2.03x Token Throughput, EAGLE 3.1 Fixes Speculation Drift
vLLM EAGLE 3.1 targets attention drift in speculative decoding, with early gains for long-context and coding-agent serving workloads.
- What happened: The vLLM, EAGLE, and TorchSpec teams released EAGLE 3.1 and integrated it into vLLM main.
- The official announcement landed on May 26, 2026, with availability through vLLM nightly builds and the upcoming
v0.22.0path.
- The official announcement landed on May 26, 2026, with availability through vLLM nightly builds and the upcoming
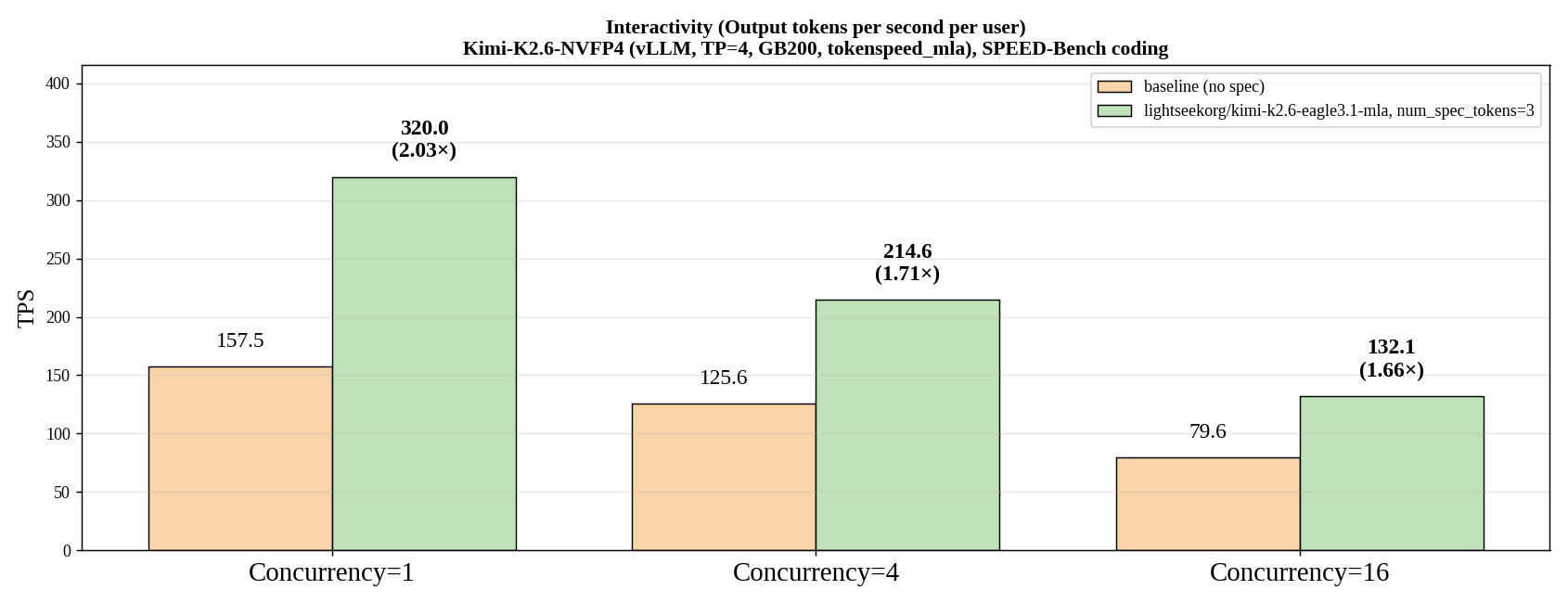
- Key number: On Kimi-K2.6-NVFP4, GB200, and SPEED-Bench coding, vLLM reports 2.03x per-user output throughput at concurrency 1.
- Why it matters: The bottleneck in speculative decoding is shifting from "attach a small drafter" to knowing when the drafter starts to drift.
- The paper calls this
attention drift, a failure mode that helps explain unstable acceptance length under long context and prompt-template perturbation.
- The paper calls this
- Watch: These are early results under specific model, hardware, and benchmark conditions. Production teams still need to test prompt format, batching, quantization, and fallback policy.
The EAGLE 3.1 announcement on the vLLM blog looks modest from a distance. It is not a new frontier model, not a consumer app, and not a glossy interface launch. For teams that actually serve LLM products, however, it is a useful signal. The inference bottleneck is moving downward from "which model should we use?" toward "how do we verify and move tokens through the serving stack?"
The release comes from the EAGLE Team, vLLM Team, and TorchSpec Team. On May 26, 2026, the teams introduced EAGLE 3.1 as an update aimed at making speculative decoding more stable and deployable. vLLM says support has already been merged into the main branch, with access expected through nightly releases and the upcoming v0.22.0 route. A draft model for Kimi-K2.6-NVFP4, lightseekorg/kimi-k2.6-eagle3.1-mla, is also available on Hugging Face.
The headline number is clear. In vLLM's announcement, EAGLE 3.1 reaches 2.03x per-user output throughput over a no-spec baseline at concurrency 1 on Kimi-K2.6-NVFP4, tensor parallel size 4, GB200, non-disaggregated serving, and the SPEED-Bench coding dataset. The speedup remains 1.71x at concurrency 4 and 1.66x at concurrency 16. That matters because large agent workloads are not only about a single user's fastest response. They also need to survive multiple concurrent sessions running long tool loops.
The promise and operating reality of speculative decoding
Speculative decoding is usually summarized as "a smaller model guesses first, then a larger model verifies quickly." While the target model would otherwise generate one token at a time, a smaller drafter produces several future-token candidates. The target model then checks those candidates in parallel. If the guesses are accepted, several tokens advance at once. If they are rejected, generation falls back to the target model's normal path. In theory, the output distribution of the target model is preserved while latency drops.
That is why speculative decoding has appeared so often in model and runtime announcements over the past year. Google has talked about MTP drafters for Gemma 4. NVIDIA has discussed diffusion-style drafting and self-speculation in the Nemotron family. Runtime projects such as vLLM, SGLang, TensorRT-LLM, llama.cpp, and others are all absorbing different combinations of draft models, verification paths, KV cache management, and batching. The important change is that speculative decoding is no longer just a research acceleration idea. It is becoming a serving-stack configuration surface.
The operating reality is more demanding. Speculative decoding only helps when the drafter is right often enough. For easy sentence completion, acceptance length can be long. Under long context, complex system prompts, tool calls, coding benchmarks, or mixed chat templates, the drafter's predictions can wobble. It is true that the target model still verifies candidates, so quality should be preserved in the narrow algorithmic sense. But if the acceptance rate collapses, the speed benefit disappears. In the worst case, the system pays the cost of running the smaller model without receiving enough accepted tokens in return.
EAGLE 3.1 is interesting because it names this failure mode directly. The arXiv paper submitted on May 11, 2026, "Attention Drift: What Autoregressive Speculative Decoding Models Learn," describes a pattern where, as a speculative chain gets deeper, the drafter moves attention away from the prompt and sink tokens toward the tokens it just generated itself. The paper calls this attention drift and says it is observed not only in EAGLE3 drafters, but also in MTP heads. That makes it look less like a bug in one implementation and more like a structural instability in autoregressive drafter design.
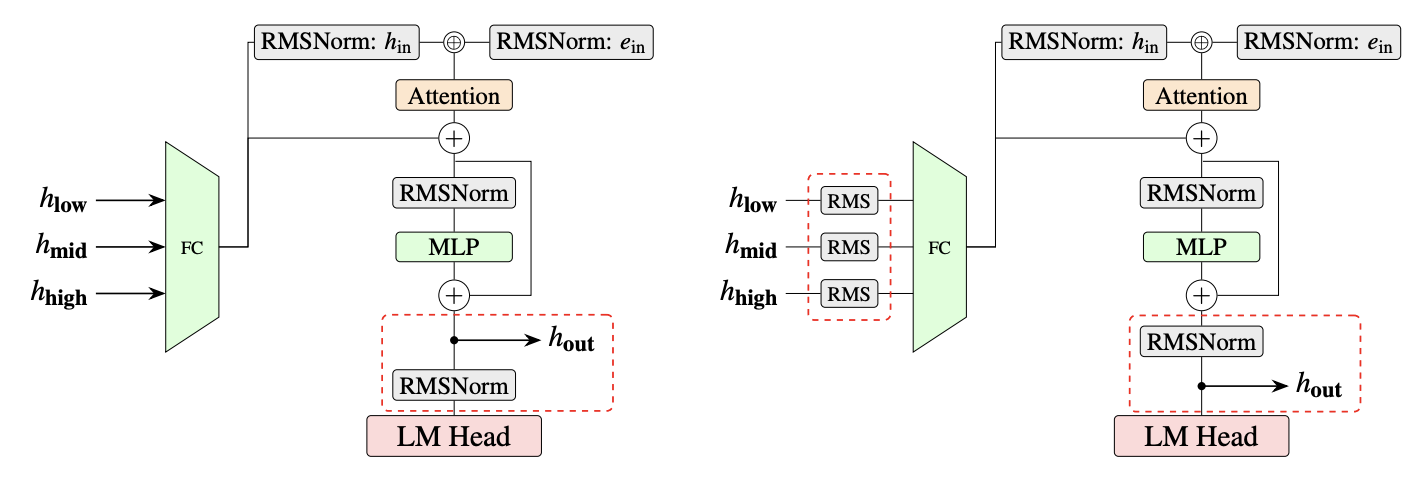
EAGLE 3.1 changes a small but low-level part of the path
The core changes described in the vLLM announcement are compact. First, EAGLE 3.1 applies FC normalization after receiving the target hidden state and before feeding it into the FC layer. Second, it feeds the post-norm hidden state into the next decoding step. This reads like a small neural-network block adjustment, but the target is specific: as speculation depth increases, hidden-state magnitude can grow, and an unnormalized residual path can make the drafter behave as if more layers are being stacked on top of the target model.
The official post explains the design as moving closer to recursively calling the drafter at every decoding step rather than simply appending layers to the target model. That distinction matters because the goal is not only to create a smarter small model. The goal is to make the existing drafter architecture less fragile when prompt formats change, context length grows, or system instructions shift.
The paper's abstract supports that framing. The authors report up to 2x acceptance-length improvement over pre-norm EAGLE3 under template perturbation, 1.18x on long-context tasks, and 1.10x across seven benchmarks including multi-turn chat, math, and coding. The 2.03x throughput figure in the vLLM blog is an early operating-data point for how those algorithmic improvements can appear inside a real serving engine.
Integration into vLLM is the news
In AI infrastructure, the deployment path can be as important as the paper result. EAGLE 3.1 enters vLLM as a config-driven extension of the existing EAGLE 3 implementation. According to the announcement, the integration includes FC normalization support, post-norm hidden-state feedback, and removal of hardcoded assumptions around target hidden states. It also keeps backward compatibility with existing EAGLE 3 checkpoints.
That is a practical detail, not a footnote. Adding a new decoding algorithm to an inference runtime is not the same as downloading a model file. Tokenizers, chat templates, target hidden states, KV cache layout, tensor parallelism, attention backends, quantization, and tool-call parsers all interact. Even the example command in the announcement combines options such as --tool-call-parser kimi_k2, --enable-auto-tool-choice, --reasoning-parser kimi_k2, --attention-backend tokenspeed_mla, and --speculative-config. For teams serving coding agents or tool-using models, speculative decoding is no longer a single "generate tokens faster" switch. It is an execution path that must be checked alongside tool-call parsing, reasoning format, and attention backend behavior.
The Hugging Face model card for lightseekorg/kimi-k2.6-eagle3.1-mla tells the same story. The draft model is an EAGLE3 draft model for Kimi-K2.6-NVFP4, improved over kimi-k2.6-eagle3-mla through fc_norm and norm_output. It has 3B parameters and uses BF16 tensors. The model card includes benchmark tables for acceptance length across GSM8K, CEval, HumanEval, MATH500, AIME24, MTBench, and SPEED-Bench slices. Not every row moves in the same direction. HumanEval, MATH500, and AIME24 show small drops, while CEval and SPEED-Bench multilingual or math slices improve. That is a useful warning: EAGLE 3.1 is not a universal "turn it on everywhere" instruction. Teams still need to inspect acceptance profiles by workload.
Why this matters more for agent workloads
EAGLE 3.1 matters beyond ordinary latency tuning because agent workloads have changed shape. Older chatbot requests often had shorter prompts and shorter answers. Current coding agents, research agents, and enterprise assistants accumulate repository context, tool results, system instructions, policy text, and user corrections across a session. Prompt templates may change inside the same session. Tool outputs are inserted between messages. Long context is becoming the default operating condition rather than an exception.
Under those conditions, guessing the next few tokens becomes harder. A coding agent moves between natural-language explanation, source code, JSON, shell commands, stack traces, and test output. The drafter may achieve long acceptance length in plain English and then suddenly lose it at a code diff or tool-call boundary. As the agent loop grows, repeated system prompts and tool schemas also make KV cache and prefix-cache behavior more important. Model quality, runtime batching, cache policy, and speculative decoding start acting as one combined system.
That is why the phrase attention drift is useful. When performance falls short, teams do not have to stop at "the drafter is too small" or "the benchmark is different." They can examine where attention moves as speculation depth increases. In production, that means measuring acceptance length, per-user throughput, time per output token, time to first token, GPU utilization, and fallback ratio together. EAGLE 3.1 is an algorithm-and-runtime collaboration aimed most directly at acceptance length and throughput, but the operational lesson is broader: speculative decoding needs observability, not just a flag.
For tool-using agents, the risk profile is also different from ordinary chat. A partial JSON object, malformed tool call, or boundary error can cost more than a slower token stream. The target model's verification step protects the token distribution at the decoding level, but product systems still need to watch parser behavior, sampling choices, quantization effects, timeouts, and streaming interruptions. Fast tokens are only useful when the surrounding execution path remains correct.
Runtime competition is accelerating below the model layer
Another notable part of the release is the open-source collaboration pattern. The EAGLE team advances the algorithm and paper. TorchSpec provides training support. vLLM absorbs the production-serving path. This pattern is becoming familiar in the open-model ecosystem. Model providers publish checkpoints. Hugging Face provides distribution surfaces. Runtime projects such as vLLM and SGLang make those checkpoints usable under real traffic. A strong model is no longer sufficient by itself. Teams also need a good model card, a realistic serving command, runtime integration, and a rollback or fallback story.
The competitive map is splitting across that layer. EAGLE 3.1 sits next to MTP heads, Medusa, self-speculation, diffusion-style drafting, and related acceleration strategies. vLLM competes with SGLang, TensorRT-LLM, TGI, llama.cpp, Ollama, and other serving routes. TorchSpec's role is to make drafter training more repeatable. Kimi-K2.6-NVFP4 provides a target model connected to the NVIDIA and LightSeek ecosystem through Hugging Face.
For AI developers, the release raises two practical questions. First, is the bottleneck in the product the model choice, the decoding path, cache behavior, concurrency, or some interaction among all of them? Second, when a new acceleration feature is enabled, how will quality be verified? Speculative decoding can preserve the target model distribution in theory, but the product path includes chat templates, structured outputs, tool-call parsing, fallback behavior, and production timeouts. Those are the surfaces that will decide whether a throughput gain survives contact with real users.
These are still early numbers
The caveats are clear. The 2.03x number in the vLLM blog comes from a specific benchmark setup: Kimi-K2.6-NVFP4, TP=4, GB200, non-disaggregated serving, and SPEED-Bench coding. Results can change outside that combination. The Hugging Face acceptance-length table also mixes gains and small regressions across benchmarks. The paper's "up to 2x" result under template perturbation should not be read as a guarantee for every long-context production request.
The right adoption pattern is closer to a feature flag. Teams should replay representative traffic in staging on nightly builds or after the v0.22.0 release path is available. They should split metrics by prompt template, acceptance length, tool-call success rate, streaming interruption, GPU memory, and throughput at different batch sizes. A coding-agent team should go beyond short function benchmarks such as HumanEval and measure real repository tasks, test repair, lint fixes, and multi-file edits where latency and failure rate are both visible.
Even with those limits, the announcement is meaningful. EAGLE 3.1 is not a story about a new LLM getting smarter. It is lower-level infrastructure news. Serving the same target model more stably, quickly, and predictably now requires looking at the drafter's hidden state and attention drift. As agents spend more time thinking, calling tools, and carrying long context, these small interventions can change the cost curve.
The core of EAGLE 3.1 is not only the 2.03x figure. It is the path that produced it: a paper defining the failure mode, TorchSpec adding training support, vLLM opening the runtime path in main, and Hugging Face hosting a usable draft model. While model competition continues, the substrate that moves tokens quickly and reliably is evolving at the same pace. The next bottleneck for an AI team may not be the model name on the API call, but the way that model guesses and verifies every token.