analysis. Many teams already connect their trace pipelines to these tools, which gives them a strong data starting point.
The second path is product analytics tools moving inward. Companies like Amplitude already own product events and user identity graphs. They can treat agent traces as a new class of product event and connect them to retention, conversion, and revenue attribution.
The third path is agent-native tooling occupying the middle layer. Voker starts from intents, corrections, resolutions, agent versions, and session reconstruction. Its positioning is lighter than a large analytics suite and closer to product-team language than classic LLM observability.
It is too early to know which path wins. For development teams, the data model matters more than the vendor. If you are designing agent logs now, preserve fields that can survive tool changes later: agent ID, version, session ID, user or account ID, model, tool calls, retrieved-context references, user feedback, resolved status, cost, latency, and downstream event links.
The next bottleneck is a measurable product
AI agents have been impressive in demos for a long time. Real products ask a different set of questions. The user delegated a job. Did the agent finish it? If not, what kind of failure was it? How often does that failure repeat? Did the fix actually improve the experience? Did that improvement show up in return visits, conversion, cost reduction, or restored trust?
Voker's Launch HN surfaced those questions directly. The important news is not only that a new tool called Voker exists. The larger signal is that the agent operations stack is moving past models, tools, sandboxes, and traces into the language of product analytics.
For developers, that is a slightly inconvenient shift. Agents need analyzable units from the beginning. Prompt changes need to be treated like product experiments. Logs need to preserve outcomes, not just raw calls. But the shift is difficult to avoid. Once an agent does work on a user's behalf, success is measured less by tokens and calls and more by resolved intent and trust.
Whether Voker becomes the standard is still open. The skeptical HN questions are real: intent classification can be wrong, and the moment a small team needs an $80-per-month analytics tool depends heavily on the product. But the 1,000-session wall can arrive sooner than teams expect. From that point on, reading traces by hand is no longer enough. When an agent becomes a product, agent analytics becomes product analytics.